2021 BDCI 华为零售商品识别竞赛一等奖方案分享

【GiantPandaCV导语】上学期快结束的时候参加了华为和CCF组织的零售商品识别的比赛,队伍名称为GiantPandaCV队,比赛大约持续了两个月,期间从开始摸索MindSpore框架,配置环境,上手ModelArts花费了不少功夫。现在比赛终于告一段落,本文进行一下复盘。
背景
CCF大数据与计算智能大赛(CCF Big Data & Computing Intelligence Contest,简称CCF BDCI)由中国计算机学会于2013年创办。大赛由国家自然科学基金委员会指导,是大数据与人工智能领域的算法、应用和系统大型挑战赛事。大赛面向重点行业和应用领域征集需求,以前沿技术与行业应用问题为导向,以促进行业发展及产业升级为目标,以众智、众包的方式,汇聚海内外产学研用多方智慧,为社会发现和培养了大量高质量数据人才。
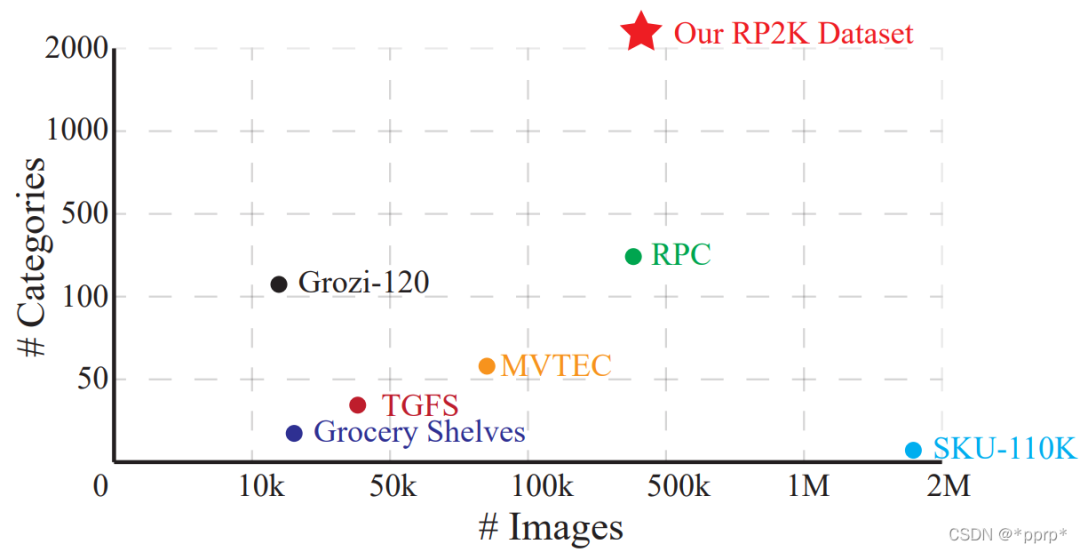
本赛题识别对象是零售商品,使用的数据集是RP2K数据集,RP2K是品览基于零售商品识别能力发布的零售数据集。不同于一般聚焦新产品的数据集,RP2K收录了超过50万张零售商品货架图片,商品种类超过2000种,该数据集是目前零售类数据集中产品种类数量TOP1,同时所有图片均来自于真实场景下的人工采集,针对每种商品,我们提供了十分详细的注释。
RP2K数据集(https://arxiv.org/pdf/2006.12634.pdf)具有以下特性:
(1) 迄今为止,就产品类别而言,它是规模最大的数据集。
(2) 所有图片均在实体零售店人工拍摄,自然采光,符合实际应用场景。
(3) 为每个对象提供了丰富的注释,包括大小、形状和味道/气味。
数据分析
数据集中的一些样本如下图所示,大部分分布是细长的,长宽分布要比ImageNet等数据集更加分布不均匀:

此外,该数据集的数据量和类别数量也非常多,下图展示了RP2K和其他零售数据集的对比,RP2K具有2388个类别的零售商品,属于大规模分类问题。
此外,数据集某一些类间分布差异较小,相同品牌不同子产品之间差异较小,可以归属为细粒度分类问题。数据质量也存在一定的问题,比如光照,包装差异,拍摄角度,标注错误等等问题。

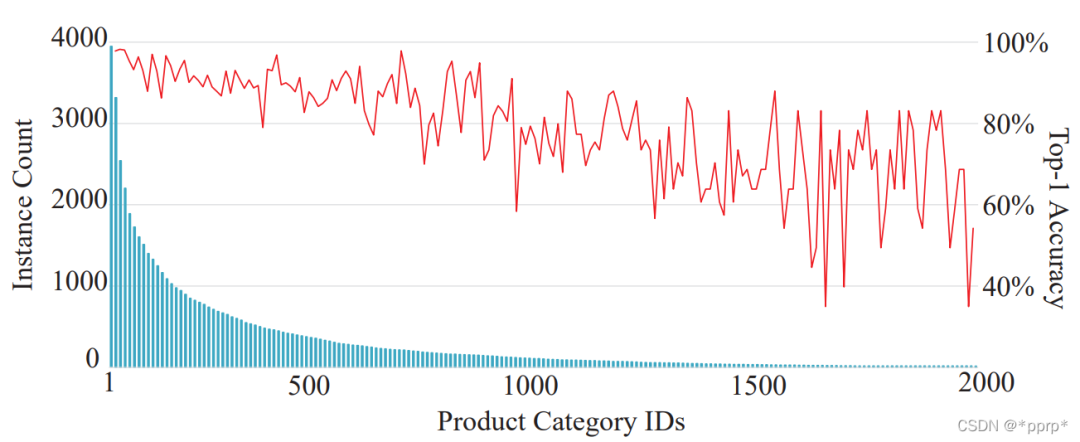
经过统计,该数据集呈现明显的长尾分布:
数据预处理
1. Resize策略
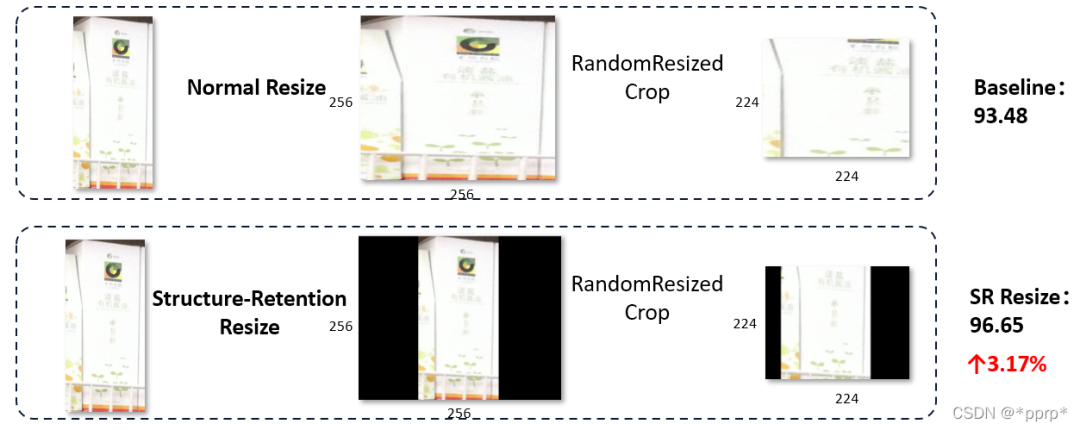
Structure-Retention Resize策略,保留原有的结构化信息。性能上能够提升3个百分点,如下图所示,也就是padding黑边的方式。这个策略在比赛初期是最有效的策略,比传统的resize方法能够提高3.17个百分点。
2. 数据增强
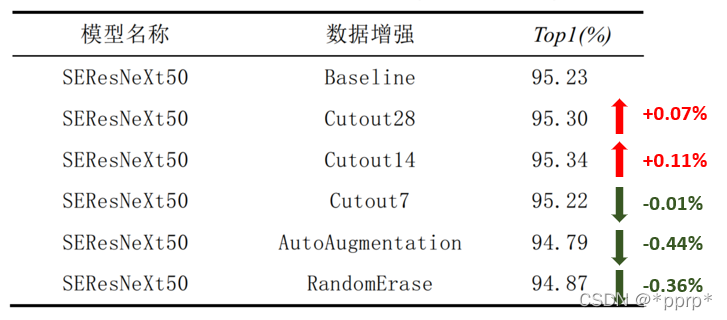
我们测试了三种经典的数据增强方法:
- Cutout数据增强策略,在随机位置Crop正方形Patch。
- AutoAugmentation策略,使用了针对ImageNet搜索得到的策略。
- Random Erasing策略,随机擦除原图中的一个矩形区域,将区域内部像素值替换为随机值。
实验效果如下:
3 后处理方法FixRes
采用了NIPS19年Facebook提出的FixRes的后处理技巧,ImageNet上经典的数据增强方式会导致训练时和测试时的模型看到的目标尺寸出现差异。
之前写过一篇文章解读FixRes详细内容可以看这里:
xxx
https://blog.csdn.net/DD_PP_JJ/article/details/121202386?spm=1001.2014.3001.5501
简单来说是由于ImageNet经典的数据处理方法会导致Region of Classification,即模型看到的目标尺寸不同。
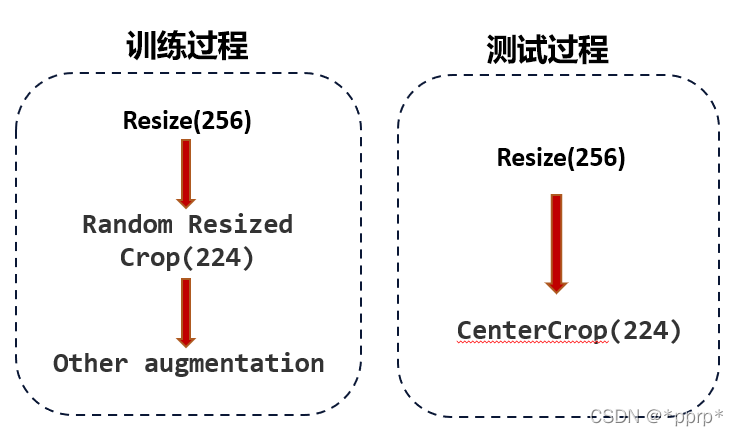
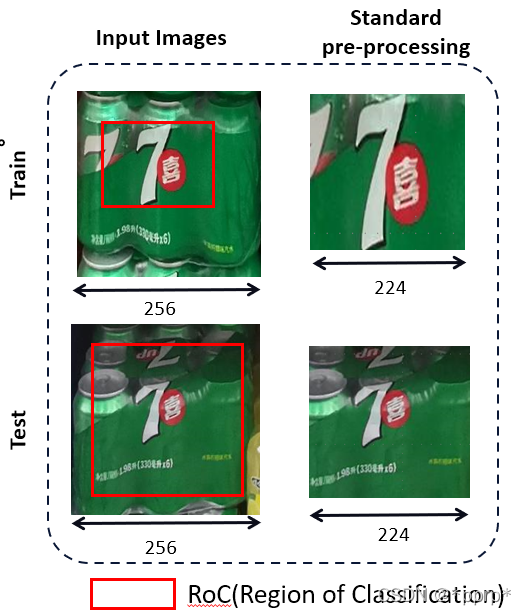
可以看到,下图中通过训练和测试过程得到的“7喜”的logo标志大小存在差异,为了弥补两者差异,最简单的方式是提高测试过程中分辨率。
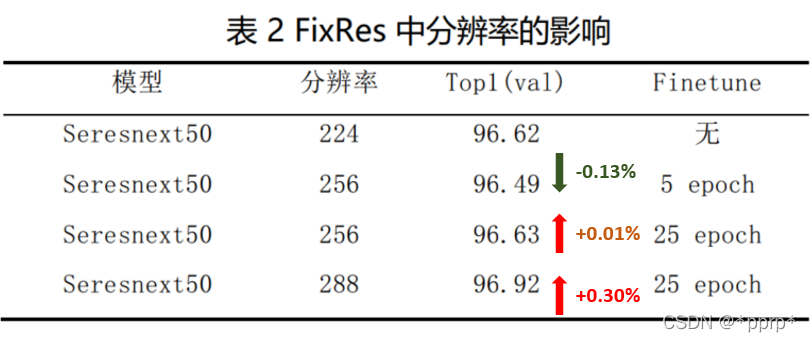
FixRes有三步流程:
- 第一步,正常以224分辨率进行训练
- 第二步,将测试分辨率调高到280
- 第三步,固定backbone,只对Linear层进行finetune。
具体实验结果如下:
模型改进
1 模型选择
由于数据集规模比较大,为了快速测试各个模型的有效性,使用了50%的数据进行快速验证,验证选择的模型包括:
- ResNet50_BAM
- ResNet50
- ResNet101
- ResNet_CBAM
- SEResNet50
- Swin Transformer
- EfficientNet
- SEResNeXt50
- Inception_resnet_v2
我们最终选择了SEResNeXt50作为主要模型,并配合ResNet50_CBAM还有Inception_resNet_v2进行模型集成。Swin Transformer和EfficientNet两个模型由于其运行速度太慢,在比赛时间限制下没有使用两者。
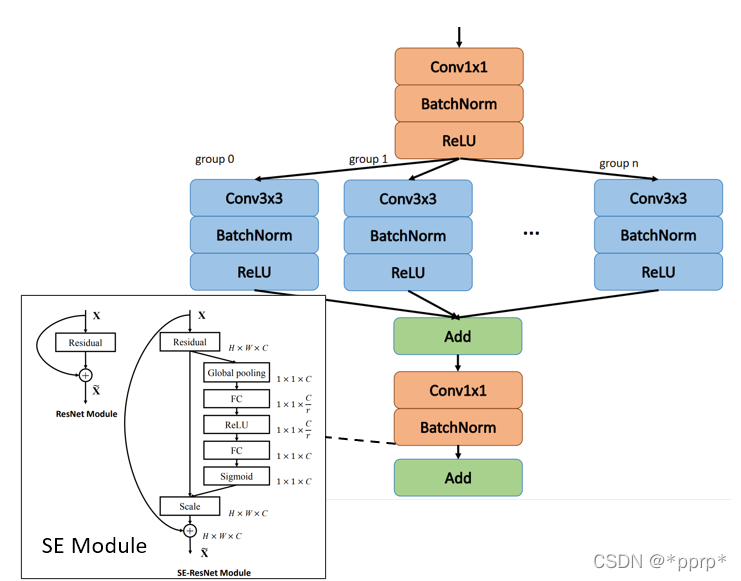
SEResNeXt模型由两部分构成
- ResNeXt在ResNet基础上引入了基数, 通过引入组卷积让模型能够学到更diverse的表示。
- Squeeze & Excitation Module让模型能够自适应地调整各个通道的重要程度,学习到了通道之间的相关性,提升模型表达能力。
2 模型改进
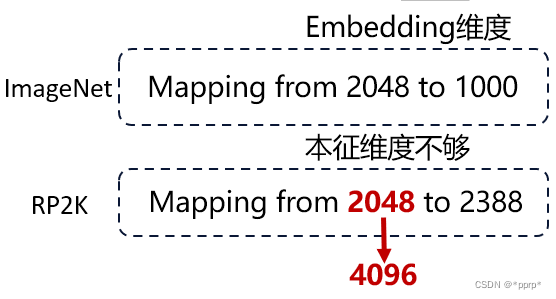
模型改进部分是一个简单而符合直觉的方法,我们观察到,现有的大部分模型都是针对ImageNet进行设计的,而ImageNet类别数为1000个类别,但RP2K数据集规模比较大,拥有2388个类别。

我们关注大多数模型的最后一个linear层的设计,针对ImageNet设计的模型的Linear层通常由2048维度映射到1000维度,由高纬度映射到低纬度比较合理。
但是由于RP2K的规模较大,类别数量为2388,直接由2048映射至2388可能会导致容量不够的问题,由低纬度映射映射至高纬度则不太符合直觉。
针对此,我们进行了简单而符合直觉的改进,如下图所示:
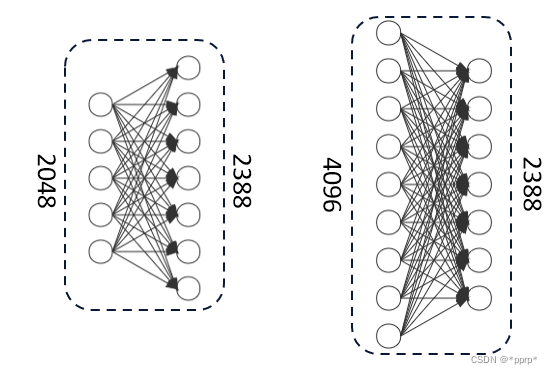
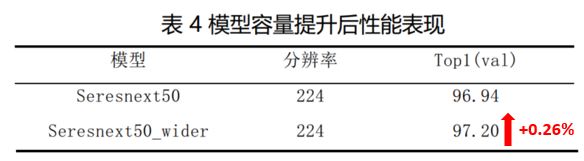
通过以上改进,扩充了模型的容量,取得了0.26%的提升。
3. 模型训练细节
使用label smooth来降低过拟合,更好地处理难分样本。
优化器使用SGD init lr=0.1
调度器: Cosine Annealing mini lr=1e-6
Batch Size: 128 Epoch: 75
混合精度:GPU O2 Ascend O3
模型集成:(本次比赛不允许集成,但是这里也展示了一下集成的效果)
SEResNeXt50(96.94)+ResNet50BAM(97.24%)+Inception_resnet_v2(96.35%) + TTA(HorionFlip) = 97.49% top1
错例分析
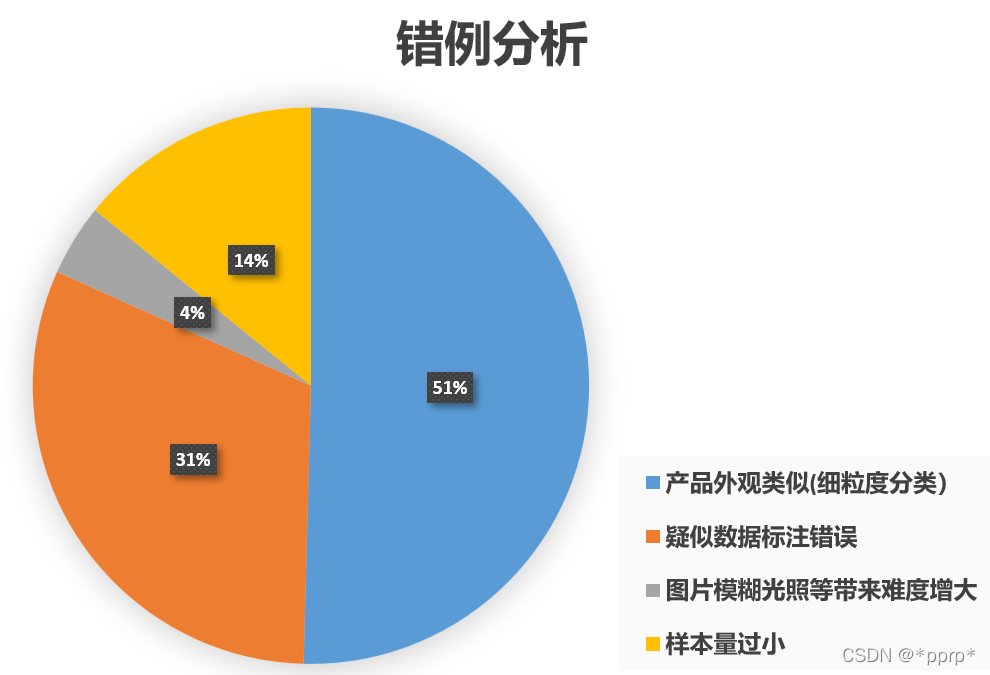
在林臻帮助下,手工分析了一下错误样例(注:以上分析去除了others类别错分样本),可以发现这个数据集比较难处理的是细粒度带来的识别困难、疑似数据标注错误、以及长尾分布的尾部类别,这也符合我们数据分析的结论。
MindSpore框架使用感受
本次比赛面向国产AI框架,基于MindSpore开发商品识别算法,必须在昇腾910平台训练和部署模型,以官方复现结果为准。
使用MindSpore的感受:
优点:
最大的优点,与昇腾平台兼容好,训练效率比较高。我们这边没有昇腾平台,大部分实验在GPU上跑的,后期进行验证的过程中发现,GPU上运行速度要远低于昇腾平台运行速度(同一套代码,唯一区别可能是O2与O3的区别),大概速度上能快接近一倍。
支持动态图和静态图,动态图方面进行调试,静态图运行效率更高。
社群友好,加入了MindSpore高校网络调试联盟,其中负责复现Swin Transformer的作者@项靖阳等人的指点,在我们遇到一些坑的过程中能快速跳出来。
快速开发,在拥有Pytorch经验的基础上,转到MindSpore之后结合API查询,可以比较快上手。
数据预处理部分与PyTorch不同的是,MS提供了c_transforms和py_transforms,经过实测c_transforms在数据处理速度上要比py_transforms快非常多,如果没有特殊需要,还是建议使用c_transforms。
缺点:说几个开发过程中缺点
- 预训练模型不太友好,个人感觉model zoo支持模型比较少,甚至有一部分数量的权重是基于CIFAR10训练的,并没有ImageNet训练的模型,如果需要用的话还需要将PyTorch的权重转换过来才能使用。
- 动态图运行效率非常低,这个坑浪费了我几乎一天的时间,调试的过程中忘记将动态图转化为静态图了,然后发现运行时间翻倍,仔细一看GPU利用率非常低,仔细排查以后发现使用的是动态图。由此看来MS的动态图支持(GPU上的)效率不是很高,我们转化为静态图之后瞬间利用率高了很多。
- 封装过程略深,官方推荐的运行方式其实更接近于Keras,构建callbacks来完成训练过程的处理。(当然官方也支持像PyTorch那种展开的写法)
最后对MindSpore感兴趣的小伙伴可以使用以下的参考资料快速上手:
MindSpore 安装问题:https://www.mindspore.cn/install
最直接的学习资料,官方教程: https://www.mindspore.cn/tutorials/zh-CN/r1.5/index.html
最简单的分类例程:https://www.mindspore.cn/docs/programming_guide/zh-CN/master/quick_start/quick_video.html
可白嫖的模型模型库:https://gitee.com/mindspore/models
开源代码
GiantPandaCV队比赛的全部源码已经开源,收集了非常多的模型,欢迎尝试MindSpore框架。
Github地址:https://github.com/pprp/GoodsRecognition.MindSpore
Gitee地址:https://gitee.com/pprp/GoodsRecognition.MindSpore