
python爬虫学习教程|爬取百度首页的热搜榜


简单爬虫
学了那么久的python,肯定得爬点东西才能对得起它 哈哈,向爬电影,小说网上也有很多例子~
不过我对对自己的要求比较低,哈哈哈 愣是从茫茫页面中找找到这么一个结构简单,清晰,而且你我都很熟悉的一个网页~
当当当当当~,爬取的页面如下:

没错,今天咱们就通过 python3 来简单爬取百度首页的热搜榜信息~
百度地址:www.baidu.com/
思路
当然,你除了要掌握一点点 python 之外,还要知道网页的结构~
毕竟,爬虫就是爬取我们网页上的东西,然后再做根据你的设定去模拟用户点击按钮,触发网页的一些事件,达成这个自动化操作的一个过程。
那么,来解析下这个百度首页吧~
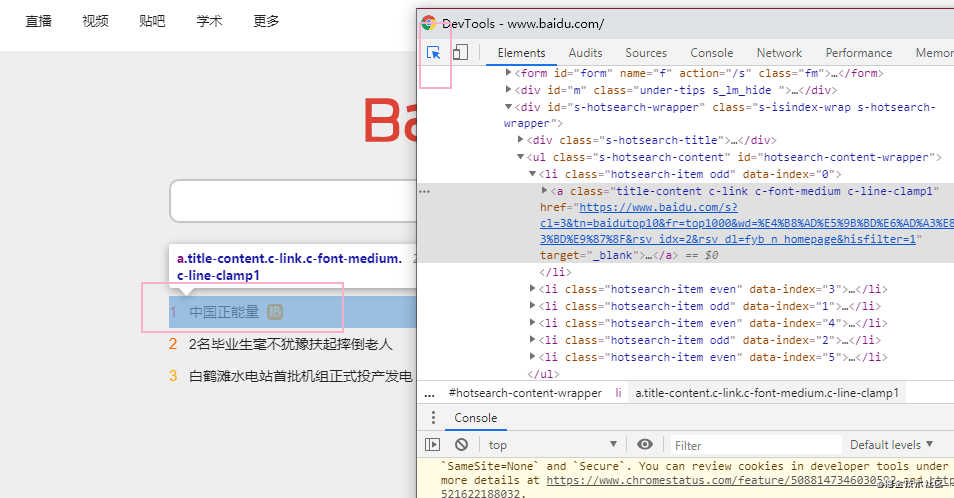
如图,通过浏览器的 F12 调出控制台,然后定位到这个 “中国正能量”
可以发现他们都在这个 li 标签中,而且 css 的 class 都是 hotsearch-item odd 或者 hotsearch-item even ,那么我们找到这些元素后,通过 getText 方法就可以获取 标签中的文字信息,接着再对他们进行个排序,打印出来即可,便完成了我们此次爬取的任务了~
代码如下:
# -*- coding: utf-8 -*-# @Time : 2020/10/9 15:44# @Author : ryzeyangimport requestsfrom bs4 import BeautifulSoupfrom datetime import datetimeheaders = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36 "}response = requests.get("https://www.baidu.com/", headers=headers)# 解析bsObj = BeautifulSoup(response.text)# 获取 response header时间resDate = response.headers.get('Date')print(resDate)# 找到热搜榜nameList = bsObj.findAll("li", {"class": {"hotsearch-item odd", "hotsearch-item even"}})# 添加热搜榜的内容tests = []for name in nameList:tests.append(name.getText())# 排序tests.sort()for news in tests:news = news[0:1] + " : " + news[1:]print(news)
打印出的结果如下:
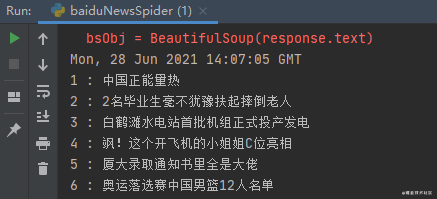
顺利完成任务~
搜索下方加老师微信
老师微信号:XTUOL1988【切记备注:学习Python】
领取Python web开发,Python爬虫,Python数据分析,人工智能等精品学习课程。带你从零基础系统性的学好Python!
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权
评论