
爬虫实战!Python多线程爬取网易云热歌音乐
多线程爬取网易云热歌音乐
前言
学习了蚂蚁老师的《零基础学Python简单爬虫》后我进步很大,开始自己实践爬取酷狗音乐,网易云音乐等各大音乐网站。在我成功的爬取了网易云热歌榜所有音乐后,我开始思考如何才能更快的爬取数据。蚂蚁老师的《python并发编程,用多线程加速程序运行》课程解决了我的问题,现在爬取速度快了十倍!!!
1.网站分析
首先大家打开网易云网站的主页,然后点击排行榜,再点击云音乐特色榜中的热歌榜。(https://music.163.com/#/discover/toplist?id=3778678)大家按F12进入开发者模式,用开发者工具搜索《孤勇者》,点击搜索结果找到网页源代码中的歌曲ID和歌曲名称。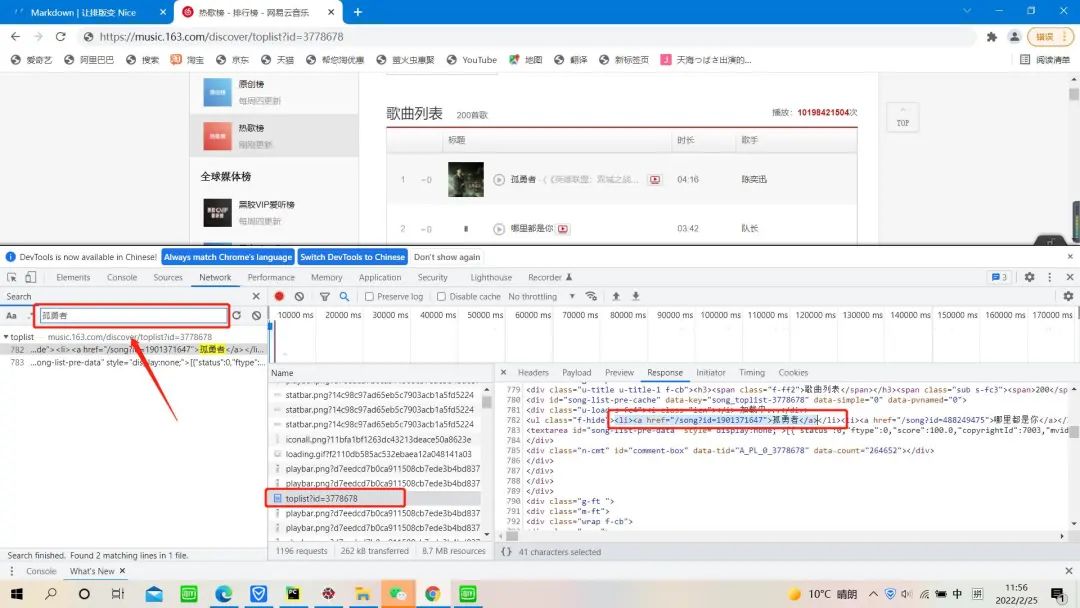
2.导入python库
import os
import requests
import re
import threading
3.发送网络请求,访问网站
#网易云网址,以热歌榜单链接为例
url = "https://music.163.com/discover/toplist?id=3779629"
headers = {
'Cookie':'_iuqxldmzr_=32; _ntes_nnid=ae3b5b26314cae4ba35657b357d06348,1640060772701; _ntes_nuid=ae3b5b26314cae4ba35657b357d06348; NMTID=00OFTzvJD26ltfT4kPLk7b6nPCn51oAAAF92z1lmg; WNMCID=xyhddx.1640060773918.01.0; WEVNSM=1.0.0; WM_TID=i2DIsKQNGhZAUABUFBIq86abC%2BMqTYA3; JSESSIONID-WYYY=w0%5CqDCxwTCSuV6TSo71m4xqKq7x9%2F%2FhSWX04%5Ce%5CEREabbI%5CDvvCOFCt6GMD9UUeC2tamR6NwUGM9X9h%2Bmugrqq5u92NSN2hoycyrjb5ldDxE8cPwGcey7bDQvNynG6230m3Saux4JblnRBF%2BchXEp7%2FRNT96%5CHUEk%5CG3geohb6jo6q5p%3A1645762943177; WM_NI=PH%2BSXDfhBlYnm2%2BWub53aGvl0VFZ%2BjlmccwSVtT5KsJUNj33VSMU7BuSHREMe3IPpsTymGnW7W3G4xmYipYo786C8z5c2UE8Mpsu8vBVsbVBmnkWmD69VHJ2XXacu5rNZG8%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eea8eb3abae9979bf37b98b48fa6d85a879f9aaff821a9b2e5b3d8749bbfc0d7ce2af0fea7c3b92a9498e5b4db50a6b88e8ddc66afeee5b8f86af7edafa8f568f48a8abbaa62b0b3ad84f65996ac9cd6ca798a8b828bb239968d83b6b64ab78d88b3c847a7ed87b1f37998a7a3a8ed5df589fda8b774af87a791dc65f5e8faa4bb72f7bdfeb6c8348fb0bd96bb7e828abd83d54aafb2a5b8f050f6e79aa9c93a9c88af84f83fb29296a8bb37e2a3',
'Referer':'https://music.163.com/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36',
}
r = requests.get(url)
4.解析歌曲ID、歌名
正则匹配网易云歌曲ID、歌曲名字
#孤勇者
zip_data = re.findall('(.*?)
print(zip_data) #打印查看
 上图我们可以看到,zip_data是一个大列表,其中每个元素都是一个元组,每个元组包含了歌曲ID和歌名。
上图我们可以看到,zip_data是一个大列表,其中每个元素都是一个元组,每个元组包含了歌曲ID和歌名。
5.爬取音乐函数
def craw(music_url,music_name):
music_data = requests.get(music_url, timeout=30).content
#新建一个music文件夹
if not os.path.exists('./music'):
os.mkdir('./music')
#保存数据
with open(f"./music/{music_name}.mp3", 'wb') as f:
f.write(music_data)
6.创建多线程,准备批量爬取
threads = []
for data in zip_data:
music_id = data[0]
music_name = data[1]
print(music_name)
music_url = "http://music.163.com/song/media/outer/url?id=" + music_id
print(music_url)
threads.append(threading.Thread(target = craw,args = (music_url,music_name)))
music_url由一个音乐下载接口和音乐ID拼接而成。我们可以打印出待爬取的url和歌名如下图所示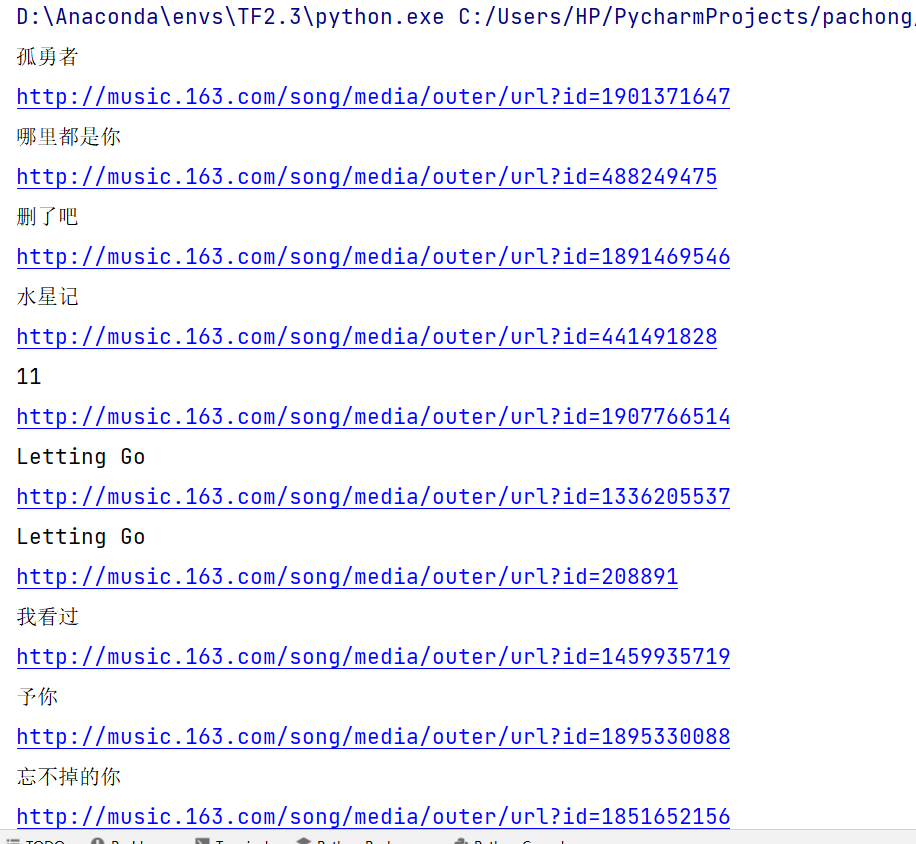
7.启动多线程
for thread in threads:
thread.start()
8.等待结束
for thread in threads:
thread.join()
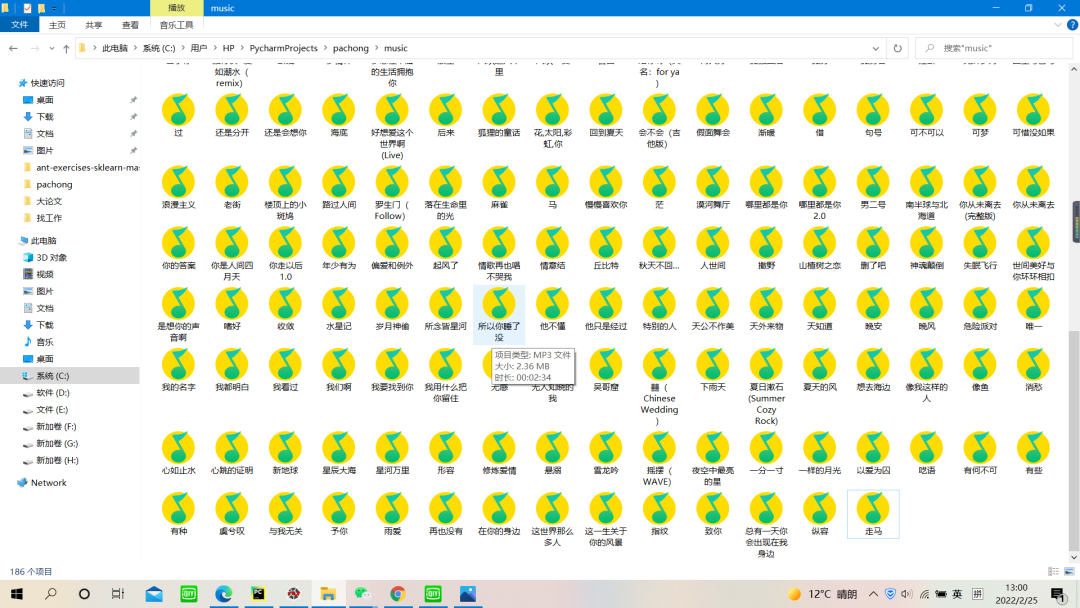 下载好热歌榜所有的音乐之后,大家可以快乐的一边听音乐,一边敲代码了,哈哈哈~
下载好热歌榜所有的音乐之后,大家可以快乐的一边听音乐,一边敲代码了,哈哈哈~
推荐蚂蚁老师的全套Python课程
先保存图片,然后抖音打开扫码购买,提供代码、课件、答疑服务

评论