
一行代码爬取微博热搜
↑↑↑关注后"星标"简说Python
人人都可以简单入门Python、爬虫、数据分析 简说Python推荐 来源:简说Python 编辑:老表
作者:老表
一、前言
二、专栏概要
三、直接来:爬取微博热搜数据
3.1 找到数据源,页面分析
3.2 一行代码爬取微博热搜
3.3 爬虫初学者看这里,爬虫入门模板教程如何爬去微博热搜
一、前言
大家好,我是老表,今天的分享来满足读者的需求,想读“关于数据库sql或者MySQL的,就那种Python来处理数据库,比如Python爬虫爬到数据,然后封存到数据库里面,然后再从sql里面读取,进行分析可视化”。

后面写文章一方面是自己学习笔记,另外也会针对读者需求写一些专题文章,如果你有自己的想法,欢迎浏览器访问下方链接,或者点击阅读原文,给博主提意见:
https://shimo.im/forms/pVQRXG6gWyqPxCTY/fill?channel=wechat
二、专栏概要
直接来:一行代码爬取微博热搜数据 做准备:将爬取到的数据存入csv和mysql、其他数据库 搞事情:读取mysql数据并进行数据分析与可视化 进阶活:将可视化数据结果呈现到web页面(大屏可视化) 悄悄话:项目总结与思考,期待你的来稿
三、直接来:爬取微博热搜数据
3.1 找到数据源,页面分析
 首先我们直接浏览器搜索
首先我们直接浏览器搜索微博热搜,就可以很快的找到微博热搜的在线页面,地址如下:
https://s.weibo.com/top/summary/
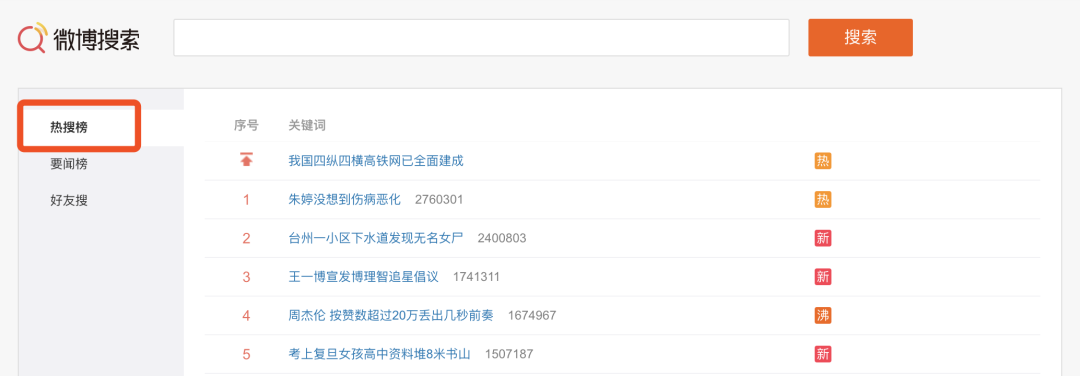 我们要爬取的热搜榜数据,包括了如下列表中的四个字段。
我们要爬取的热搜榜数据,包括了如下列表中的四个字段。
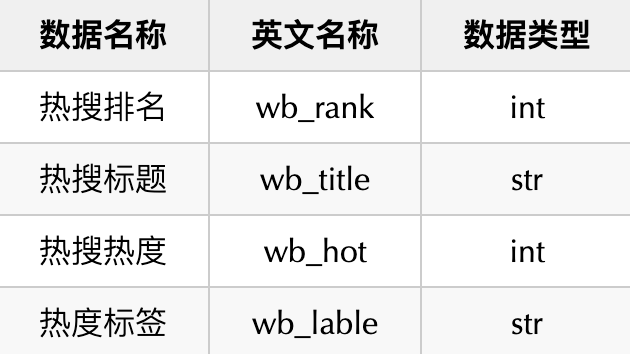
话不多说,看到数据在页面,按住F12调出浏览器开发者工具(推荐使用谷歌浏览器),然后点击network,刷新页面,在加载出来的页面中找到summary,发现这个请求返回来的是页面中的数据,里面是html代码(数据也在里面)。 然后点击
然后点击Headers,可以看出请求的url就是我们浏览器里输入的链接,没有其他接口,所以,接下来就简单了。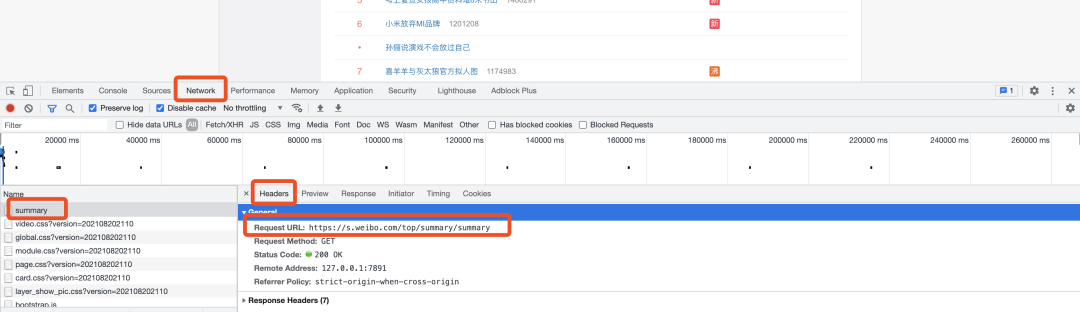
(本文相关全部源码,可以在文末获取下载地址)
3.2 一行代码爬取微博热搜
接下来说下简单的数据获取方式,只需一行代码即可,如果硬是要算,最多就是两行。
import pandas as pd
pd.read_html('https://s.weibo.com/top/summary/summary', index_col=0)[0]

(做这个项目的时候我是先用的后一种方式爬取的数据)中间分析xpath路径的时候突然发现,这页面上tr、td不是表格吗,页面上的表格爬取,在数据分析从零开始实战 | 基础篇(四)中有详细介绍,直接使用pandas的read_html函数即可,于是就有了上面一行代码爬取到微博热搜的想法了。
当然,我们会发现爬取的数据还是有点问题,虽然已经是DataFrame数据格式了,但是热搜标题和热搜热度由于在一个td里,所以爬取的时候也是给放到了一列中,着实有点尴尬。
不过没关系,我们处理下,可以利用正则将标题和热度分成两列即可。
首先对数据进行简单处理,设置下列名和删除推荐热搜(热搜排名为'•')和置顶热搜(热搜排名为nan)。
# 重新设置表头
wb_hot_data.columns = ['wb_rank', 'wb_title_hot', 'wb_lable']
# 简单处理数据,去除推荐热搜和置顶热搜
wb_hot_data = wb_hot_data.drop(wb_hot_data[(wb_hot_data['wb_rank']=='•') | pd.isna(wb_hot_data['wb_rank'])].index)
 使用正则表达式提取数据,将热搜标题和热搜热度分成两列
使用正则表达式提取数据,将热搜标题和热搜热度分成两列
import re
def reg_str(wb_title_hot='迪丽热巴玩泡泡机 293536'):
data = re.match('(.*?) (\d+)', wb_title_hot)
if data:
return data[1],data[2]
else:
return None,None
# apply函数应用
wb_title_hots = wb_hot_data.apply(lambda x: reg_str(x['wb_title_hot']),axis=1)
# 列表推倒式将热搜标题和热搜热度值分别赋值给两个新列
wb_hot_data['wb_title'] = [wb_title_hots[i][0] for i in wb_title_hots.index]
wb_hot_data['wb_hot'] = [int(wb_title_hots[i][1]) for i in wb_title_hots.index]
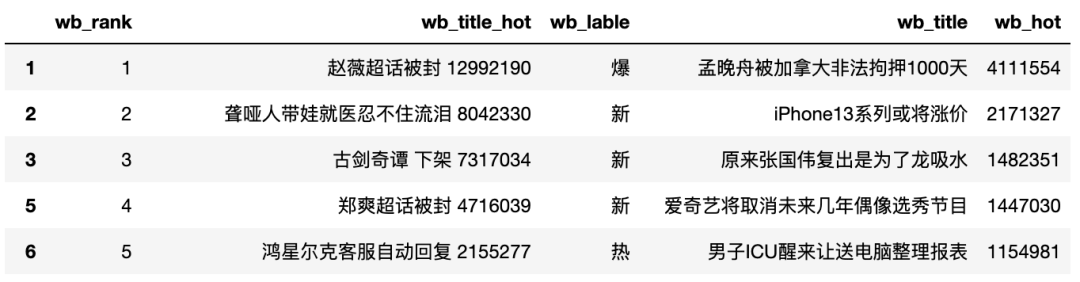 这样数据基本就解决好啦~整体来看,还是会比后一种方法更简单,如果你是爬虫初学者,我建议你可以仔细看下接下来的一种数据爬取、解析方法。
这样数据基本就解决好啦~整体来看,还是会比后一种方法更简单,如果你是爬虫初学者,我建议你可以仔细看下接下来的一种数据爬取、解析方法。
3.3 爬虫初学者看这里,爬虫入门模板教程如何爬去微博热搜
直接无脑套入爬虫模板:
# 爬虫基础库,需要提前pip install requests 安装
import requests
# html文本解析库,将文本内容解析成html,方便使用xpath方式提取数据
from lxml import etree
def get_respones_data(wb_url = 'https://s.weibo.com/top/summary/'):
'''
参数:wb_url 字符串 要请求的url,默认:https://s.weibo.com/top/summary/
返回:get_data,a 元组 第一个元素为请求得到的页面文本数据(可以后期使用正则表达式提取数据) 第二个元素为将get_data文本内容解析成html后的内容,方便使用xpath方式提取数据
'''
headers={
'Host': 's.weibo.com',
'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
}
# requests 发送请求
get_response = requests.get(wb_url,headers=headers)
# 将返回的响应码转换成文本(整个网页)
get_data = get_response.text
# 解析页面
a = etree.HTML(get_data)
return get_data,a
# 调用函数,获取到数据
get_data,first_a = get_respones_data()
觉得这种方法比较麻烦的,可以跳过本部分,后面会介绍一种特别简单的数据获取方式(后面才想到的,之所以先记录这种麻烦方法,也是想让大家学习下这种方法,后面数据爬取中会比较常见)。
接下来,我们就开始从爬取到的数据中提取我们需要的数据啦!
3.3.1 热搜标题
首先在热搜页面,按住F12,调出开发者工具,点击开发者工具左上角的select an element...,然后选中自己想提取的数据,如下图中的热搜标题。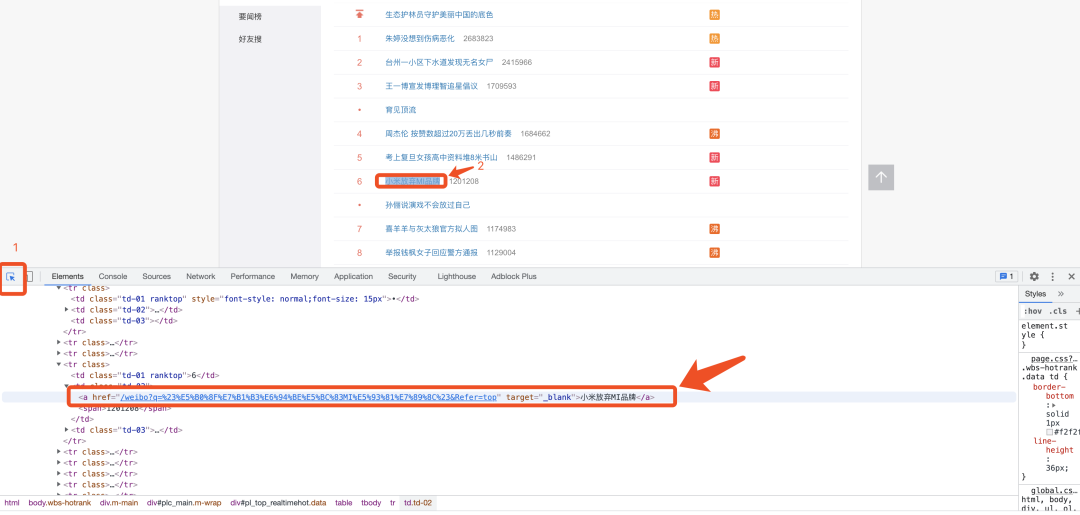 选中并点击下热搜标题,这是时候会回归正常模式(非选择元素模式),如下图,鼠标移动到被选中的html代码上,然后右键,选择Copy-> Copy Xpath,就可以轻松的获取到标题对应的xpath路径啦。
选中并点击下热搜标题,这是时候会回归正常模式(非选择元素模式),如下图,鼠标移动到被选中的html代码上,然后右键,选择Copy-> Copy Xpath,就可以轻松的获取到标题对应的xpath路径啦。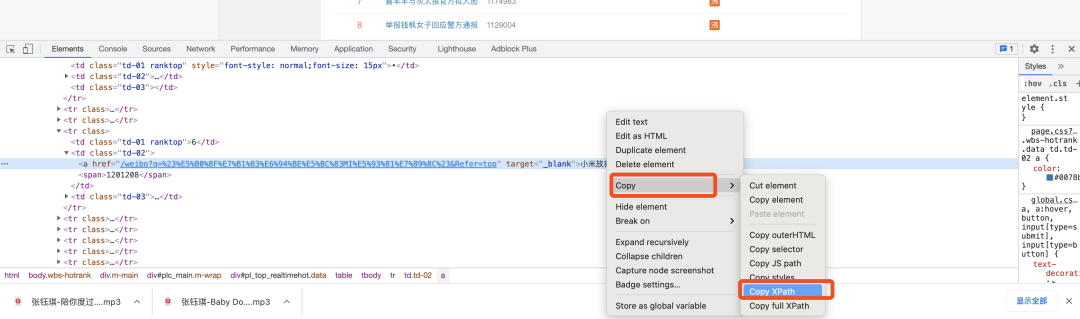 例如:
例如:
//*[@id="pl_top_realtimehot"]/table/tbody/tr[2]/td[2]/a
获取到数据对应的xpath路径后,我们就可以调用lxml中的xpath函数进行数据提取啦,如下代码,输出结果为一个列表,列表里的元素就是我们的热搜标题。
这里需要注意的是,我们是获取a标签内的文本内容,所以需要在获取的xpath路径后在加上\text(),同样的,如果有需要我们还可以获取标签内的元素对应的值,如热搜对应的链接。
# 热搜标题
print(first_a.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr[2]/td[2]/a/text()'))
'''
输出:['小米放弃MI品牌']
'''
获取到一条数据后,我们就要开始想获取页面所有标题数据啦,方法也很简单,我们按照上面的方法,在随便获取一个热搜标题的xpath路径,然后对比一下,取相同就可以了。
如下代码所示,我们发现两个xpath路径只有tr这一级不同,所以将tr后的[2]去掉即可。
'''
对比找出通用xpath路径
//*[@id="pl_top_realtimehot"]/table/tbody/tr[2]/td[2]/a
//*[@id="pl_top_realtimehot"]/table/tbody/tr[4]/td[2]/a
'''
# 通用
wb_titles = first_a.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[2]/a/text()')
print(len(wb_titles))
print(wb_titles)
 看输出数据,我们会发现数据总数对不上,页面上的热搜明明只有50条,为什么我们跑出来的数据有53条?有隐藏数据被我们爬出来了?
看输出数据,我们会发现数据总数对不上,页面上的热搜明明只有50条,为什么我们跑出来的数据有53条?有隐藏数据被我们爬出来了?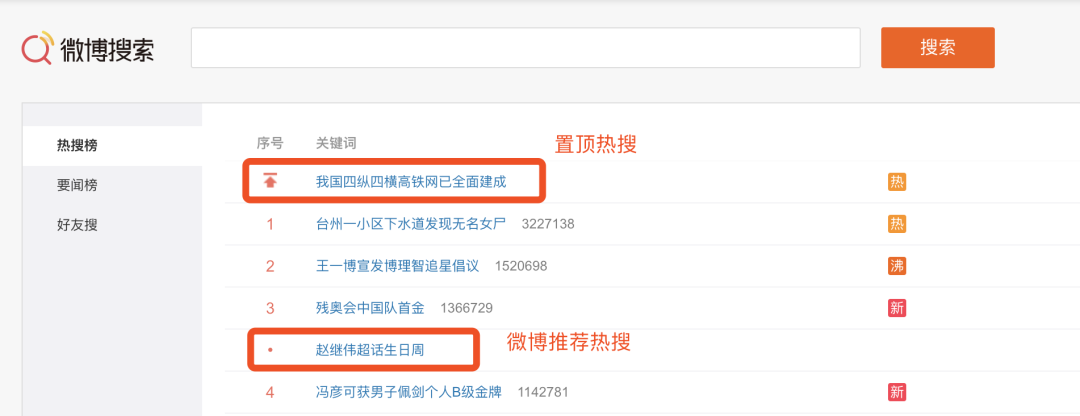 当然不是,出现这种情况是因为微博有一个置顶热搜(暂且这么称呼),另外还会有1-3个微博推荐热搜(暂且这么称呼),这两种数据只有标题属性,没有其他如:排行、热度、标签等属性,分析的时候需要剔除。
当然不是,出现这种情况是因为微博有一个置顶热搜(暂且这么称呼),另外还会有1-3个微博推荐热搜(暂且这么称呼),这两种数据只有标题属性,没有其他如:排行、热度、标签等属性,分析的时候需要剔除。
按上面的方法,我们可以依次获取到热搜热度、热搜排名、热度标签。
3.3.2 热搜热度
# 热搜热度
print(first_a.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr[2]/td[2]/span/text()'))
# 输出:['2866232']
'''
对比找出通用xpath路径
//*[@id="pl_top_realtimehot"]/table/tbody/tr[2]/td[2]/span
//*[@id="pl_top_realtimehot"]/table/tbody/tr[4]/td[2]/span
'''
# 通用
wb_hot = first_a.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[2]/span/text()')
print(len(wb_hot))
print(wb_hot)

3.3.3 热搜排名
# 热搜排名
'''
对比找出通用xpath路径
//*[@id="pl_top_realtimehot"]/table/tbody/tr[10]/td[1]
//*[@id="pl_top_realtimehot"]/table/tbody/tr[7]/td[1]
'''
# 通用
wb_rank = first_a.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[1]/text()')
print(len(wb_rank))
print(wb_rank)

3.3.4 热度标签
# 热度标签
'''
对比找出通用xpath路径
//*[@id="pl_top_realtimehot"]/table/tbody/tr[4]/td[3]/i
//*[@id="pl_top_realtimehot"]/table/tbody/tr[7]/td[3]/i
'''
# 通用
wb_lable = first_a.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[3]/i/text()')
print(len(wb_lable))
print(wb_lable)

这样每个部分的数据都获取到了,但是我们需要将每个热搜的数据连接起来,现在由于里面会有置顶热搜和微博推荐热搜,所以有些数据没法直接连接起来,比如热搜标题和热度标签。
当然,办法肯定是有的,前面分析、复制xpath的时候,我们已经发现每个xpath只有tr[n]中的n不同,所以写个循环变动n即可,这样每次获取每条热搜对应的相关数据即可。
新问题来了,n是多少呢?显然n不会是个定值(微博推荐热搜条数不定),我们再仔细观察页面,可以发现不管是微博热搜、置顶热搜还是推荐热搜,标题都是有的,所以我们看标题数即可。如下代码。
# 通用
wb_titles = first_a.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[2]/a/text()')
n = len(wb_titles)
wb_hot_data = []
# 提取数据
def get_element(data_list):
if data_list:
return data_list[0]
else:
return None
# 遍历循环
for i in range(n):
wb_rank = first_a.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr[%d]/td[1]/text()'%(i+1))
wb_titles = first_a.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr[%d]/td[2]/a/text()'%(i+1))
wb_hot = first_a.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr[%d]/td[2]/span/text()'%(i+1))
wb_lable = first_a.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr[%d]/td[3]/i/text()'%(i+1))
wb_hot_data.append([get_element(wb_rank), get_element(wb_titles), get_element(wb_hot), get_element(wb_lable)])
# 将列表数据转换成DataFrame格式数据,方便后续分析
wb_hot_data = pd.DataFrame(wb_hot_data, columns=['wb_rank', 'wb_title', 'wb_hot', 'wb_lable'])
wb_hot_data
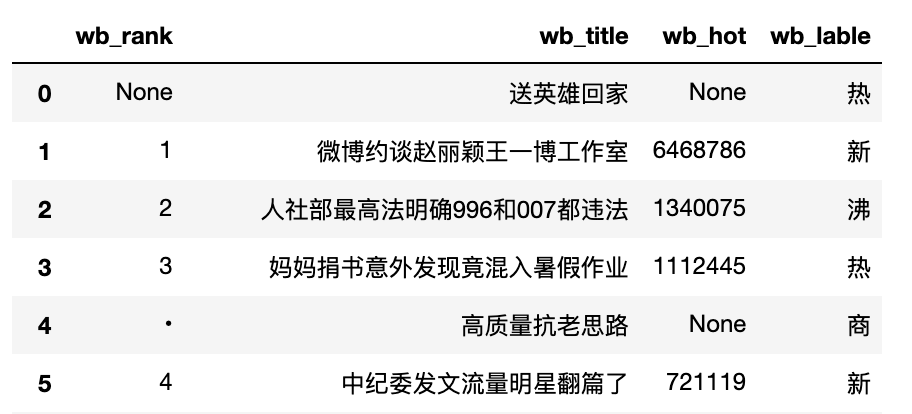
以上,相对完整且简洁的给大家说明白了一个简单爬虫的基本思路与行进路径,希望对初学爬虫的读者朋友有帮助,觉得还不错,记得点个赞哦。
下一讲中,我们将一起学习如何将爬取下来的数据存储到本地csv文件,或者数据库中(如:mysql,mongodb,sqlite等),关于数据存储这一节,你还想学习什么其他的内容也可以在评论区、留言区进行留言。
公众号简说Python学习交流群已开放,想加入进行学习交流的读者朋友,可以扫下方二维码添加老表微信,回复:进群,获取进群邀请链接。
扫码即可加我微信
观看朋友圈,获取最新学习资源
学习更多: 整理了我开始分享学习笔记到现在超过250篇优质文章,涵盖数据分析、爬虫、机器学习等方面,别再说不知道该从哪开始,实战哪里找了 点击阅读原文,反馈你的建议;“点赞、留言”就是对我最大的支持!