
ECV 2021 冠军方案解读:占道经营识别方案

极市导读
本文为获得占道经营识别冠军的威富团队方案解读,团队选用了基于YOLOv5的one-stage检测框架,最后达到了104.3FPS >>加入极市CV技术交流群,走在计算机视觉的最前沿
我们参加了反光衣识别、驾驶员不良驾驶识别、船只数量检测、机动车识别、占道经营检测和电动车进电梯检测,下面以占道经营为例介绍整个情况。
团队介绍
团队来自深圳市威富视界有限公司&中国科学院半导体研究所高速电路与神经网络实验室,成员分别为宁欣、石园、荣倩倩,排名不分先后。

ECV 2021极市计算机视觉开发者榜单大赛介绍
ECV-2021将聚集于计算机视觉领域的前言科技与应用创新,全面升级赛制,设立超百万奖金,旨在汇聚全球AI人才解决AI产业实际问题,促进人才技术交流,提升开发者人才的算法开发到落地应用的工程化能力,推动计算机视觉算法人才的专业工程化能力认证。
ECV-2021将采取多赛题并行的竞赛形式,围绕智慧城市、交通、安防、城管、海洋、银行等实际业务场景设置八个赛题,各赛题为渣土车车牌识别、反光衣识别、驾驶员不良驾驶识别、船只数量检测、机动车识别、占道经营检测、电动车进电梯检测和人体解析分割。同时为赛题着提供真实场景数据集、免费云端算力支持、便捷在线训练系统、OpenVINO工具套件等,帮助参赛者全程线上无障碍开发、加速模型推理,真正实现在线编码训练、模型转换、模型测试等一站式竞赛体验。
任务介绍
赛道6——占道经营检测
近年来地铁经济对拉动经济发展、增加就业起到了积极作用,如何有序管理摊位经营,维护城市交通顺畅和人员安全,是当前城市管理非常重要的问题。该赛题希望通过占道经营检测算法的开发,利用计算机视觉技术的“火眼金睛”,辅助城管人员,降低城市管理成本,使城市管理能更加智能高效,进而有效减少城市违规占道经营的情况。
挑战赛的参与者对图片中的占道经营行为进行目标检测,给出目标框和对应的类别信息,其类别为固定摆摊fixed_stall(街道、人行道周边的地位摊位)、移动摆摊move_stall(三轮车、贩卖小货车等)、遮阳伞sunshade(遮阳伞、临时贩卖小棚)。数据集是由监控摄像头采集的现场场景数据,训练数据集包括10147张,测试数据集包含4346张。
评价指标
该赛道最终得分采用准确度、算法性能绝对值的综合得分形式,具体形式如下:

说明:
(1)算法性能指的赛道标准值是 100 FPS, 如果所得性能值FPS≥赛道标准值FPS,则算法性能值得分=1;
(2)获奖评审标准:参赛者需要获得算法精度和算法性能值的成绩,且算法精度≥0.6,算法性能值FPS≥5,才能进入获奖评选;
(3)算法精度和性能均取自算法转换OpenVINO模型后的对应值;
(4) 本题规定predicted bounding box和ground truth bounding box的IoU(交叉比)作为结果目标匹配的依据,其中IoU值>0.5且目标类别标签相匹配的目标视为正确结果,其它视为正确结果,其它视为错误。
威富视界&中国科学院半导体研究所两支团队荣获四个第一、两个第二
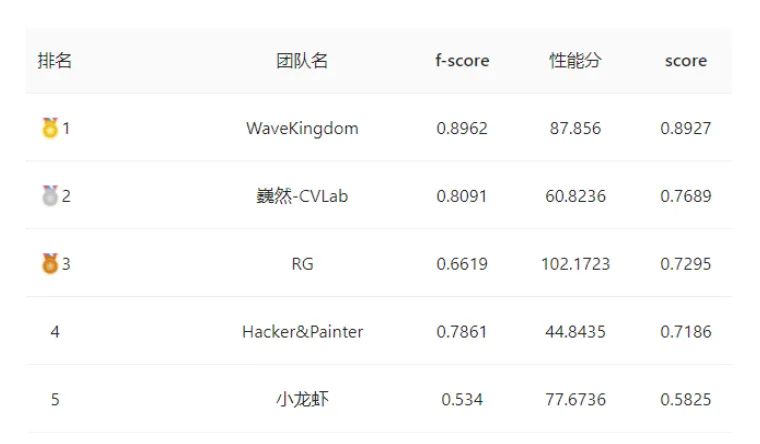
赛题特点
图像尺寸不一、近景和远景目标尺度差异大。
数据集图片尺寸不一,相差较大。一方面,由于计算资源和算法性能的限制,大尺寸的图像不能作为网络的输入,而单纯将原图像缩放到小图会使得目标丢失大量信息。另一方面,图像中近景和远景的目标尺度差异大,对于检测器来说,是个巨大的挑战。
目标在图像中分布密集,并且遮挡严重。
数据集均是利用摄像头从真实场景采集,部分数据的目标密集度较大。无论是赛道一中的行人还是赛道二中的小摊贩都出现了频繁出现遮挡现象,目标的漏检情况相对严重。
主要工作
1、主体框架选择
目前,基于深度学习的目标检测技术包括anchor-based和anchor-free两大类。首先我们先是分析两者的优缺点:
anchor-based:
1)优点:加入了先验知识,模型训练相对稳定;密集的anchor box可有效提高召回率,对于小目标检测来说提升非常明显。
2)缺点:对于多类别目标检测,超参数scale和aspect ratio相对难设计;冗余box非常多,可能会造成正负样本失衡;在进行目标类别分类时,超参IOU阈值需根据任务情况调整。
anchor-free:
1)优点:计算量减少;可灵活使用。
2)缺点:存在正负样本严重不平衡;两个目标中心重叠的情况下,造成语义模糊性;检测结果相对不稳定。
我们又考虑到比赛任务情况:
1)小摊位占道识别是小摊位检测,都属于多类别检测,目标的scale和aspect ratio都在一定范围之内,属可控因素。
2)比赛数据中存在很多目标遮挡情况,这有可能会造成目标中心重合,如果采用anchor-free,会造成语义模糊性;
3)scale和aspect ratio可控,那么超参IOU调整相对简单;
4)大赛对模型部署没有特殊要求,因此,部署方案相对较多,模型性能有很大改进。
因此,在anchor-based和anchor-free两者中,我们偏向于选择基于anchor-based的算法。
众所周知,YOLO系列性能在目标检测算法一直引人瞩目,特别是最近的YOLOv5在速度上更是令人惊讶。从下图可以看出,YOLOv5在模型大小方面选择灵活,训练周期相对较短。另外,在保证速度的同时,模型精度也是可观。因此,我们选用YOLOv5作为baseline,然后依据赛道的任务情况在此基础上进行改进。
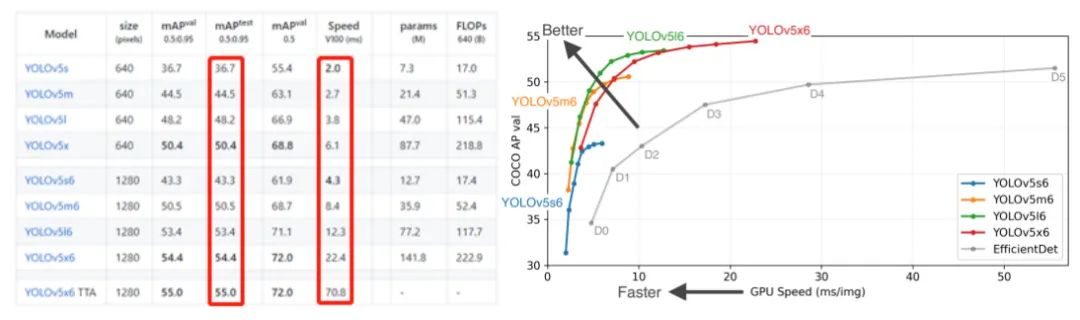
首先根据训练数据集进行分析,在10147张训练图像中,总共有3个类别。存在以下三种情况:(1)样本不平衡;(2)场景样本不均衡;(3)多种状态小摊位,例如重叠、残缺、和占比小且遮挡。
另外,要权衡检测分类的精度和模型运行的速度,因此我们决定选用检测分类精度较好的目标检测框架,同时使用模型压缩和模型加速方法完成加速。其主体思路为:
目标检测框架:基于YOLOv5的one-stage检测框架;
模型优化:采用优化策略,比如数据增强、SAM优化器、Varifocal Loss、冻结训练策略;
训练时间优化:采用Yolov5+Cache+图像编解码;
模型压缩:OpenVINO转换后INT8量化;
模型加速:训练C++封装部署。
我们针对以上策略进行详细介绍:
(1)数增强策略
从数据角度,我们通过粘贴、裁剪、mosaic、仿射变换、颜色空间转换等对样本进行增强,增加目标多样性,以提升模型的检测与分类精度。
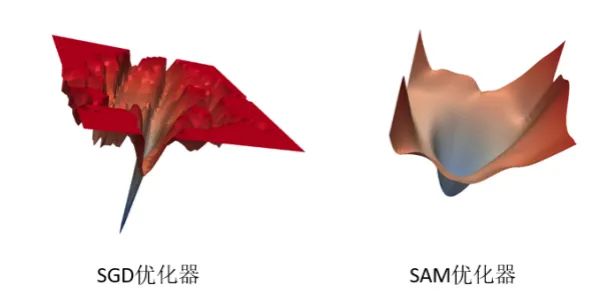
(2)SAM优化器
SAM优化器[4]可使损失值和损失锐度同时最小化,并可以改善各种基准数据集(例如CIFAR-f10、100g,ImageNet,微调任务)和模型的模型泛化能力,从而产生了多种最新性能。另外, SAM优化器具有固有的鲁棒性。
经实验对比,模型进行优化器梯度归一化和采用SAM优化器,约有0.027点的提升。
(3)Varifocal Loss损失函数
Varifocal Loss主要训练密集目标检测器使IOU感知的分类得分(IASC)回归,来提高检测精度。而目标遮挡是密集目标的特征之一,因此尝试使用该loss来缓解目标遮挡造成漏检现象。并且与focal loss不同,varifocal loss是不对称对待正负样本所带来的损失。
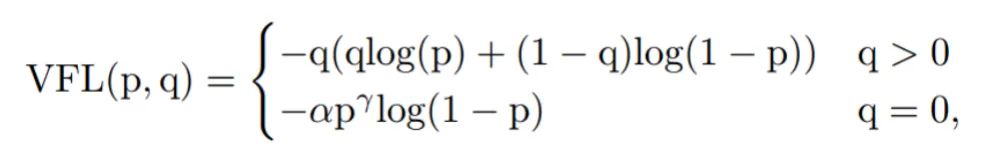
在比赛过程中,p输入为前景类的预测概率;q为ground-truth;减少负样本的损失贡献,而正样本不降低正权重。因为正样本相对于负样本是非常罕见的,应保留他们的学习信息。
(4)冻结训练
在训练过程中采取常规训练与冻结训练想相结合的方式迭代,进一步抑制训练过程中容易出现的过拟合现象,具体训练方案是:1)常规训练;2)加入冻结模块的分步训练1;3)加入冻结模块的分步训练2。
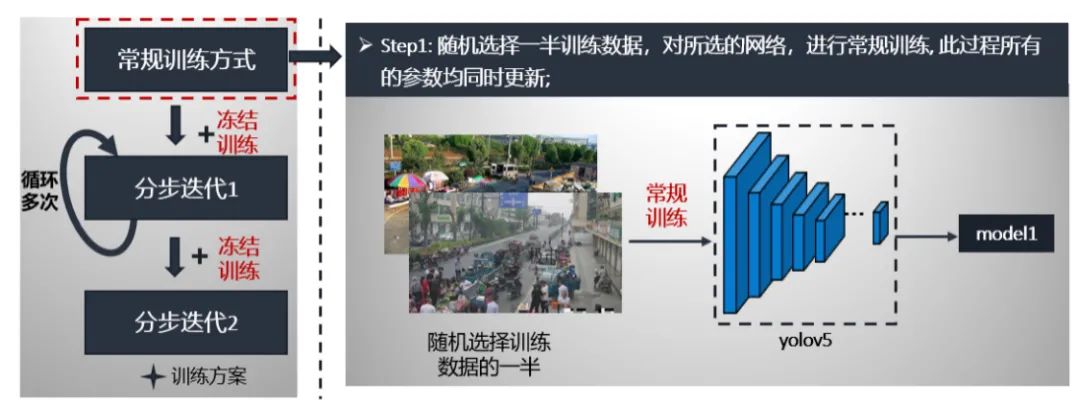
我们详细讲解以上步骤。第一步:从训练数据中随机选取一半,进行yolov5常规训练,该过程中所有的参数是同时更新的。最后获得在a榜上最好模型model1。具体流程如下:
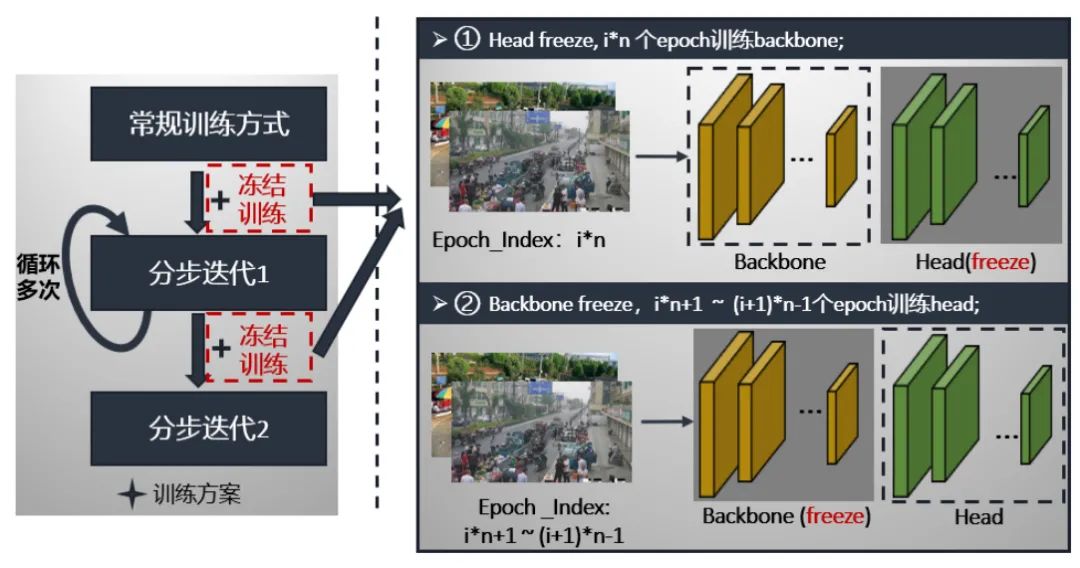
在介绍第二步和第三步之前,我们先介绍一下冻结模块。冻结模块的特点就是将backbone和head轮流冻结,每epoch只更新未冻结部分的参数。我们以5个epoch为一个阶段,第一个epoch为head冻结,只训练backbone;第2~5个epoch为backbone冻结,只训练head。这样轮流更新backbone和head的参数,具体过程如下:
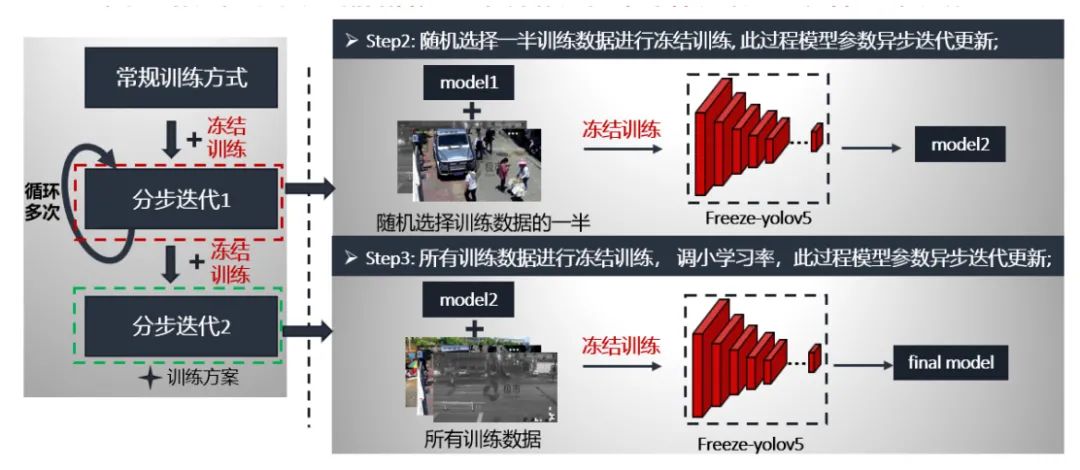
第二步分布迭代1就是采用的冻结模块进行,数据是随机选取训练数据的一半,预训练模型是第一步常规训练的最好模型,按照冻结训练方式进行训练。这个流程循环多次,获得model2。
第三步分布迭代2同样采用的是冻结模块进行,数据是所有训练数据,由于参数已经学过,这时我们将学习率调小一个量级,同样也是按照冻结训练方式进行训练。这个流程只循环一次,获得最终的模型。
两步的具体流程如下:
(5)训练时间优化
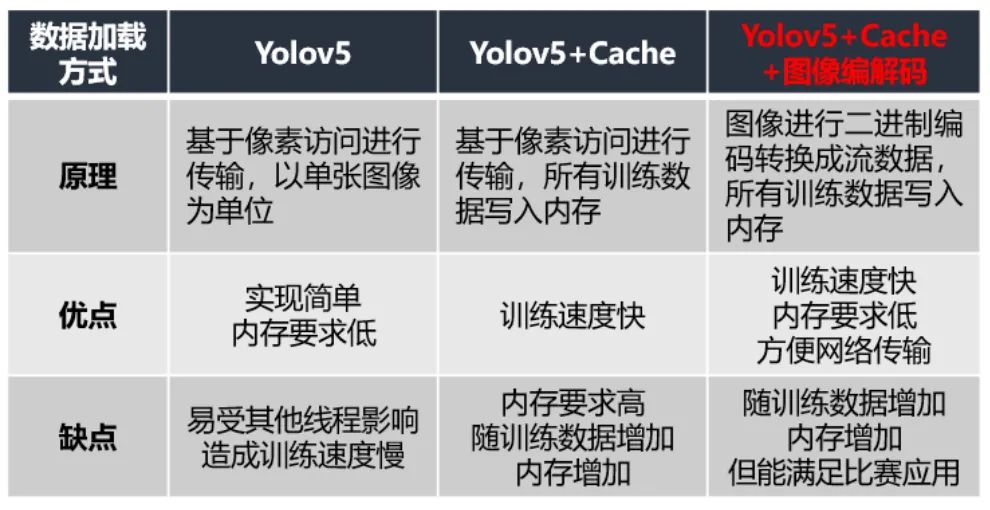
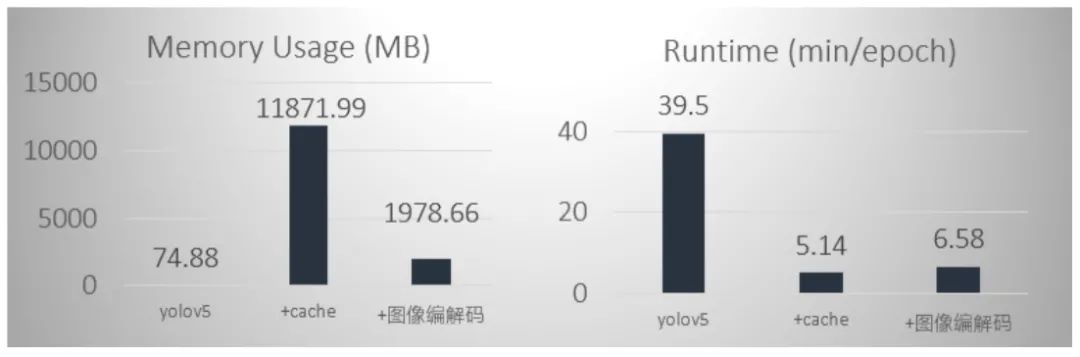
最初我们直接采用yolov5训练,这种数据加载方式是以张为单位,基于像素的访问,但是训练时速度很慢,可能受其他线程影响造成的,大概一轮要40分钟左右。然后我们就尝试了cache这种方式,它是将所有训练数据存入到内存中,我们以6406403的输入图像为例,占道数据总共有10147张,全部读进去大约占11.6G的内存,平台是提供12G的内存,几乎将内存占满,也会导致训练变慢;于是我们就尝试改进训练读取数据方式,我们采用的是cache+图像编解码的方式,内存占用仅是cache的1/6,由于添加了编解码,速度比cache慢点,但从数据比较来看,相差无几。这样既能节省内存又能加快训练速度。节省了我们训练过程的极力值和加快实验的步伐。
(6)模型量化
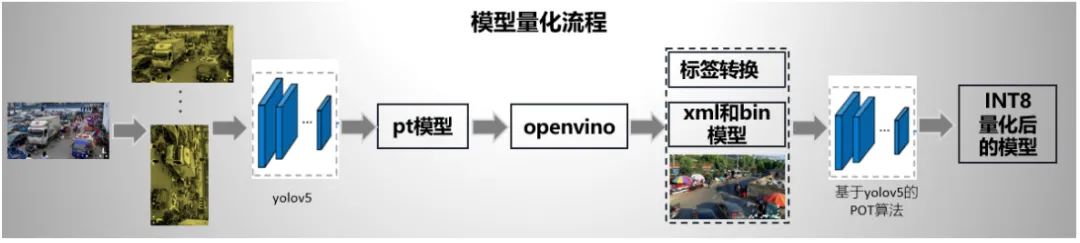
我们考虑完精度后,我们考虑模型量化问题。我们用的是openvino 2020自带的工具将模型转换为INT8类型,主要为:(1)POT,主要是用于INT8转换;(2)accuracy_check,用来检查模型在指定数据集上的推理精确度。
POT提供了多种量化和辅助算法来帮助量化权重和激活图后的模型恢复精度。这里仅介绍我们对比的两种方案:一种是DefaultQuantization,旨在执行快速且准确的神经网络的INT8量化。但是我们在该赛道使用该方法mAP为0;另一种算法是AccuracyAwareQuantization,它是执行精确的INT8量化,允许在量化后精度下降在预定的范围内,同时牺牲一定的性能提升,并需要更多的时间量化。我们设定的精度下降阈值是0.005。
我们整个模型量化流程为:
实验结果
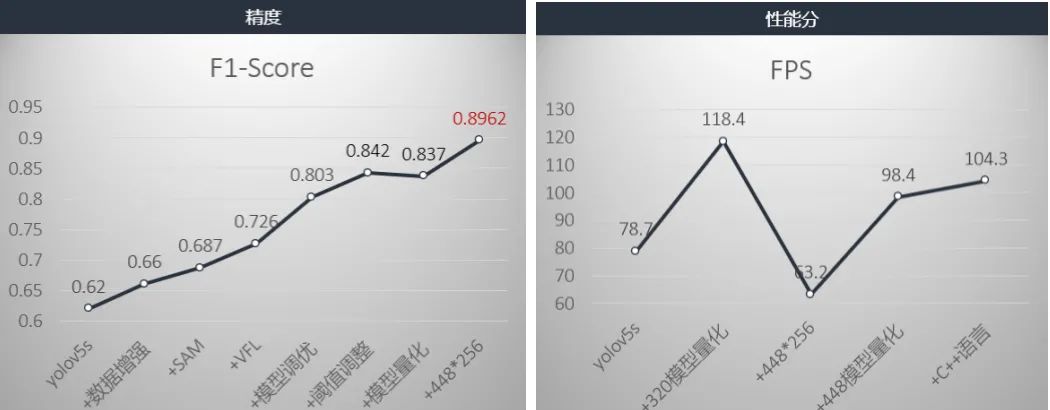
关于精度方面我们添加各种trick后,精度F1-Score提升到了0.842。没有量化之前,性能约为78.7FPS,我们进行了基于openvino的模型量化,精度降低为0.837,但性能提升了118.4。而我们比赛性能要求是100FPS为满分。因此,我们就将输入图像从320调整为448,模型就提升到了0.8962,没有量化之前性能分为63.2,量化后为98.4,然后我们由将python语言换成了c++语言,达到了104.3FPS。
讨论与总结
本文针对2021极市计算机视觉开发者榜单大赛任务了总结与归纳。相关结论可以归纳为以下几点:
数据分析对于训练模型至关重要。数据不平衡、图像尺寸和目标大小不一、目标密集和遮挡等问题,应选用对应的baseline和应对策略。例如,数据不平衡可尝试过采样、focal loss、varifocal loss、数据增强等策略;图像尺寸和目标大小不一可采用多尺度、数据裁剪等方法。 针对算法精度和性能两者取舍来说,可先实验网络大小和输入图片大小对模型结果的影响,不同任务和不同数据情况,两者相差较大。所以不能一味为了提高速度,单纯压缩网络大小; 针对性能要求时,可采用OpenVINO INT8、C++等方式部署模型,也可采用模型压缩等方式,这样可在保证速度的前提下,使用较大网络,提升模型精度。
参考文献
https://github.com/ultralytics/yolov5.git https://www.cvmart.net/ Zhang H , Wang Y , Dayoub F , et al. VarifocalNet: An IoU-aware Dense Object Detector[J]. 2020. Pierre F, Ariel K, Hossein M, Behnam N; Sharpness-Aware Minimization for Efficiently Improving Generalization[2020]
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
