
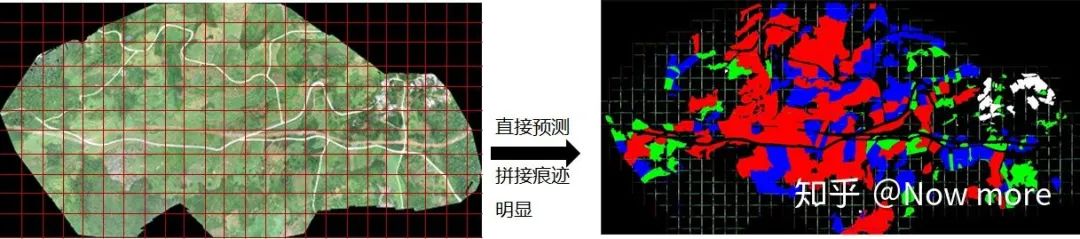
农作物地块范围识别(图像分割)

来源:机器学习AI算法工程、知乎@Now more 本文约5500字,建议阅读15分钟 本文为你介绍 以薏仁米作物识别以及产量预测为比赛命题,及对对应获奖的开发算法模型。
评估指标
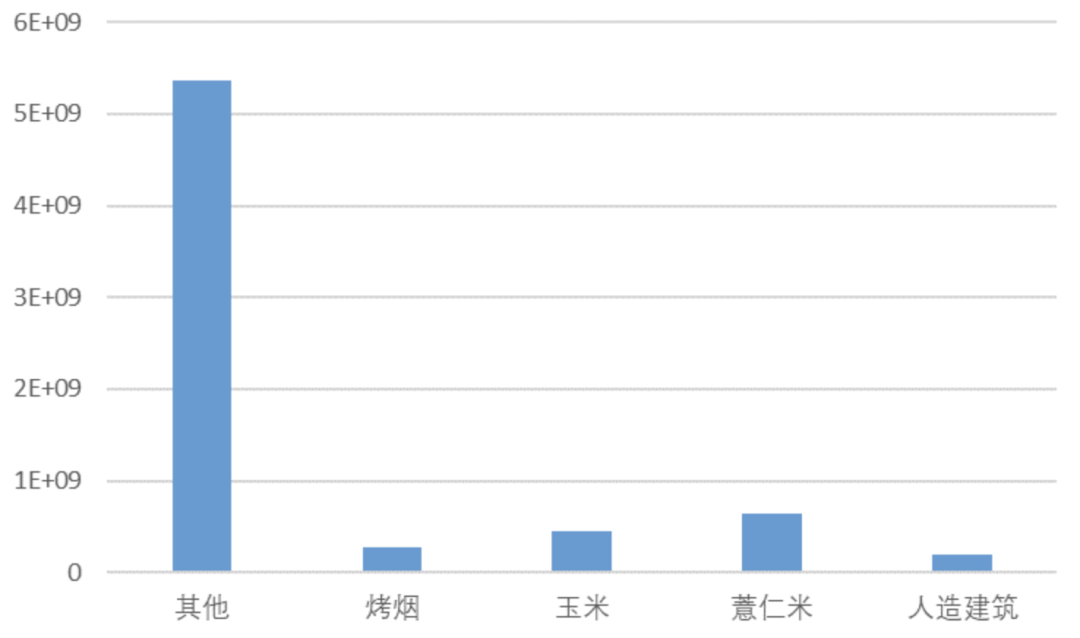
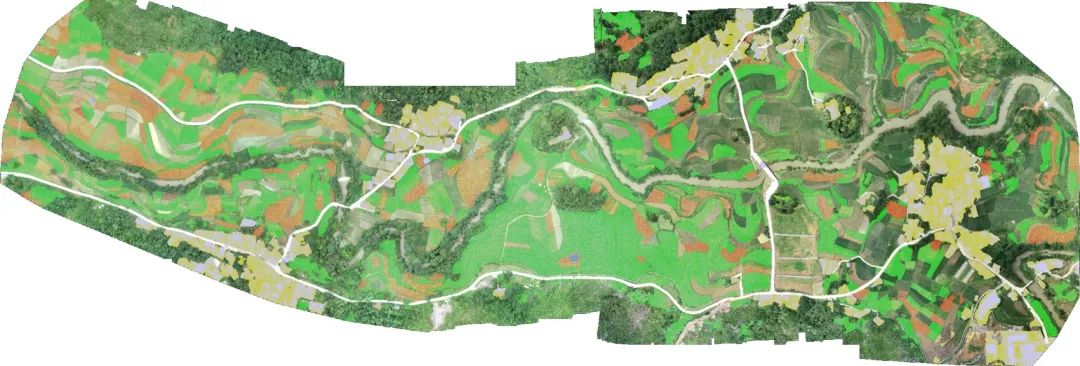
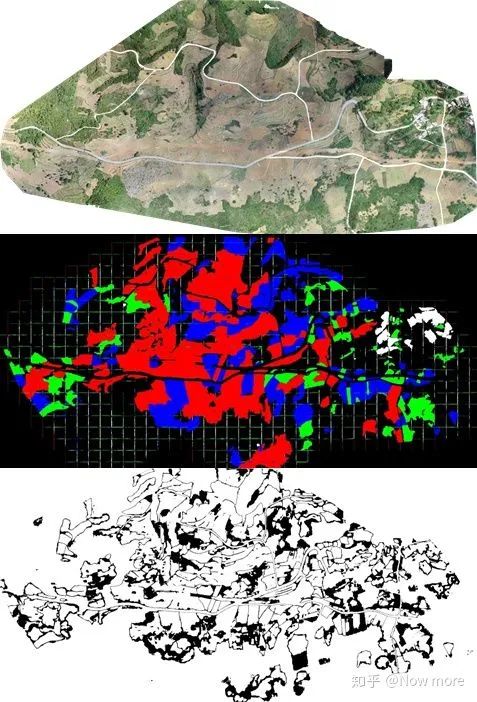
不同类别的标签统计,背景类最多,人造建筑最少。
一、亚军方案介绍
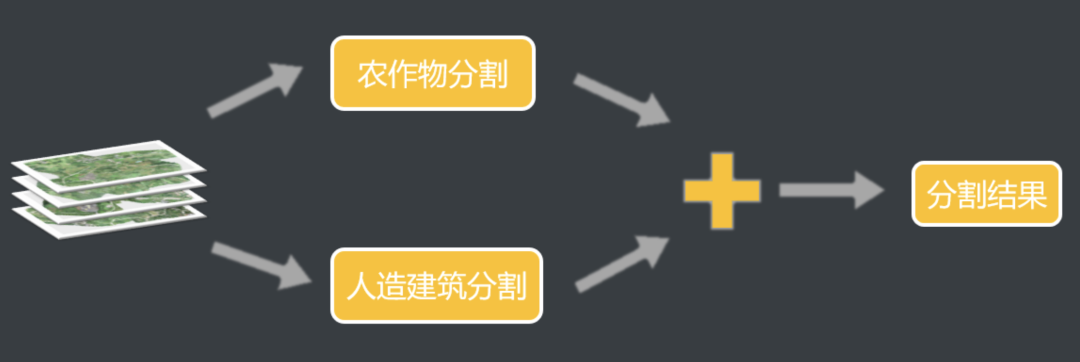
1. 总体方案
2. 预处理
裁剪

数据增强
3. 农作物分割
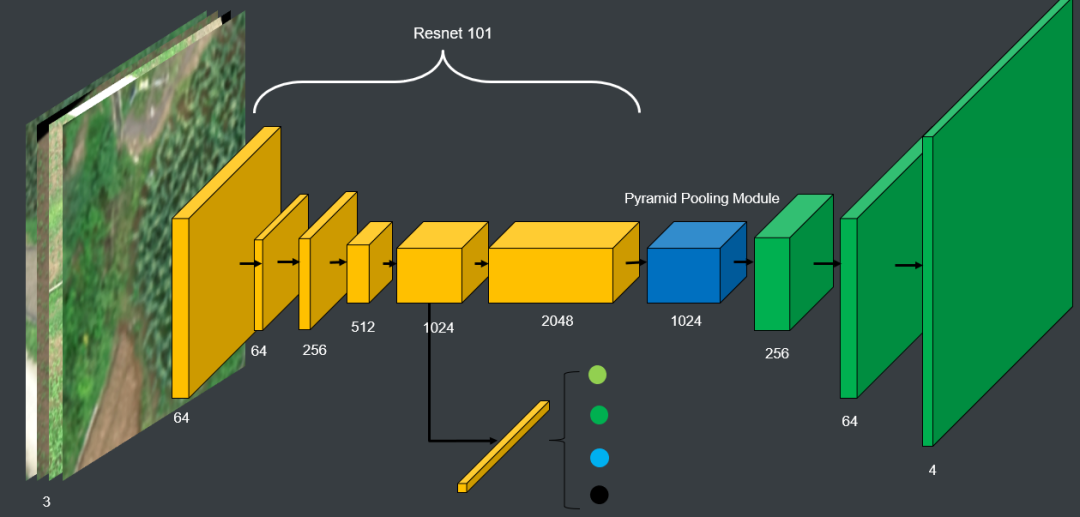
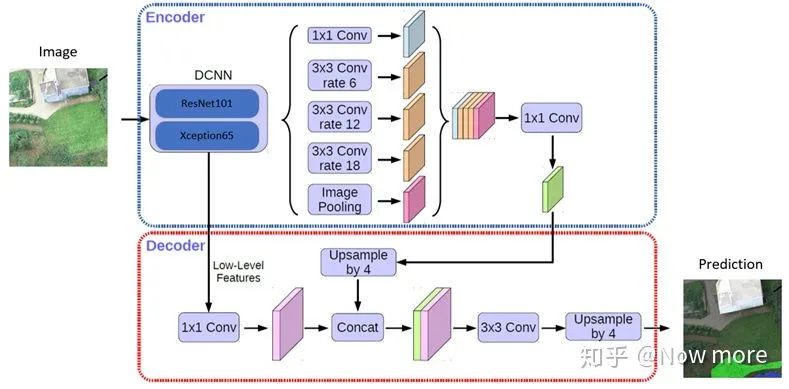
模型这里也可以考虑换成deeplab v3+,结果应该会有一点提升,决赛的几个队伍中,很多都是使用的deeplab v3+,deeplab的ASPP同样有融合context信息的作用。
4. 建筑物分割
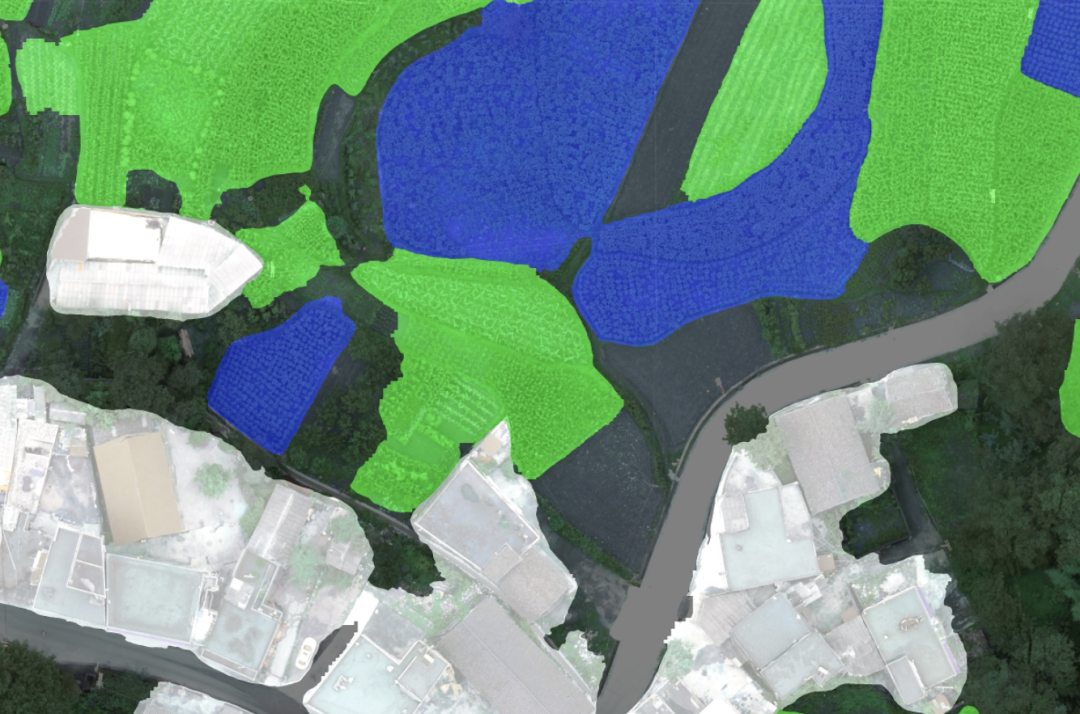
下图中可以看出,图中右面在训练集的标签上是属于建筑物的一部分,可是跟左边的水泥路十分相似。

解决方法是将建筑物单独使用一个网络进行分割,并且训练集降低分辨率,最终尝试将原图降低16倍分辨率作为建筑物的训练集。
如下图,单独分割后显著地降低了建筑的错误。

网络使用的是HRNet,HRNet一直保持的高分辨率feature map对于建筑物的边界细节预测较准确。
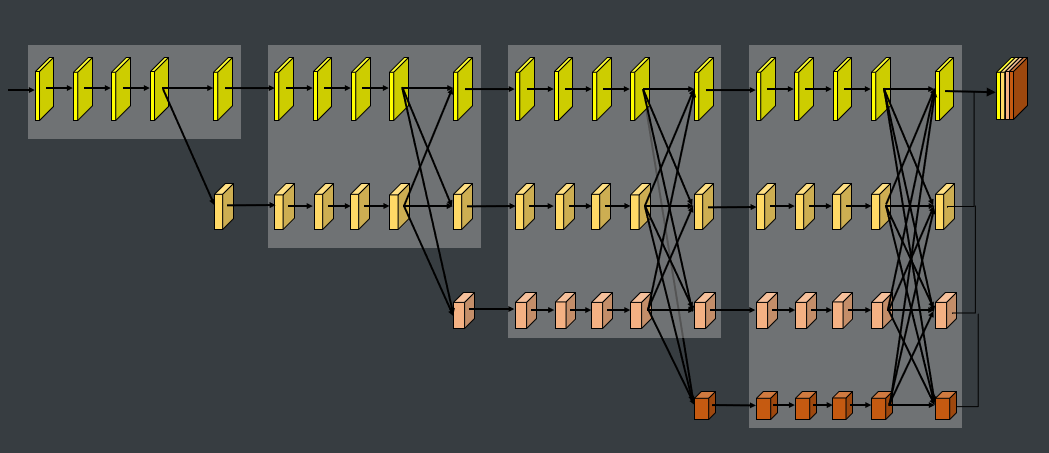
5. 训练细节
由于训练集中标签有噪声,如下:

6. 半监督
半监督方法应该算是比赛中比较常用的方法,在比赛中也是在A榜的最后一次提交中才使用了半监督的方法,单模型结果达到了0.788,是除了建筑物单独分割以外提升最大的trick了,对于置信度等参数也没有机会进行进一步的尝试,感觉半监督还有潜力可以挖掘。
感觉半监督方法在这个数据集中尤为适合,对于原因也不太明确。
这里看到过一个说法:“半监督带来的提升不只是数据量带来的提升,而是对于那些数据难以精确标注的场合,”结合这次比赛的数据,虽然是语义分割的比赛,但是label并不是像素级精度的,标注的时候应该使用的是多边形的标注,所以对于边界的标注很不精细,并且对于农田其实也很难找到一个很明确的边界来标记,感觉可能符合难以精细标注这个描述,但是对于这个说法并没有找到相关的论文,哪位大佬如果有更好的解释或者相关的论文推荐,希望不吝赐教。
7. 预测

8. 最终结果
二、冠军整体方案
1. 数据预处理
滑窗裁剪
类别平衡:过滤掉mask无效占比大于7/8的区域,在背景类别比例小于1/3时减小滑窗步长,增大采样率; patch:实验中没有观察到patch对模型性能有显著影响,最后采取策略同时保留1024和512两种滑窗大小,分别用来训练不同的模型,提高模型的差异度,有利于后期模型集成; 速度:决赛时算法复现时间也是一定的成绩考量,建议使用gdal库,很适合处理遥感大图的场景。本地比赛中我们直接多进程加速opencv,patch为1024时,单张图5~6min可以切完;
策略一:以1024x1024的窗口大小,步长900滑窗,当窗口中mask无效区域比例大于7/8则跳过,当滑动窗口中背景类比例小于1/3时,增加采样率,减小步长为512; 策略二:以1024x1024的窗口大小,步长512滑窗,当滑动窗口中无效mask比例大于1/3则跳过。
数据增强
2. 模型选择

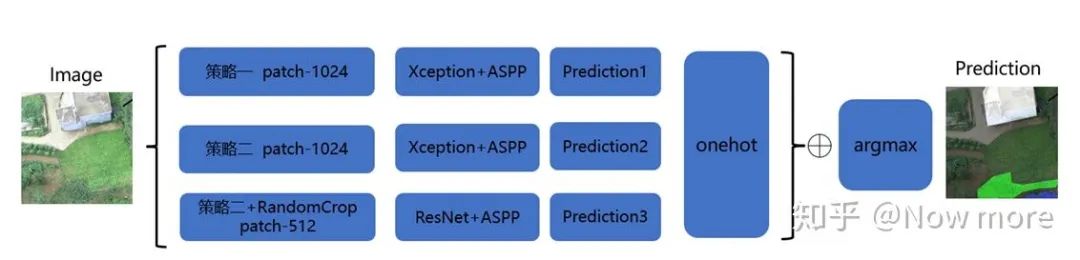
三、涨分点
1. 膨胀预测
填充1 (黄色部分) : 填充右下边界至滑窗预测窗口大小的整数倍,方便整除切割; 填充2(蓝色部分) : 填充1/2滑窗步长大小的外边框(考虑边缘数据的膨胀预测); 以1024x1024为滑窗,512为步长,每次预测只保留滑窗中心512x512的预测结果(可以调整更大的步长,或保留更大的中心区域,提高效率)。

2. 测试增强

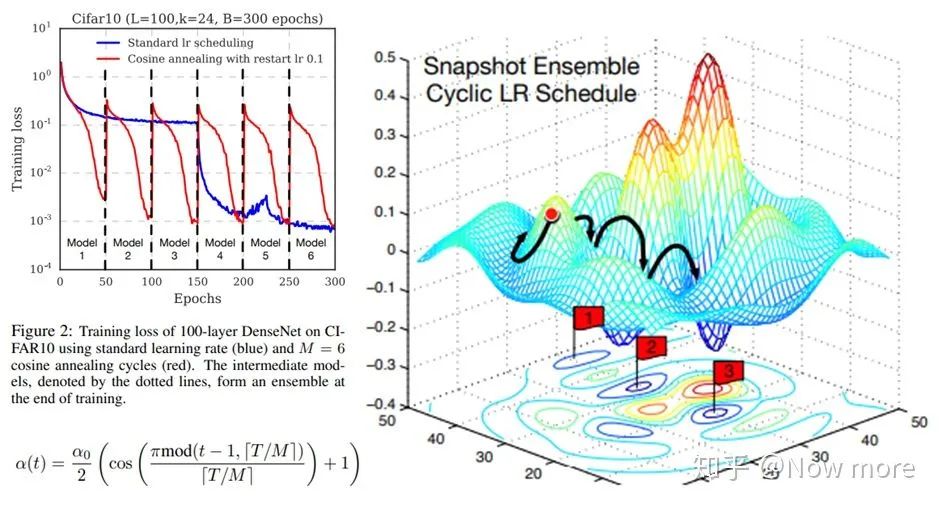
3. snapshot ensemble
4. 后处理
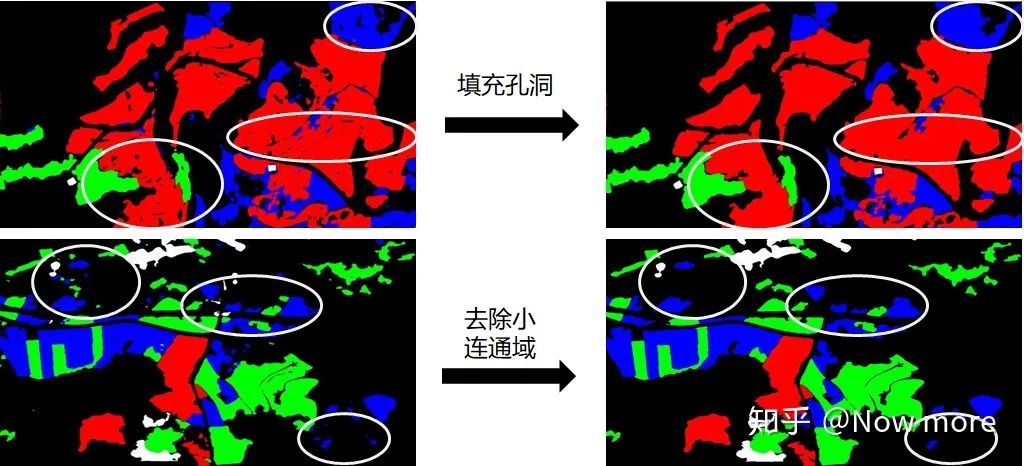
针对本次赛题数据场景为大面积农田预测,通过简单的填充孔洞、去除小连通域等后处理,可以去除一些不合理的预测结果。
5. 边缘平滑
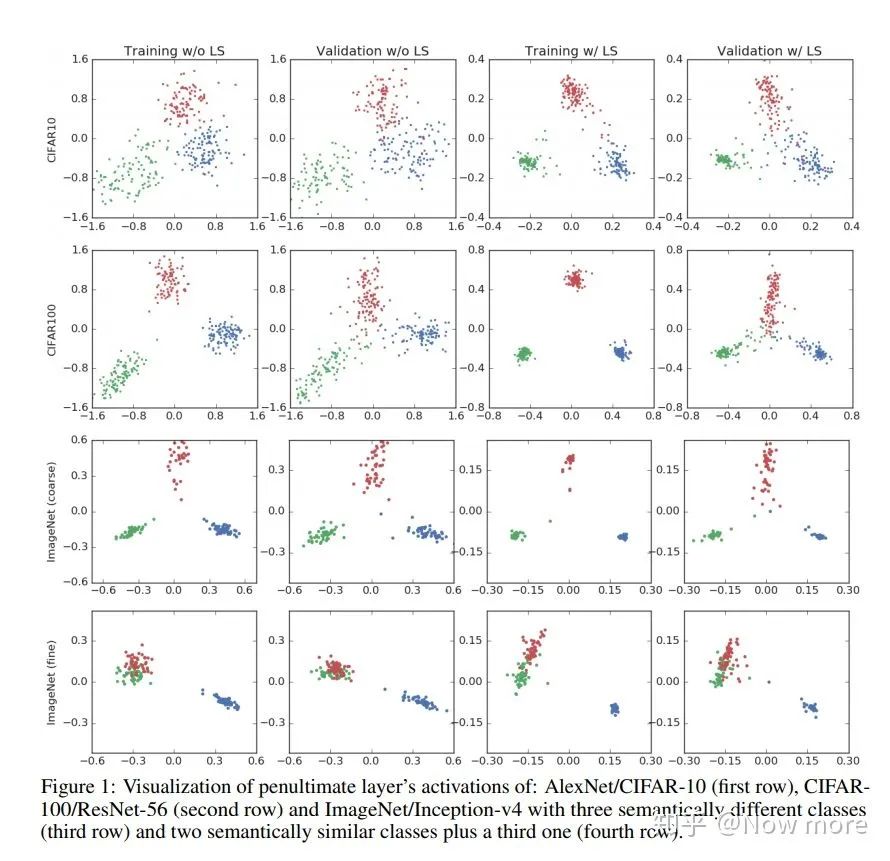
图像边缘:卷积时零填充太多,信息缺少,难以正确分类(参考3.1的方格效应) 不同类间交界处: 标注错误,类间交界难以界定,训练时可能梯度不稳定 类间交界的点,往往只相差几个像素偏移,对网络来说输入信息高度相似,但训练时label 却不同,也是训练过程的不稳定因素。
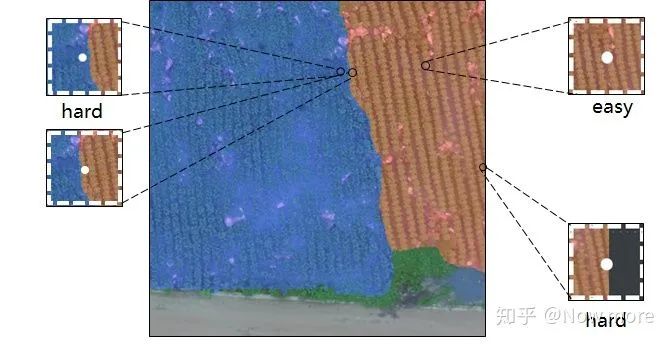

6. 伪标签

利用在测试集表现最好的融合模型结果作伪标签,用多组不同置信度阈值过滤数据,结合训练集训练模型; 选取多个snapshot的方法对模型进行自融合提高模型的泛化能力; 集成2中的预测结果,更新伪标签,重复步骤1~3。
四、总结
膨胀预测消除边缘预测不准问题; 使用测试增强、消除空洞和小连通域等后处理提高精度; 使用snapshot模型自融合、标签平滑、伪标签等方法提高模型稳定性和对新地形泛化能力;
编辑:黄继彦
评论