
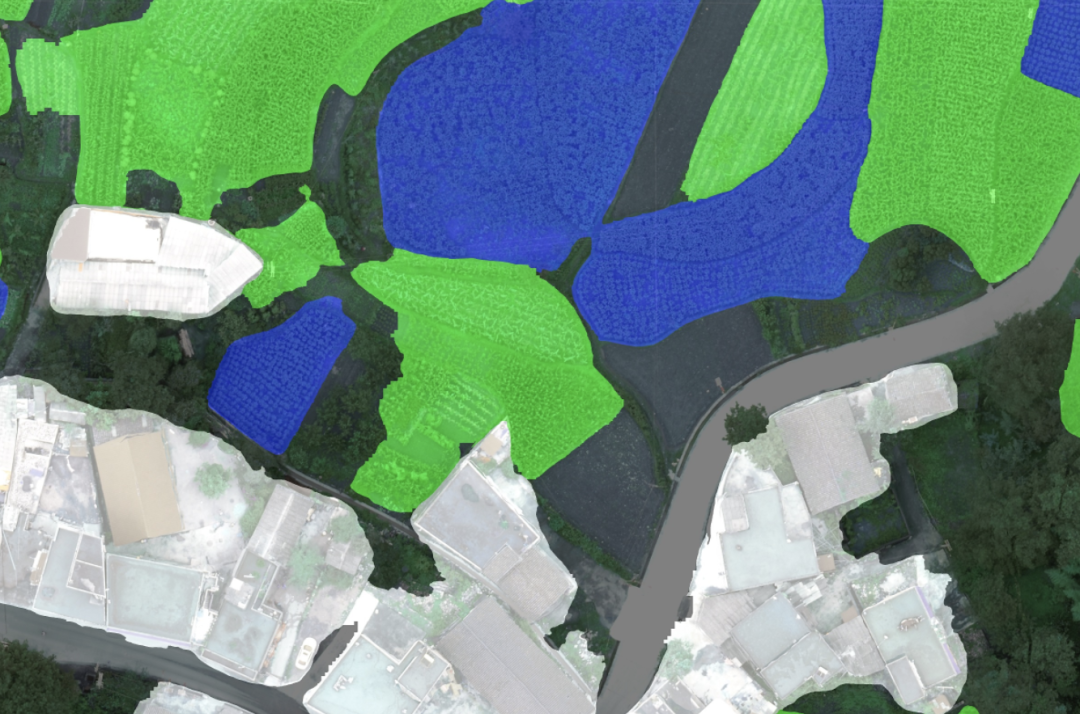
农作物地块范围识别(图像分割)

向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
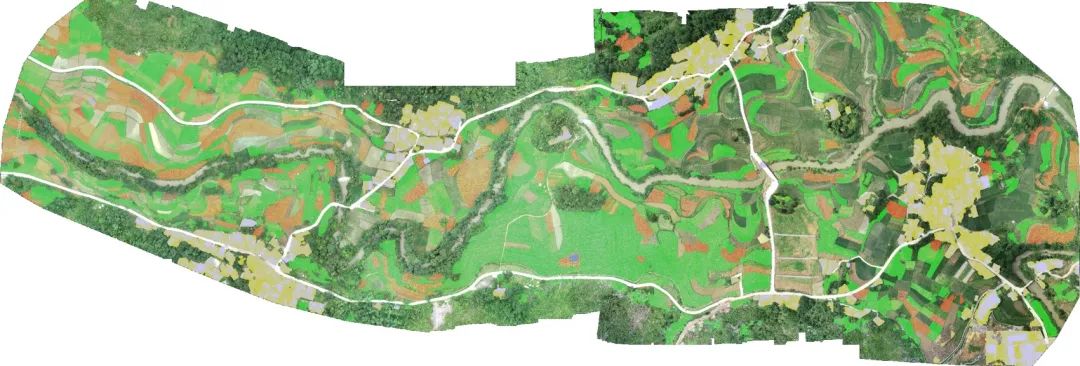
农作物的资产盘点与精准产量预测是实现农业精细化管理的核心环节。当前,我国正处于传统农业向现代农业的加速转型期,伴随着农业的转型升级,政府宏观决策、社会各界对农业数据的需求不断增加,现有农业统计信息的时效性与质量,已不足以为市场各主体的有效决策提供科学依据。在农作物资产盘点方面,传统的人工实地调查的方式速度慢、劳动强度大,数据采集质量受主观因素影响大,统计数据有较大的滞后性,亟待探索研究更高效准确度更高的农业调查统计技术。在产量预测方面,及时准确地获取区域作物单产及其空间分布信息,对作物进行精准的产能预测,对于农业生产安全预警、农产品贸易流通,以及农业产业结构优化具有重要意义。
本次任务,我们选择了具有独特的地理环境、气候条件以及人文特色的贵州省兴仁市作为研究区域,聚焦当地的特色优势产业和支柱产业——薏仁米产业, 以薏仁米作物识别以及产量预测为比赛命题,要求选手开发算法模型,通过无人机航拍的地面影像,探索作物分类的精准算法,识别薏仁米、玉米、烤烟、人造建筑四大类型,提升作物识别的准确度,降低对人工实地勘察的依赖,提升农业资产盘点效率,并结合产量标注数据预测当年的薏仁米产量,提升农业精准管理能力。
评估指标
采用平均交并比(Mean Intersection over Union)作为评价标准,即求出每一类的 IOU 取平均值。IOU 指的是,真实标签和预测结果的两块区域交集/并集。评估只考虑“烤烟”,“玉米”,“薏仁米”,“人造建筑”四种类型。针对每种作物所有的预测结果,统计每个类别的真实标签和预测结果,根据 Jaccard Index 计算 IOU,最后取平均。
具体的,针对4种类型图片分别计算 TP, FP, and FN;求和得到所有图片的 TP, FP, and FN;根据 Jaccard Index = TP/(TP+FP+FN),计算得到 IOU。最后对所有4个类别的 IOU 取平均,得到最后的 MIOU 作为评测结果。
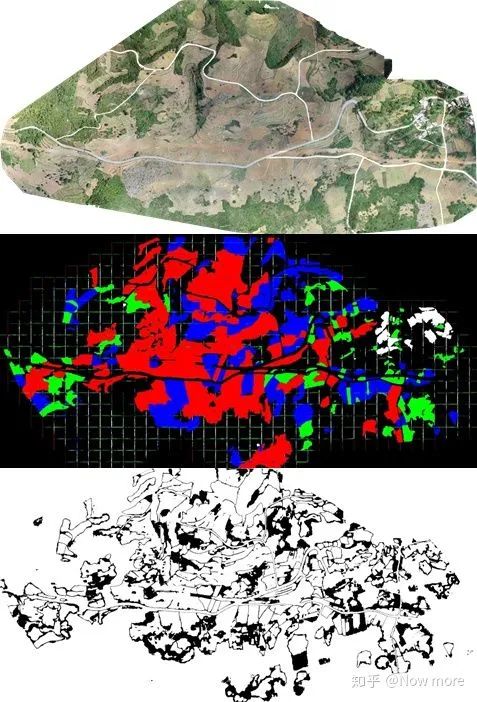
不同类别的标签统计,背景类最多,人造建筑最少

和普通的语义分割任务相比,本次任务有着以下几个特点,
一是类间差异小,不同种类农作物之间外观差异小,
二是物体尺度相差大,要分割的类别中农作物于人造建筑两个类别的尺度不同,
三是标签不是非常精细,标注存在着不少的噪声。
全部代码 获取方式:
关注微信公众号 datayx 然后回复 农作物 即可获取。
亚军方案介绍
总体方案
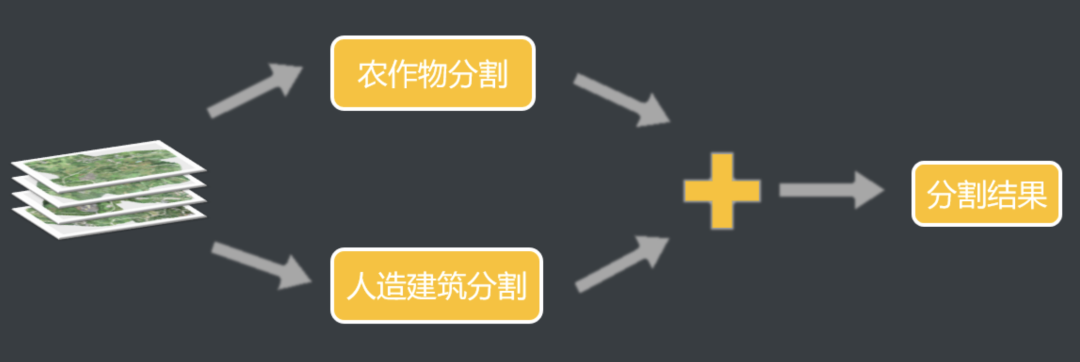
我们的方案总体流程如下,我们的方案将整个任务分成了两个分支,一个分支进行农作物耕地的分割,一个分支进行人造建筑物的分割,后面我们会介绍为什么将任务分成两个分支。然后将两个分支的预测结果求和得到最终的预测结果。
预处理
裁剪
我们这次的训练数据是无人机航拍拼接得到的图片,分辨率非常大,在复赛的训练集中,最大的图片尺寸有55128×49447,无法直接用于训练,因此我们对原图片进行了裁剪,将其裁剪成小块作为训练集,我们的裁剪方法为在原图上滑动进行裁剪,右面是我们裁剪的示意图,裁剪图片的大小为1600×1600,步距为800,对于完全透明的地方直接略过,农作物的训练集我们在原图上进行裁剪,对于人造建筑,我们将原图的分辨率降低16倍后再进行裁剪。

数据增强
数据增强就是使用了一些常规的数据增强方法,旋转、颜色抖动、翻转、resize等,还加入了随机的模糊操作。
农作物分割
农作物分割分类四个类别,3类农作物和一类背景。使用的是PSPNet的网络,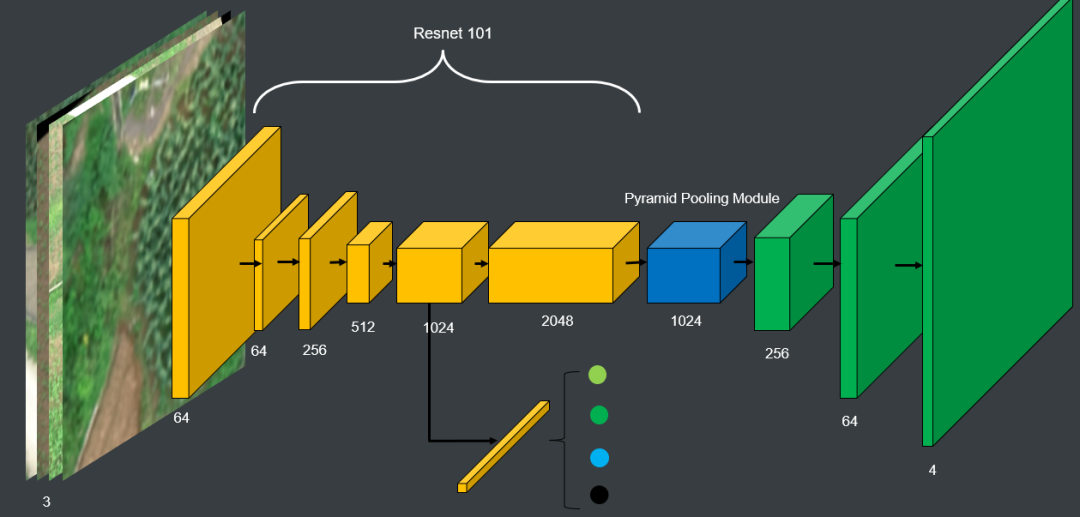
替换了backbone,最终使用3×3 resnet101,PPM输出的feature map经多次上采样回原分辨率。
在初赛的时候一直使用的是unet的结构,发现结果不是很好,结果不太平滑,经常有很多孔洞之类的,后续更换了PSPNet大为改善,推测可能是由于Unet的一些较低级的特征对于分割帮助不大并且unet缺乏global context的信息,context的信息在这个数据集中很重要。
模型这里也可以考虑换成deeplab v3+,结果应该会有一点提升,决赛的几个队伍中,很多都是使用的deeplab v3+,deeplab的ASPP同样有融合context信息的作用。
建筑物分割
为什么将建筑物单独分割,主要是考虑到建筑物于农作物两个目标尺度相差太多,普通的多尺度方法也无法解决,我们训练使用的是512×512大小的图像,导致经常图像中只含有建筑物的一部分,缺乏足够的信息对建筑物进行判别。
下图中可以看出,图中右面在训练集的标签上是属于建筑物的一部分,可是跟左边的水泥路十分相似。

解决方法是将建筑物单独使用一个网络进行分割,并且训练集降低分辨率,最终尝试将原图降低16倍分辨率作为建筑物的训练集。
如下图,单独分割后显著的降低了建筑的错误。

网络使用的是HRNet,HRNet一直保持的高分辨率feature map对于建筑物的边界细节预测较准确。
训练细节
训练使用多分类交叉熵损失函数,不同类别根据数据量添加类别权重。
由于训练集中标签有噪声,如下
导致在训练后期,某些batch的loss值显著的大于正常值,将这些batch可视化,很多是属于label标记错误,这些batch对于网络收敛有很大影响,所以设定阈值,让其不回传或者减小这些batch的learning rate。
但是注意这里其实这些batch显著大的有一些是一些hard example,比如外观和农作物非常相似的背景或者种植的比较稀疏的农作物,大概在这些batch中hard example和label noise半对半,但是没有想到什么比较好的方法来区分这两者,所以采用减小学习率的方法。后续可以考虑寻找一些方法或者特征来对label noise和hard example进行区分。
半监督
使用模型对没有标签的A榜测试集预测生成伪标签,然后加入训练集,对网络进行重新训练,对结果提升较大。
半监督方法应该算是比赛中比较常用的方法,在比赛中也是在A榜的最后一次提交中才使用了半监督的方法,单模型结果达到了0.788,是出了建筑物单独分割以外提升最大的trick了,对于置信度等参数也没有机会进行进一步的尝试,感觉半监督还有潜力可以挖掘。
感觉半监督方法在这个数据集中尤为适合,对于原因也不太明确。
这里看到过一个说法:“半监督带来的提升不只是数据量带来的提升,而是对于那些数据难以精确标注的场合,”结合这次比赛的数据,虽然是语义分割的比赛,但是label并不是像素级精度的,标注的时候应该使用的是多边形的标注,所以对于边界的标注很不精细,并且对于农田其实也很难找到一个很明确的边界来标记,感觉可能符合难以精细标注这个描述,但是对于这个说法并没有找到相关的论文,哪位大佬如果有更好的解释或者相关的论文推荐,希望不吝赐教。
预测
预测时同样在原图裁剪进行预测,使用U-net中的overlap策略,没有使用其他测试增强的方法,输入蓝色框内图片,最终只取黄色框内结果作为最终结果,放弃周围边缘预测结果。
最终结果
冠军整体方案
1.1 数据预处理
1.1.1 滑窗裁剪
原始数据为分辨率几万的PNG大图,需对原始数据预处理,本次比赛中我们采取的是滑窗切割的策略,主要从以下三个方面考量:
类别平衡:过滤掉mask无效占比大于7/8的区域,在背景类别比例小于1/3时减小滑窗步长,增大采样率;
patch:实验中没有观察到patch对模型性能有显著影响,最后采取策略同时保留1024和512两种滑窗大小,分别用来训练不同的模型,提高模型的差异度,有利于后期模型集成;
速度:决赛时算法复现时间也是一定的成绩考量,建议使用gdal库,很适合处理遥感大图的场景。本地比赛中我们直接多进程加速opencv,patch为1024时,单张图5~6min可以切完;
最终采取的切割策略如下:
策略一:以1024x1024的窗口大小,步长900滑窗,当窗口中mask无效区域比例大于7/8则跳过,当滑动窗口中背景类比例小于1/3时,增加采样率,减小步长为512;
策略二:以1024x1024的窗口大小,步长512滑窗,当滑动窗口中无效mask比例大于1/3则跳过。
2.2.2 数据增强
数据增强只做了常规的数据增强,如:RandomHorizontalFlip、RandomVerticalFlip、ColorJitter等。由于数据采集场景是无人机在固定高度采集,所以目标尺度较为统一,没有尝试scale的数据增强。
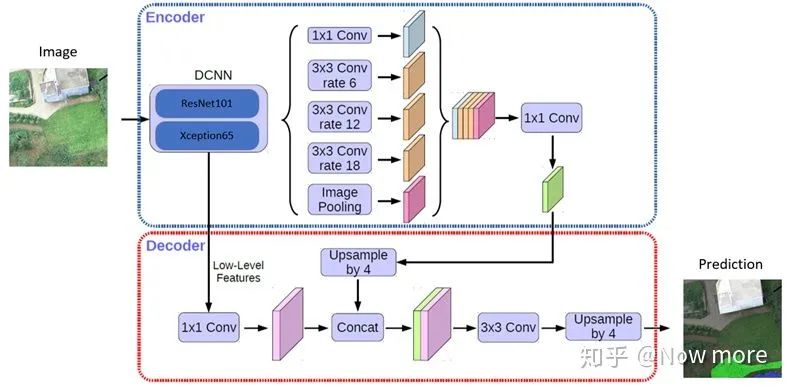
2.2 模型选择
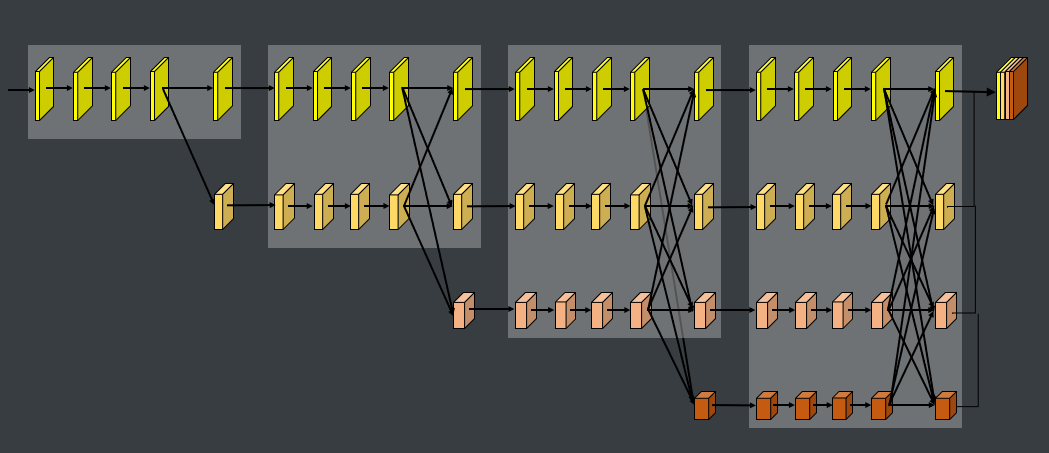
模型上我们队伍没有做很多的尝试,下表整理了天池、Kaggle一些分割任务中大家常用的方案。初赛尝试过PSPNet、U-Net等方案,但没有调出比较好的分数,复赛都是基于DeeplabV3+(决赛5个队伍里有4个用了DeeplabV3plus)backbone为Xception-65、ResNet-101、DenseNet-121。从复赛A榜分数提交情况,DenseNet-121 backbone 分数略高于另外两个,但显存占用太大以及训练时间太长,在后来的方案里就舍弃了。本次赛题数据场景为大面积农田预测,直接用deeplabV3plus高层特征上采样就有不错的效果,结合了底层特征预测反而变得零散。决赛算法复现时,使用了两个Xception-65和一个ResNet-101投票,投票的每个模型用不同的数据训练,增加模型差异。


3. 涨分点
3.1 膨胀预测
方格效应:比赛测试集提供图像分辨率较大,无法整图输入网络。如果直接无交叠滑窗预测拼接,得到的预测结果拼接痕迹明显。
原因分析:网络卷积计算时,为了维持分辨率进行了大量zero-padding,导致网络对图像边界预测不准。

膨胀预测:采用交叠滑窗策略(滑窗步长<滑窗窗口大小),预测时,只保留预测结果的中心区域,舍弃预测不准的图像边缘。
具体实现:
填充1 (黄色部分) : 填充右下边界至滑窗预测窗口大小的整数倍,方便整除切割;
填充2(蓝色部分) : 填充1/2滑窗步长大小的外边框(考虑边缘数据的膨胀预测);
以1024x1024为滑窗,512为步长,每次预测只保留滑窗中心512x512的预测结果(可以调整更大的步长,或保留更大的中心区域,提高效率)。

3.2 测试增强
测试时,通过对图像水平翻转,垂直翻转,水平垂直翻转等多次预测,再对预测结果取平均可以提高精度,但相对的,推理时间也会大幅度升高。

3.3 snapshot ensemble
snapshot ensemble 是一个简单通用的提分trick,通过余弦周期退火的学习率调整策略,保存多个收敛到局部最小值的模型,通过模型自融合提升模型效果。详细的实验和实现可以看黄高老师ICLR 2017的这篇论文。

snapshot ensemble 另一个作用是作新方案的验证。深度学习训练的结果具有一定的随机性,但比赛中提交次数有限,无法通过多次提交来验证实验结果。在做新方案改进验证时,有时难以确定线上分数的小幅度提升是来自于随机性,还是改进方案really work。在比赛提交次数有限的情况下,snapshot ensemble不失为一个更加稳定新方案验证的方法
3.4 后处理
训练数据中,对于农田中出现的碎石、树木,比赛数据提供的标注仍是农田。但推理阶段,模型是可以正常预测这些碎石、树木的情况的,因此部分预测结果中出现了较多孔洞。
针对本次赛题数据场景为大面积农田预测,通过简单的填充孔洞、去除小连通域等后处理,可以去除一些不合理的预测结果。

3.5 边缘平滑
边缘平滑想法受Hinton大神关于的知识蒸馏和When does label smoothing help?的工作启发,从实验看标签平滑训练的模型更加稳定和泛化能力更强。
在知识蒸馏中,用teacher模型输出的soft target训练的student模型,比直接用硬标签(onehot)训练的模型具有更强的泛化能力。我对这部分提升理解是:软标签更加合理反映样本的真实分布情况,硬标签只有全概率和0概率,太过绝对。知识蒸馏时teacher模型实现了easy sample 和 hard sample 的“分拣”(soft-target),对hard sample输出较低的置信度,对easy sample 输出较高的置信度,使得student模型学到了更加丰富的信息。

图3-5截取自When does label smoothing help?,第一行至第四行分别为CIFAR10、CIFAR100、ImageNet(Course)、ImageNet(fine) 的数据集上训练的网络倒数第二层输出可视化,其中第一列为硬标签训练的训练集可视化,第二列为硬标签训练的测试集可视化,第三列为软标签训练的训练集可视化,第四列为软标签训练的测试集可视化,可以看出软标签训练的模型类内更加凝聚,更加可分。
我们重新思考3.1中方格效应,在图像分割任务中,每个像素的分类结果很大程度依赖于周围像素,图像中不同像素预测的难易程度是不同的。分割区别于分类,即使不通过teacher模型,我们也可以发掘部分样本中的hard sample。本次比赛中我们主要考虑了以下两类数据:
图像边缘:卷积时零填充太多,信息缺少,难以正确分类(参考3.1的方格效应)
不同类间交界处:
标注错误,类间交界难以界定,训练时可能梯度不稳定
类间交界的点,往往只相差几个像素偏移,对网络来说输入信息高度相似,但训练时label 却不同,也是训练过程的不稳定因素。

为验证这一想法,我们分别对模型预测结果及置信度进行可视化。图3-7中,从上到下分别为测试集原图、模型预测结果可视化、模型预测置信度可视化(为更好可视化边类间缘置信度低,这里用了膨胀预测,将置信度p<0.8可视化为黑色,p>=0.8可视化为白色)。可以明显看出,对于图像边缘数据,信息缺失网络难以作出正确分类。对于不同类别交界,由于训练过程梯度不稳定,网络对这部分数据的分类置信度较低。
我们采取的方式是在图像边缘和类间交界设置过渡带,过渡带内的像素视为 hard sample作标签平滑处理,平滑的程度取决于训练时每个batch中 hard sample (下图黑色过渡带区域)像素占总输入像素的比例。而过渡带w的大小为一个超参数,在本次比赛中我们取w=11。

3.6 伪标签
地形泛化问题也是本次赛题数据一个难点,训练集中数据大多为平原,对测试集数据中山地、碎石带、森林等泛化效果较差。我们采用半监督的方式提高模型对新地形泛化能力。

在模型分数已经较高的情况下可以尝试伪标签进行半监督训练,我们在A榜mIoU-79.4时开始制作伪标签,具体实施是:
利用在测试集表现最好的融合模型结果作伪标签,用多组不同置信度阈值过滤数据,结合训练集训练模型;
选取多个snapshot的方法对模型进行自融合提高模型的泛化能力;
集成2中的预测结果,更新伪标签,重复步骤1~3。
伪标签方法提分显著,但对A榜数据过拟合的风险极大。即使不用伪标签,我们的方案在A榜也和第二名拉开了较大差距。在更换B榜前,我们同时准备了用伪标签和不用伪标签的两套模型。
4 总结
膨胀预测消除边缘预测不准问题;
使用测试增强、消除空洞和小连通域等后处理提高精度;
使用snapshot模型自融合、标签平滑、伪标签等方法提高模型稳定性和对新地形泛化能力;
机器学习算法AI大数据技术
搜索公众号添加: datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx