
不用PS一键去除照片中的对象,三星用傅里叶卷积实现「万物隐身」,这个神器可试玩
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
机器之心报道
编辑:杜伟、陈萍
将快速傅里叶卷积引入网络架构,弥补感受野不足的缺陷,来自三星、洛桑联邦理工学院等机构的研究者提出了 LaMa(large mask inpainting)方法,在一系列数据集上改进了 SOTA 技术。
现代图像修复(Modern image inpainting)系统尽管取得了长足的进步,但往往难以处理大面积的缺失区域、复杂的几何结构和高分辨率图像。研究人员发现造成这种情况的主要原因之一是修复网络和损失函数都缺乏有效的感受野。
大的有效感受野对于理解图像的全局结构并因此解决修复问题至关重要。此外,即使掩码足够大,但有限的感受野可能不足以获得模型生成质量修复所需的信息。
为了解决这一问题,来自三星、洛桑联邦理工学院等机构的研究者提出了一种新方法,LaMa(large mask inpainting)。LaMa 基于(1)一种使用了快速傅里叶卷积的修复网络架构,该架构具有较宽的图像感受野;(2)高感受野感知损失;(3)较大的训练掩码,可以释放前两个组件的潜力。
该研究提出的修复网络在一系列数据集上改进了 SOTA 技术,即使在具有挑战性的情况下也能实现出色的性能。此外,该模型还可以很好地泛化到比训练时更高的分辨率图像,以较低的参数量和计算成本实现与基准相媲美的性能。

论文地址:https://arxiv.org/pdf/2109.07161.pdf
GitHub 地址:https://github.com/saic-mdal/lama
这项研究在 reddit 上可谓火爆:

它的效果是这样的,从功能上来讲,假如作为 PS 插件,应该会很酷:


这里,我们也试玩了一下,输入一张小猫咪的图像,提交之后,处理后的效果如图右上所示,右下是图像被处理掉的部分:
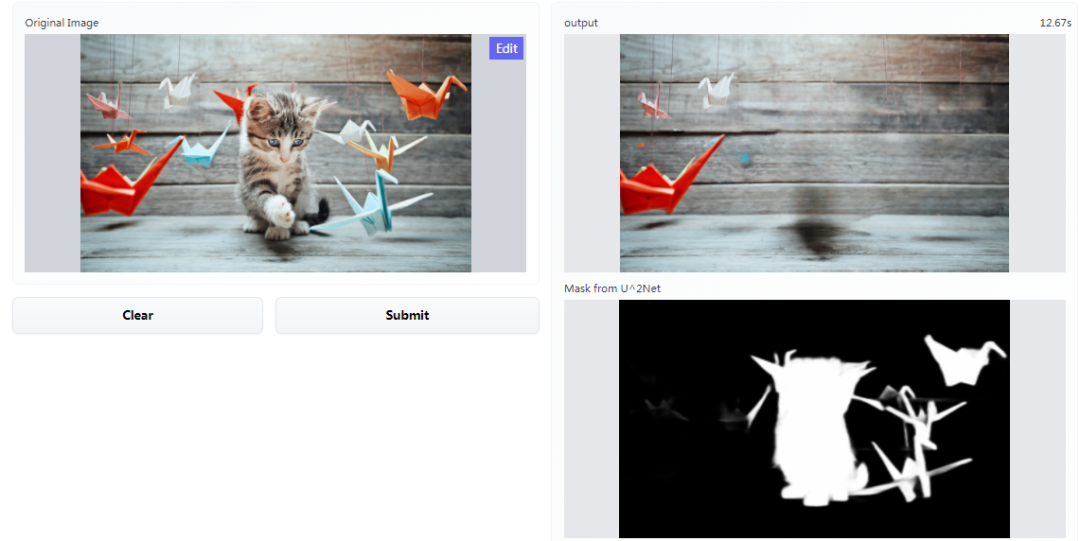
试玩地址:https://huggingface.co/spaces/akhaliq/lama
不过处理后的图像看起来会留下伪影,正如网友所疑问的:是我一个人还是大家都这样,修复的图像在背景区域会留下轻微的黑色。

但这也不妨碍这项研究的贡献,虽然处理效果还不是很完美,但它仍然是最出色的那一个。

技术细节
早期层中的全局背景
最近提出的快速傅里叶卷积(Fourier convolution)方法可以在早期层中使用全局背景。傅里叶卷积层基于层级的快速傅里叶变换(FFT),并具有覆盖整个图像的 image-wide 感受野。
傅里叶卷积层将通道分割为两个并行的分支:使用常规卷积的局部分支和使用 Real FFT 来处理全局背景的全局分支。Real FFT 只可用于实值信号(real valued signal),同时 niReal FFT 确保输入也是实值。值得注意的是,Real FFT 仅使用 FFT 一半的谱。
具体地,快速傅里叶卷积层通过以下步骤来处理全局背景:

最终,局部(i)和全局(ii)分支的输出融合在一起。图 2(左)为该研究提出的 LaMa,图(中)为快速傅里叶卷积,图(右)为谱变换。
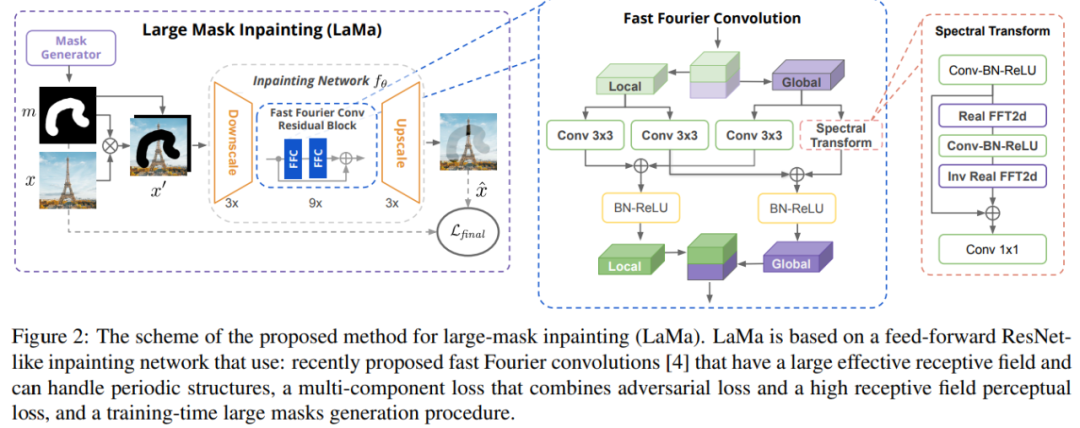
相较于常规卷积,傅里叶变换完全可微,并且嵌入式方式易于使用。得益于覆盖整个图像的 image-wide 感受野,傅里叶卷积使得生成器网络可以从早期层处理全局背景,这对于高分辨率的图像修复至关重要。
傅里叶卷积的另一个益处是它有能力捕获人造环境中很常见的周期性结构,如砖块、梯子和窗户等。有趣的是,在所有频数上共享相同的卷积使得模型转向尺度协方差(scale covariance)。
损失函数
图像修复问题具有内在的模糊性。同一个缺失区域可以有很多看似可信的填充,特别是当 hole 变得更宽时。研究者提出的损失涵盖包含以下三个重要的组件,它们结合在一起解决了这一问题:
高感受野感知损失
对抗损失
最终损失函数
训练中掩码的生成
修复系统的最后一个组件是掩码生成策略。每个训练样本 x’都是训练集中的真实照片,由综合生成的掩码叠加而成。与判别式模型中数据扩增对最终性能具有重大影响类似,研究者发现掩码生成策略显著影响了修复系统的性能。
因此,他们选择使用激进的大掩码(large mask)生成策略,该策略使用来自由随机高度(宽掩码,wide mask)和任意长宽比矩形(box mask)组成的多边形链中的样本。具体如下图 3 所示:

研究者在几种方法中都进行了大(large )和窄(narrow)掩码训练测试,结果发现使用大掩码策略的训练在窄和宽掩码上通常都可以提升性能。这表明,增加掩码的多样性对不同的图像修复系统都有益。
实验展示
该研究将 LaMa 方法与其他强基线方法进行了对比,结果如表 1 所示。对于每一个数据集,该研究验证了窄掩码(narrow mask)、宽掩码( wide mask)和基于分割掩码(segmentation-based mask)性能。由结果可得使用快速傅里叶卷积的 LaMa 始终优于大多数基线方法,同时比最强的竞争对手拥有更少的参数:
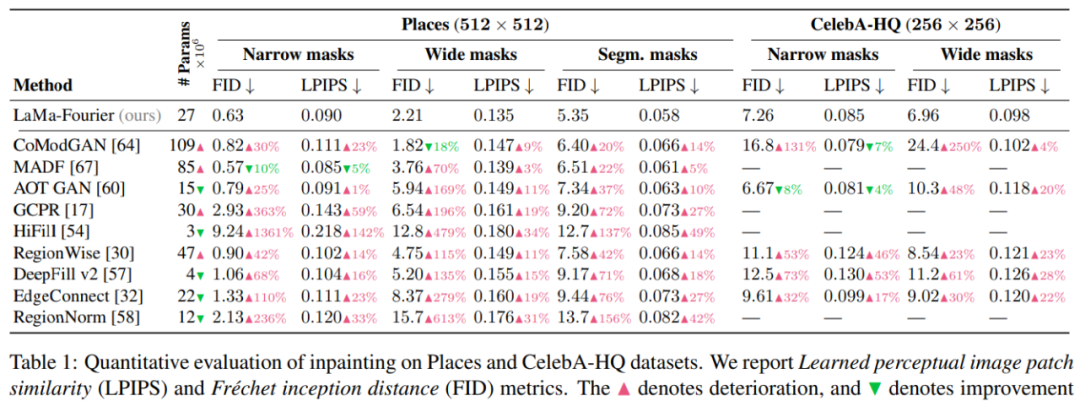
为了减少被选择的指标可能带来的偏差,研究人员还进行了一项 crowdsourced 用户研究。用户研究结果与定量评价结果具有良好的相关性,表明该方法比其他方法更优且更不易检测。
消融研究
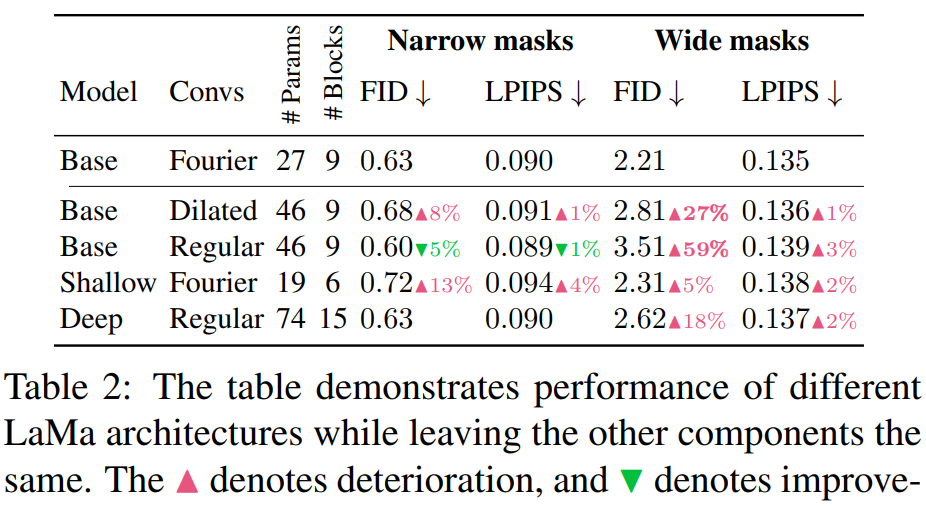
消融实验展示了 Places 数据集的结果。快速傅里叶卷积增加了系统的有效感受野。添加快速傅里叶卷积极大地提高了宽掩码的 FID 评分,如表 2 所示:
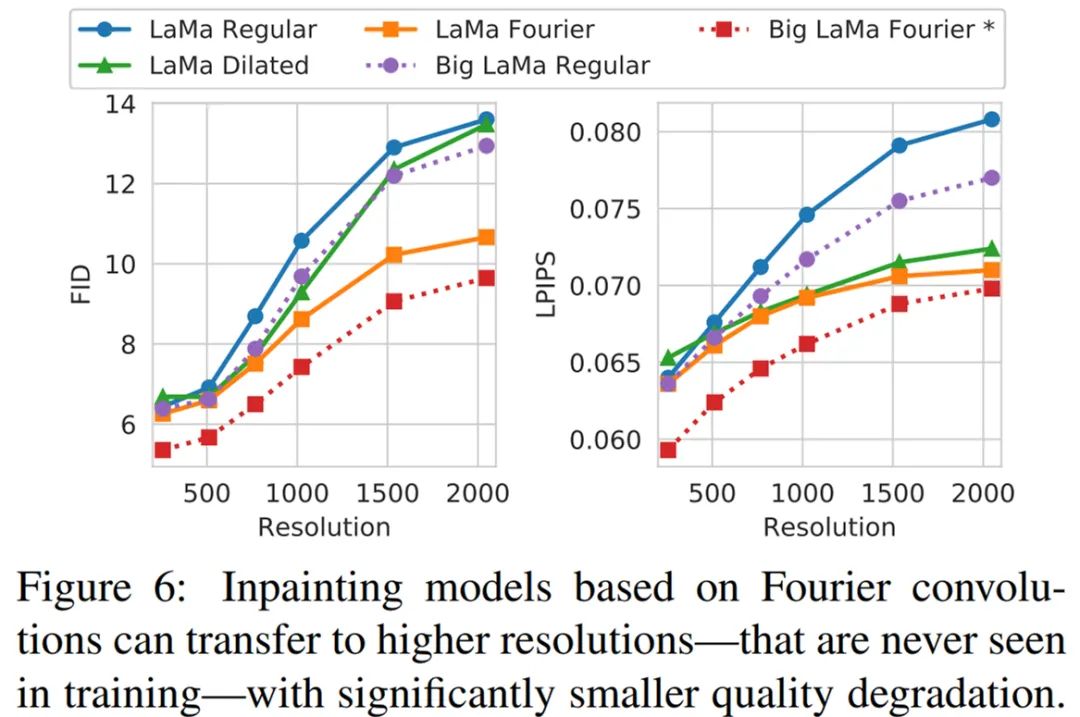
当模型应用于比训练更高的分辨率时,感受野的重要性最为明显。如图 5 所示,在没有傅里叶卷积的情况下,当分辨率增加到超过训练时使用的分辨率时,模型会产生明显的伪影。图 6 定量验证了相同的效果:

傅里叶卷积还可以更好地生成重复结构,例如图 4 窗口。有趣的是,LaMa-Fourier 仅比 LaMa-Regular 慢 20%,而模型小 40%。

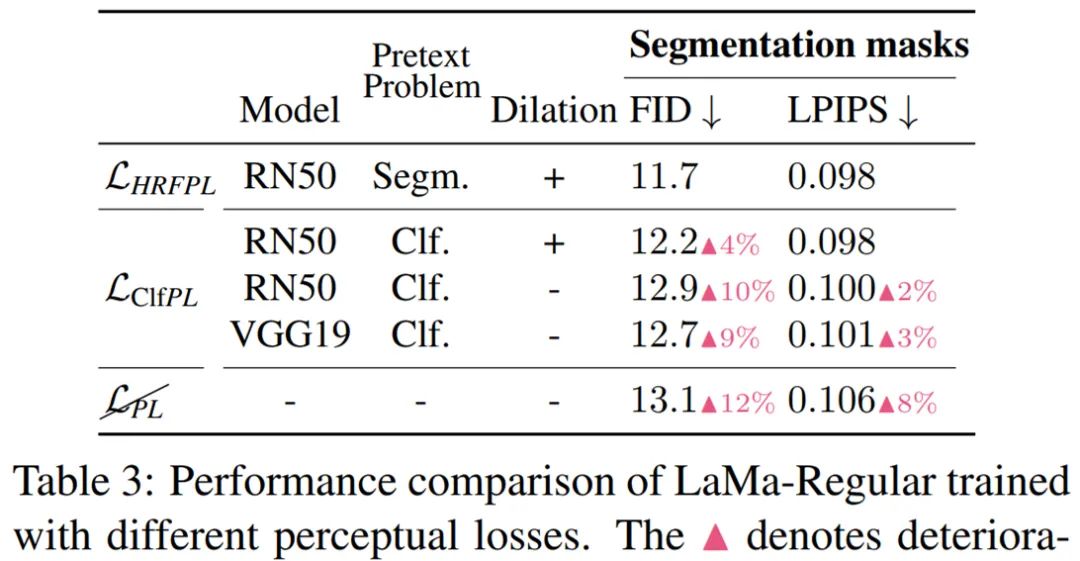
研究者还验证了感知损失的高感受野设计——用空洞卷积(Dilated convolutions)实现,结果表明这种方法确实提高了修复的质量,如表 3 所示:
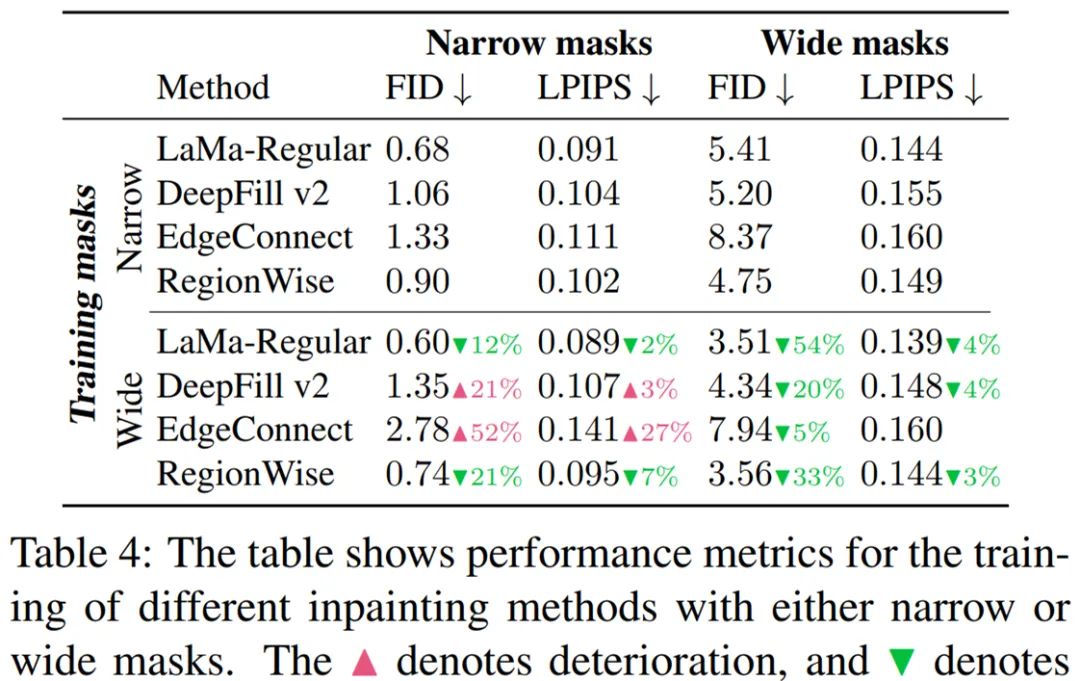
更宽的训练掩码改善了 LaMa 和 RegionWise 在窄和宽 hole 上的修复,如表 4 所示:
直接在高分辨率上训练速度很慢,并且计算昂贵。即使这样,大多数真实世界的图像编辑场景需要模型在高分辨率数据上表现良好。因此,研究者在 512×512 图像的 256 × 256 crop 上训练模型,并在更大的图像上对模型进行评估。他们以全卷积的形式使用模型,即不用任何 patch-wise 操作在单通道上处理完整的图像。傅里叶卷积可以迁移至比常规卷积明显更高的分辨率。具体如下图 6 所示:
最后,为了验证 LaMa 方法对真实高分辨率图像的扩展性和适用性,研究者使用更多的资源训练了大规模修复 Big LaMa 模型。Big LaMa 在以下三个方面不同于标准 LaMa 模型,分别是生成器网络深度、训练数据集和批大小。Big LaMa 具有 18 个残差块,都基于快速傅里叶卷积,参数量为 5100 万。该模型在 Places-Challenge 数据集中一个包含 450 万张图像的子集上进行训练,只在大约 512×512 图像的低分辨率 256×256 crop 上训练,批大小为 120(标准模型为 30)。最终,Big LaMa 模型在 8 块英伟达 V100 GPU 上训练了将近 240 个小时。
参考链接:
https://www.reddit.com/r/MachineLearning/comments/q97fpv/r_resolutionrobust_large_mask_inpainting_with/
转自:机器之心
—版权声明—
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!
—THE END—
评论