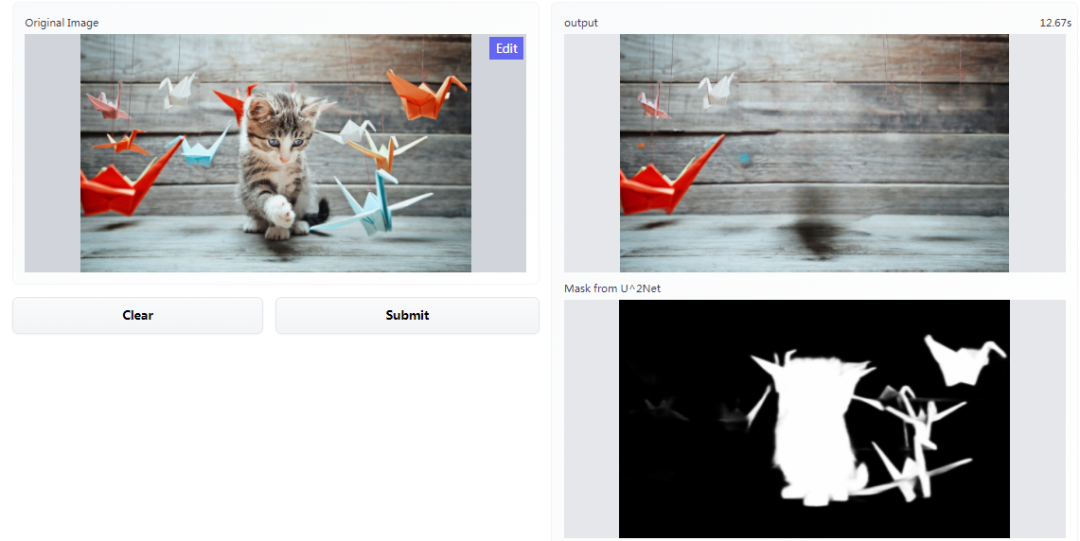
GitHub 热榜:不用 PS,一键去除照片中的对象,这个神器可试玩
来自机器之心

论文地址:https://arxiv.org/pdf/2109.07161.pdf
GitHub 地址:https://github.com/saic-mdal/lama






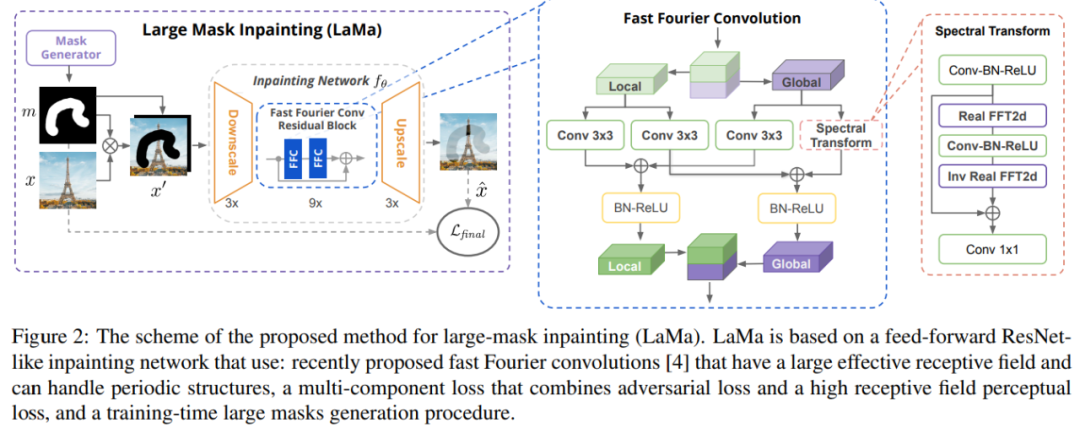
高感受野感知损失
对抗损失
最终损失函数

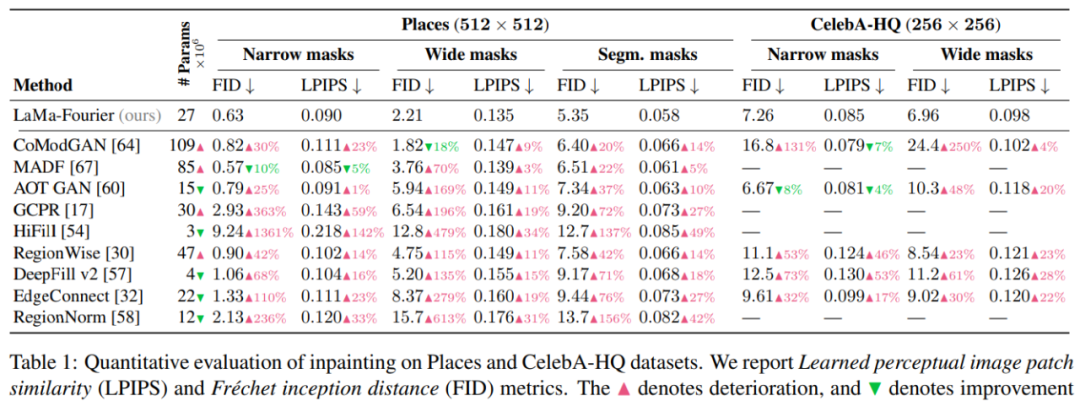
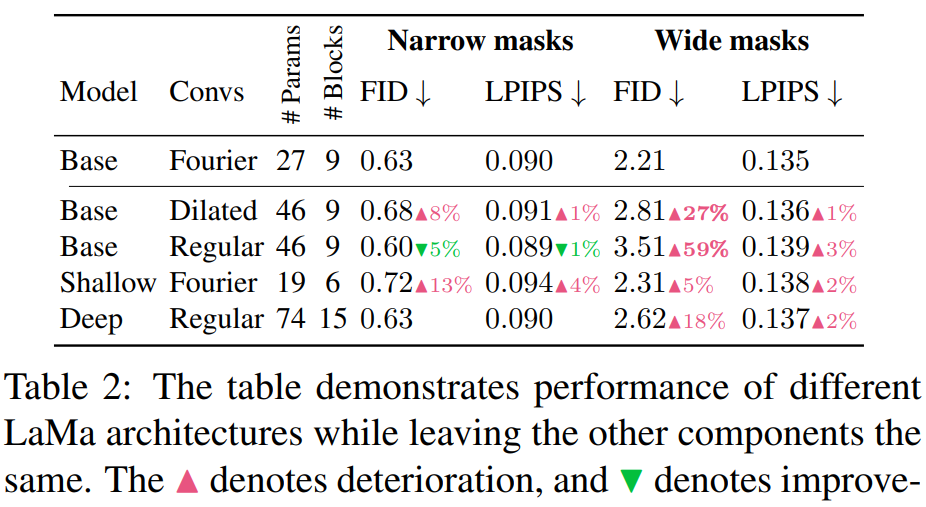


评论
 下载APP
下载APP来自机器之心
论文地址:https://arxiv.org/pdf/2109.07161.pdf
GitHub 地址:https://github.com/saic-mdal/lama
高感受野感知损失
对抗损失
最终损失函数