
来自机器之心
现代图像修复(Modern image inpainting)系统尽管取得了长足的进步,但往往难以处理大面积的缺失区域、复杂的几何结构和高分辨率图像。研究人员发现造成这种情况的主要原因之一是修复网络和损失函数都缺乏有效的感受野。



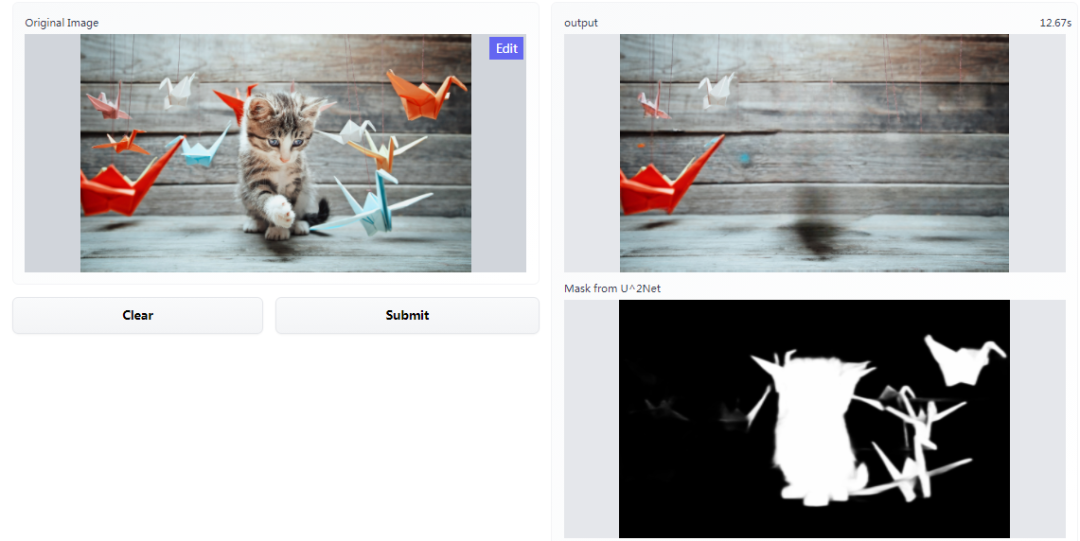
不过处理后的图像看起来会留下伪影,正如网友所疑问的:是我一个人还是大家都这样,修复的图像在背景区域会留下轻微的黑色。
但这也不妨碍这项研究的贡献,虽然处理效果还不是很完美,但它仍然是最出色的那一个。
技术细节

最终,局部(i)和全局(ii)分支的输出融合在一起。图 2(左)为该研究提出的 LaMa,图(中)为快速傅里叶卷积,图(右)为谱变换。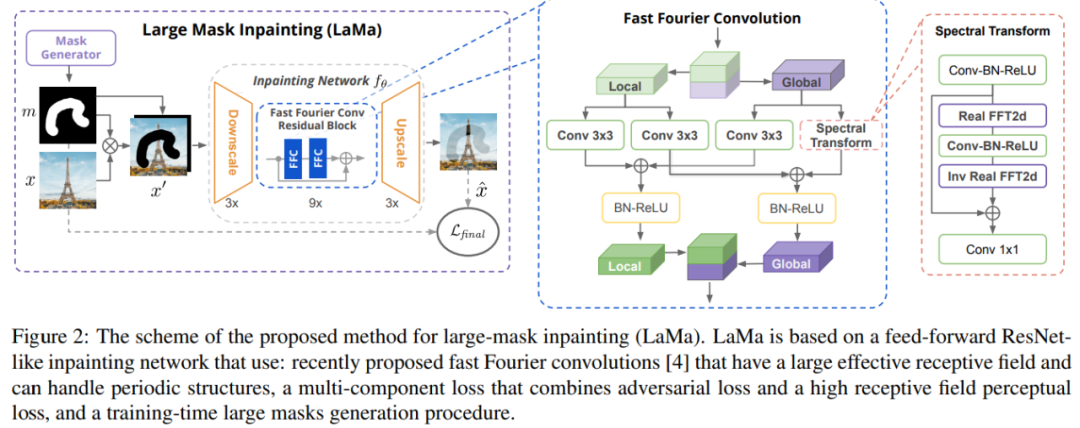
相较于常规卷积,傅里叶变换完全可微,并且嵌入式方式易于使用。得益于覆盖整个图像的 image-wide 感受野,傅里叶卷积使得生成器网络可以从早期层处理全局背景,这对于高分辨率的图像修复至关重要。傅里叶卷积的另一个益处是它有能力捕获人造环境中很常见的周期性结构,如砖块、梯子和窗户等。有趣的是,在所有频数上共享相同的卷积使得模型转向尺度协方差(scale covariance)。图像修复问题具有内在的模糊性。同一个缺失区域可以有很多看似可信的填充,特别是当 hole 变得更宽时。研究者提出的损失涵盖包含以下三个重要的组件,它们结合在一起解决了这一问题:修复系统的最后一个组件是掩码生成策略。每个训练样本 x’都是训练集中的真实照片,由综合生成的掩码叠加而成。与判别式模型中数据扩增对最终性能具有重大影响类似,研究者发现掩码生成策略显著影响了修复系统的性能。因此,他们选择使用激进的大掩码(large mask)生成策略,该策略使用来自由随机高度(宽掩码,wide mask)和任意长宽比矩形(box mask)组成的多边形链中的样本。具体如下图 3 所示:
实验展示
该研究将 LaMa 方法与其他强基线方法进行了对比,结果如表 1 所示。对于每一个数据集,该研究验证了窄掩码(narrow mask)、宽掩码( wide mask)和基于分割掩码(segmentation-based mask)性能。由结果可得使用快速傅里叶卷积的 LaMa 始终优于大多数基线方法,同时比最强的竞争对手拥有更少的参数: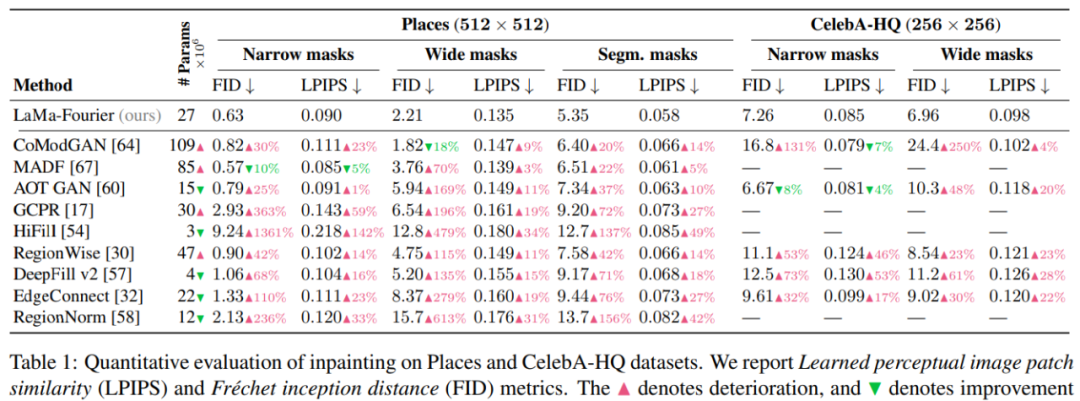
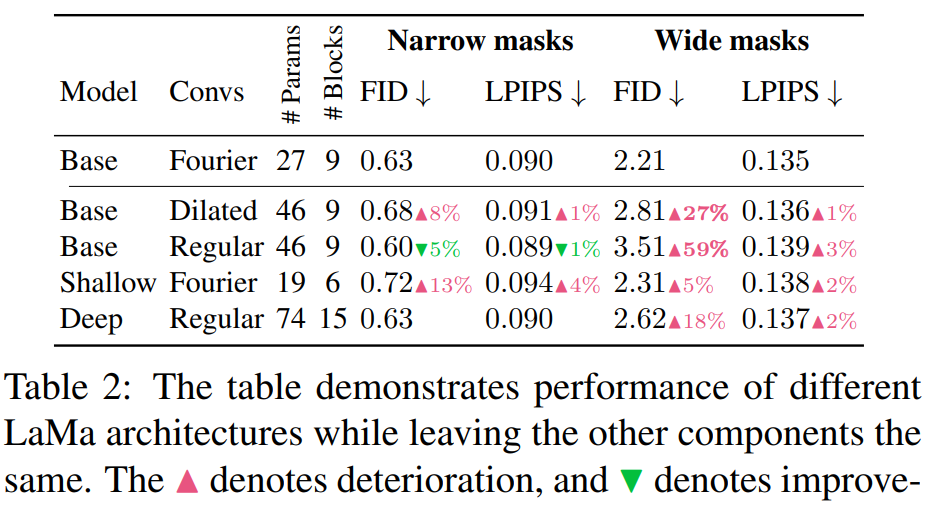

傅里叶卷积还可以更好地生成重复结构,例如图 4 窗口。有趣的是,LaMa-Fourier 仅比 LaMa-Regular 慢 20%,而模型小 40%。
研究者还验证了感知损失的高感受野设计 —— 用空洞卷积(Dilated convolutions)实现,结果表明这种方法确实提高了修复的质量,如表 3 所示: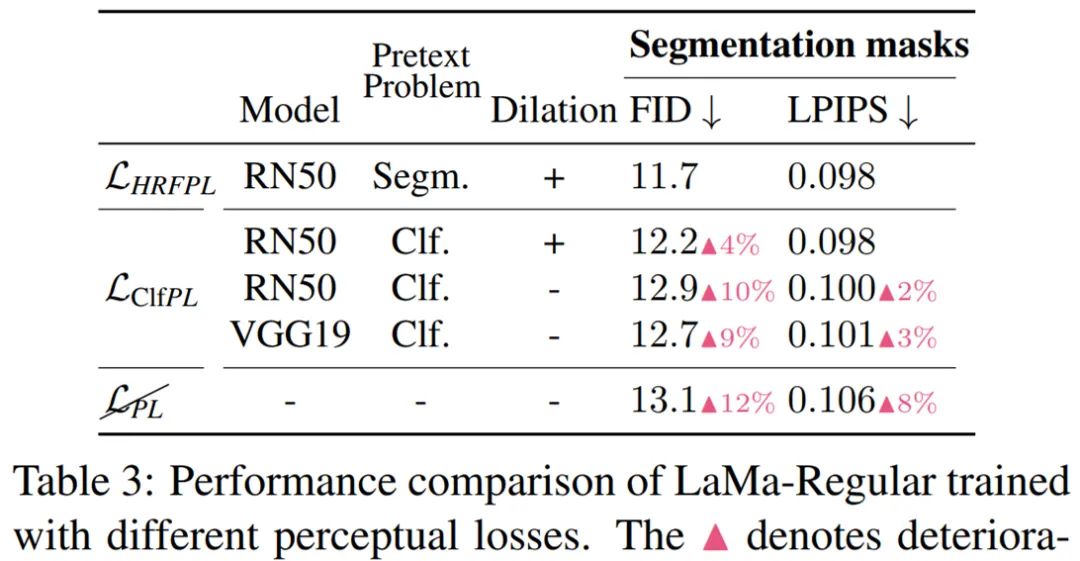
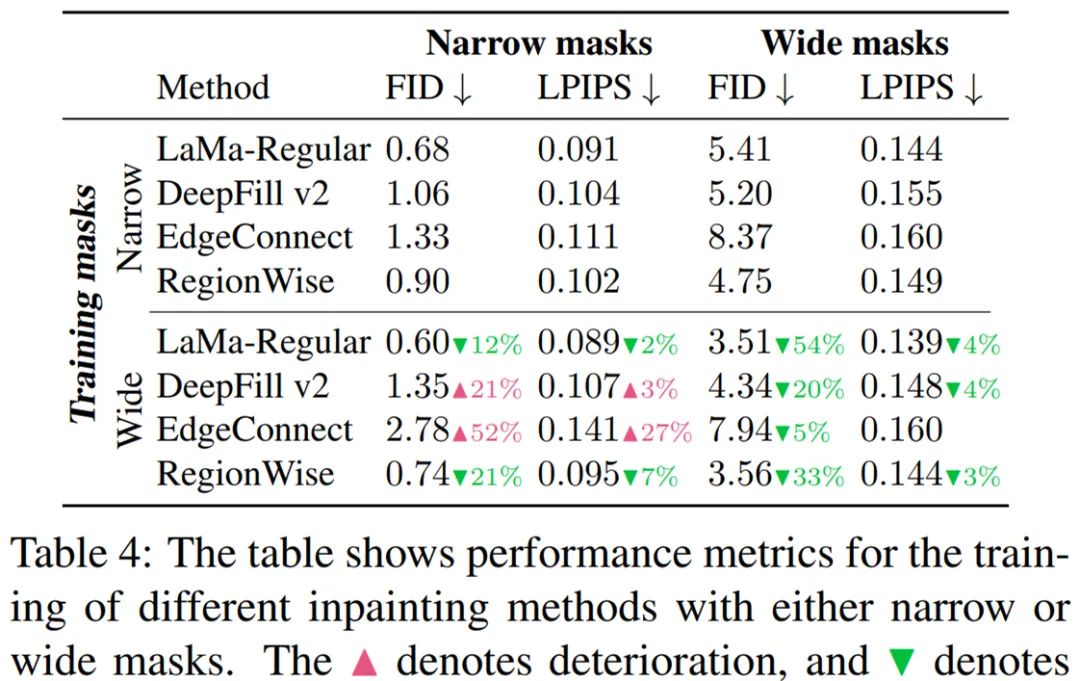
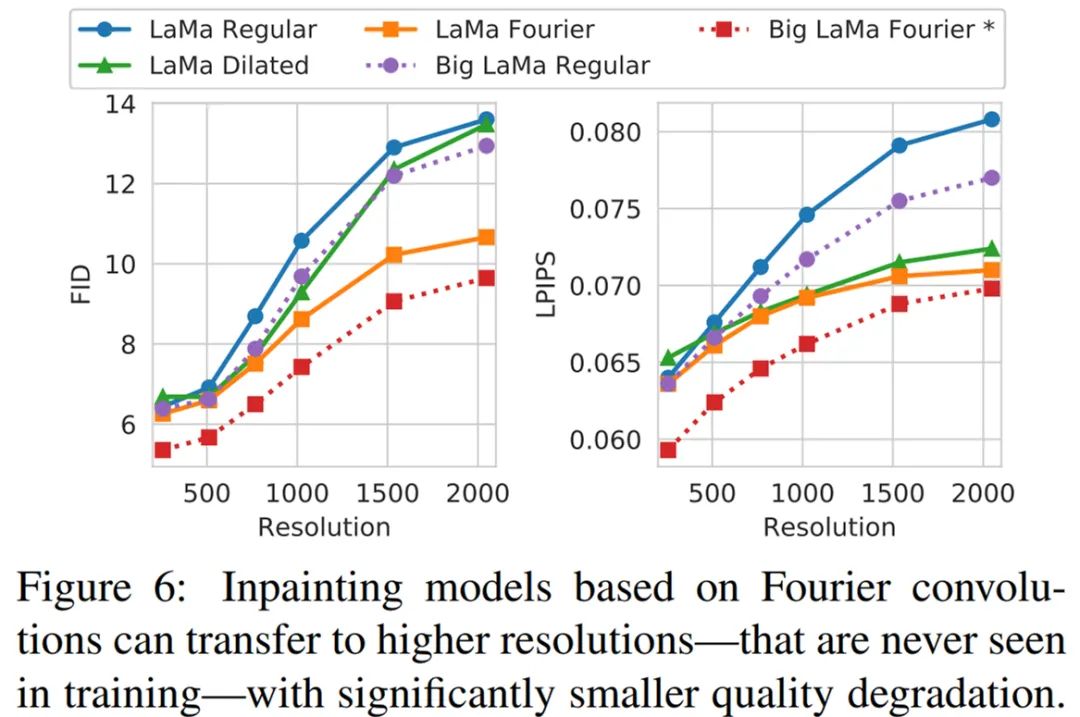
最后,为了验证 LaMa 方法对真实高分辨率图像的扩展性和适用性,研究者使用更多的资源训练了大规模修复 Big LaMa 模型。Big LaMa 在以下三个方面不同于标准 LaMa 模型,分别是生成器网络深度、训练数据集和批大小。Big LaMa 具有 18 个残差块,都基于快速傅里叶卷积,参数量为 5100 万。该模型在 Places-Challenge 数据集中一个包含 450 万张图像的子集上进行训练,只在大约 512×512 图像的低分辨率 256×256 crop 上训练,批大小为 120(标准模型为 30)。最终,Big LaMa 模型在 8 块英伟达 V100 GPU 上训练了将近 240 个小时。感谢您的阅读,也欢迎您发表关于这篇文章的任何建议,关注我,技术不迷茫!小编到你上高速。
最后,关注公众号互联网架构师,在后台回复:2T,可以获取我整理的 Java 系列面试题和答案,非常齐全。

 下载APP
下载APP