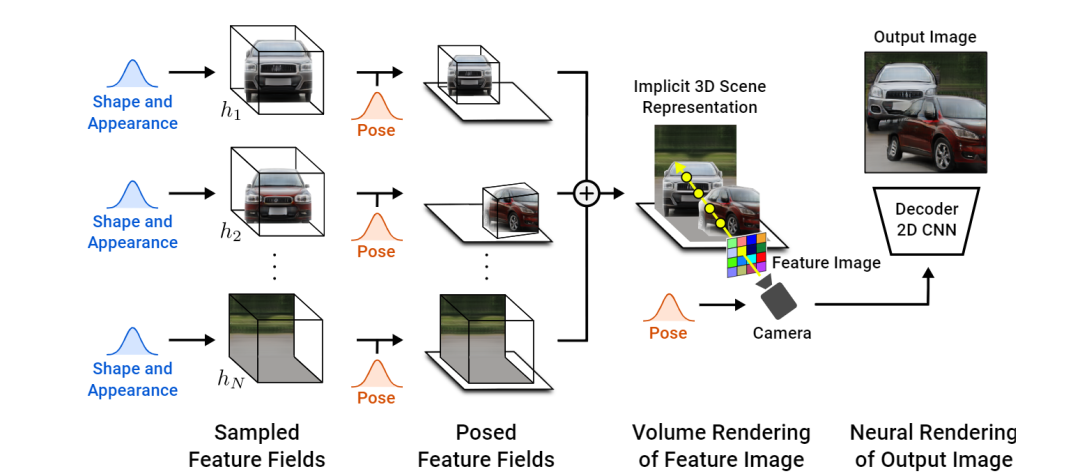
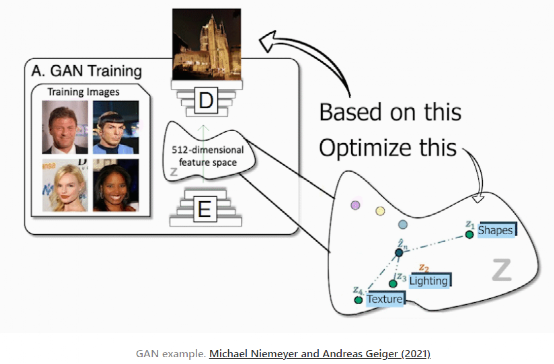
CVPR 2021 年度最佳论文奖,颁发给了来自德国马克斯 - 普朗克研究所(Max Planck Institute)的 Michael Niemeyer 和蒂宾根大学(Tubingen)的 Andreas Geiger。这篇名为 “GIRAFFE: representation Scenes as composition Generative Neural Feature Fields” 的论文,提出了一个基于学习的、完全可微的渲染引擎 GIRAFFE,可以用于将场景合成为多个 “特征域” 的综合,完成可控图像的合成任务。换句话说,该任务着眼于生成新的图像并控制将要出现的内容、对象及其位置和方向、背景等等。使用改进的 GAN 架构,他们甚至可以在不影响背景或其他对象的情况下移动图像中的对象。传统的 GANs 架构使用下图的编码器和解码器设置。在训练过程中,编码器接收图像后将其编码为对应的压缩表征(condensed representation),随后解码器利用此表征来创建一个改变样式的新图像。而该团队在训练数据集中将所有的图像重复多次,以便编码器和解码器学习如何在训练阶段最大化所要实现任务的结果。一旦训练完成,你任意发送一张图像到编码器,它会进行同样的过程,按你的需求生成一张新的且未知的图像。无论何种任务,它的工作原理都非常相似,不论是把一张脸的图像转换成如卡通形象般的别样风格,还是用草图创作出一幅美丽的风景。仅使用解码器(decoder)(考虑到它是创作新图像的模型,也将其称为生成器),便可实现在这个编码信息空间中游走,并向生成器发送样本信息,以生成无限量的新图像。团队成员将这种被编码的信息空间称为潜在空间(latent space),而用来生成新图像的信息称为潜码(latent code)。在任务的实现过程中,基本上选择在最优空间内随机选择一些潜码,然后在遵循生成器的训练过程的前提下,根据任务的预期目标生成一个新的随机图像。这真是令人难以置信,但正如刚才所说的,图像是完全随机的,我们没有或很少有想法,它会是什么样子,这已经是非常少的有用的创造者了。实际上,通过获取物体形状和外观的潜码并将其发送给解码器或生成器,他们便能够控制物体的姿态,这意味着可以进行物体的移动,改变物体的外观,添加其他对象,改变背景,甚至改变相机的姿势。所有的这些转换都可以在每个对象或背景上独立完成,而不影响图像中的任何其他内容。如你所见,这种方法比其他基于 GAN 的方法要好得多,这些方法仅停留在 2D 图像世界中,通常无法将对象彼此分离,并且都受到特定对象修改的影响。而文中方法的不同之处在于,提供了一种模块化的框架,以完全可微且可学习的方式从对象中构建和组成 3D 场景。但除此之外,过程非常相似:编码信息,识别对象,在潜在空间中进行编辑,然后解码生成新的图像。在这里,还有很多步骤需要在潜在空间中完成。研究团队将其视为经典 GANs 图像合成网络与神经渲染器(neural renderer)的结合,其中,正如我们所见,神经渲染器用于从发送到网络的图像生成 3D 场景。实现这一目标主要有以下三个步骤。需要注意的是,编码输入图像后则意味着已处于潜在空间之中。这并非是简单的 3D 场景,而是一个由 3D 元素组成的 3D 场景,即对象和背景。这种将图像视为由生成的体渲染图组成的场景的方式允许它们在生成的图像中改变摄像机位,并独立地控制对象。这是使用一个与先前论文中出现的类似的模型 NERV 来实现的,但不是使用一个单一的模型来从输入图像生成整个锁定的场景,而是采用两个单独的模型独立生成对象和背景,这里称做采样特征域(Sampled Feature Fields)。该网络的参数也在训练过程中学习。至于细节方面,它非常类似于先前文章中提到的 NERF。第二步:编辑区域。具备了带有分离元素的场景,便可以单独编辑它们而不影响图像的其余部分。当然,他们可以对物体做任何想做的操作,比如改变其位置和方向。换句话说,他们改变了对象或背景的姿态。在这一点上,甚至可以添加新的对象放置在其想要的任何方位。然后,通过把所有的特征字段添加到一起,将它们简单地组合到涵盖所有对象和背景的最终 3D 场景中。由于当前阶段仍处于 3D 世界中,团队可以通过改变摄像机的视角来决定如何看待场景。然后,根据该相机光线和其他参数(如 alpha 值和透射率)来评估每个像素。这就得到了所谓的特征图像,但这个特征图像是由每个像素的特征向量组成的图像。因为处于潜在性空间之中,这些特征需要转换成 RGB 颜色和高分辨率图像。这是使用典型的解码器来完成的,就像其他 GANs 架构一样,将其放大到原始尺寸,同时学习 RGB 通道的特征转换。由此,你可以对生成的内容进行更多的控制。当然,正如你所看到的,落地到真实数据中时仍然是不完美的。尽管如此,这项工作仍然让人印象深刻,它是朝着正确方向迈出的重要一步,特别是考虑到这些都是由 GANs 生成的合成图像,并且这是第一篇能够将生成图像控制在这种精度水平的论文。GIRAFFE 堪称是对近期 NERF 和 GANs 相关领域的一个令人兴奋的研究,在此强烈推荐读者朋友们可以下载论文阅读,以具体了解他们的模型是如何工作的(作者公众号“数据实战派” 后台回复 “CVPR”,即可获得论文下载链接)。
 下载APP
下载APP