
CVPR2021 最佳论文 Giraffe,当之无愧的最佳,或开创新的篇章
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
https://github.com/autonomousvision/giraffe
http://www.cvlibs.net/publications/Niemeyer2021CVPR.pdf报告链接:https://www.bilibili.com/video/BV1TX4y1P7ou/
大家好,以后我将开一个新的系列,这个系列的内容,主要是从发过顶会的大佬们公开的报告中总结(大部分都是英文的),计划将一些优秀的工作报告视频,整理成图文,供大家一起学习。一起学习顶会大佬们如何做研究,如何分析问题,解决问题,并验证结果的正确性以及宣传包装自己的科研成果 (highlight 创新点)。
计划更新频率一周一篇  求分享,求点赞支持,一起努力做一个 合格的算法工程师!
求分享,求点赞支持,一起努力做一个 合格的算法工程师!

解读汇总:
密集场景下的行人跟踪替代算法,头部跟踪算法 | CVPR 2021

主要内容
CVPR 2021年度最佳论文奖颁发给Michael Niemeyer和Andreas Geiger,来自Max普朗克智能系统研究所和蒂宾根大学,他们的论文叫做Giraffe,它负责可控图像合成的任务。换言之,他们着眼于生成新的图像和控制将要出现的内容、对象及其位置和方向、背景等。使用改进的GAN架构,他们甚至可以在不影响背景或其他对象的情况下移动图像中的对象!CVPR是最近刚刚召开的一个年度会议,会上发表了大量有关计算机视觉的新研究论文。


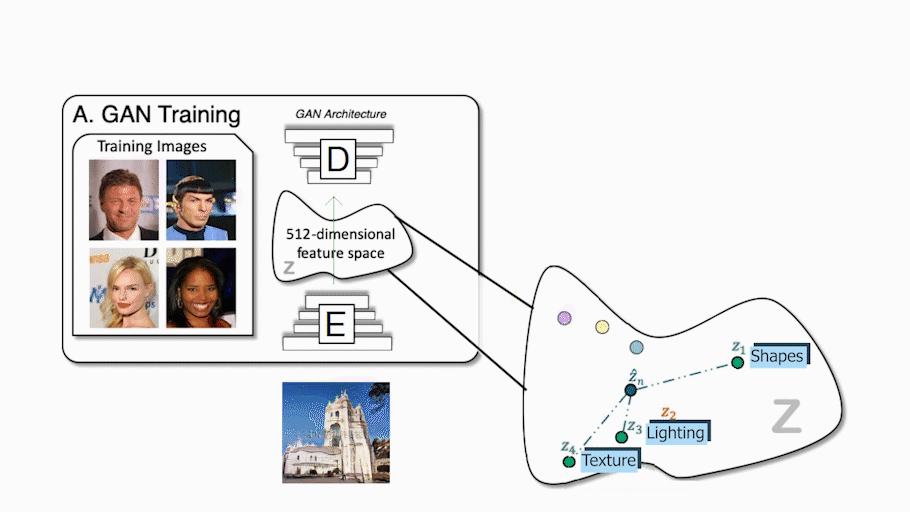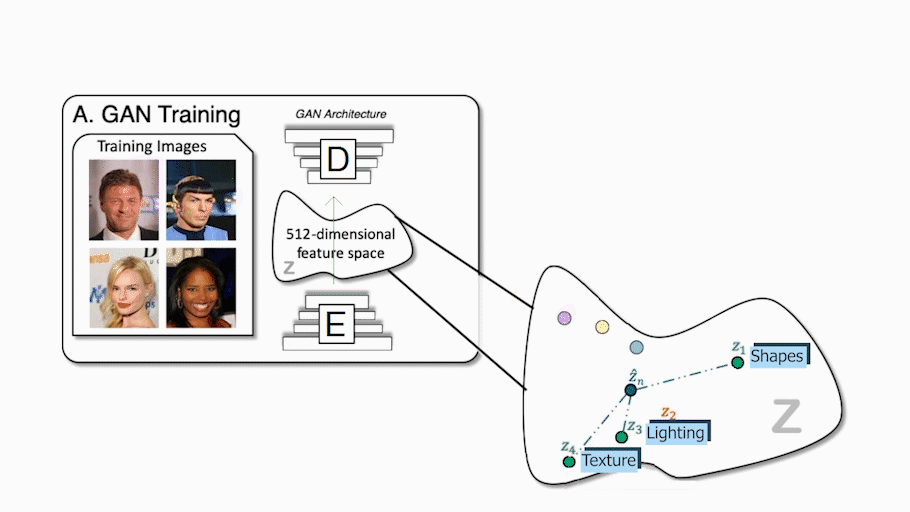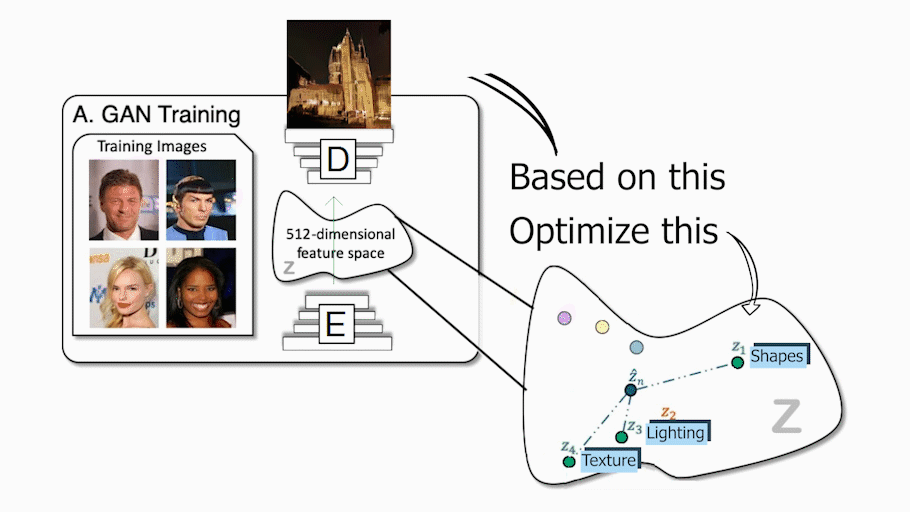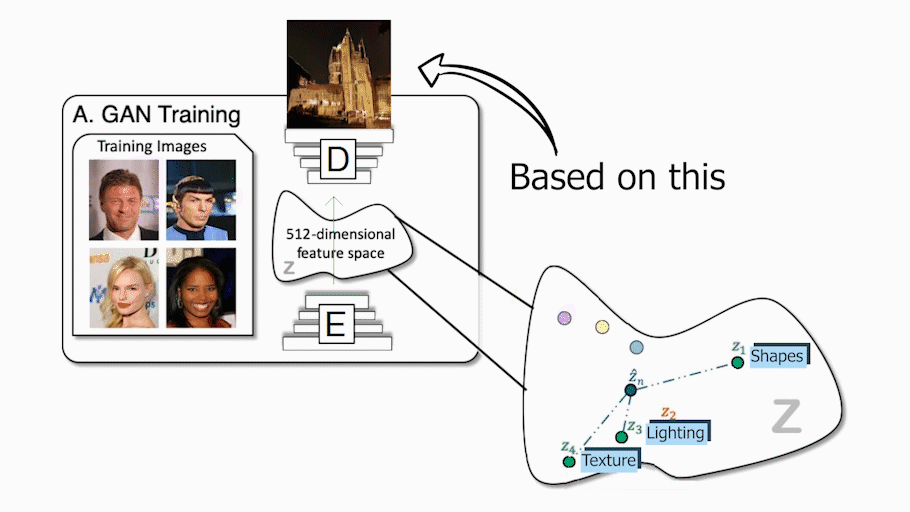
传统的GAN架构使用编码器和解码器设置,就像下图这样。在训练过程中,编码器接收一个图像,将其编码成一个压缩的表征,解码器利用这个表征来创建一个改变样式的新图像。在我们的训练数据集中的所有图像中重复多次,以便编码器和解码器学习如何在训练期间最大化我们想要实现的任务的结果。一旦训练完成,你可以发送一个图像到编码器,它会做同样的过程,生成一个新的和看不见的图像,根据你的需要。无论做什么工作,它都会起到非常相似的作用,不管是把一张脸的图像翻译成卡通画家那样的另一种风格,还是用草图创造出一幅美丽的风景。仅使用解码器,我们也称之为生成器,因为它是负责创建新图像的模型,我们可以在这个编码信息空间中行走,并对发送给生成器的信息进行采样,以生成无限量的新图像。这种编码的信息空间通常被称为潜在空间,而我们用来生成新图像的信息就是潜在代码。我们基本上是在这个最优空间内随机选择一些潜在的代码,然后它会根据我们想要完成的任务生成一个新的随机图像,当然,也会遵循这个生成器的训练过程。这是难以置信的酷,但正如我刚才所说,图像是完全随机的,我们没有或很少的想法,它看起来像什么,这已经是一个非常少有用的创造者。
这就是他们用这篇论文解决的问题。实际上,通过获取物体形状和外观的潜在代码并将其发送给解码器或生成器,他们能够控制物体的姿势,这意味着他们可以移动物体,改变物体的外观,添加其他物体,改变背景,甚至改变相机的姿势。所有这些变换都可以在每个对象或背景上独立完成,而不会影响图像中的任何其他内容!

如你看到的那样子,它比其他基于GAN的方法要好得多,这些方法通常无法将对象彼此分离,并且都会受到特定对象修改的影响。
与他们的方法不同的是,他们在三维场景表示中解决这个问题,就像我们如何看待现实世界一样,而不是像其他GANs那样停留在二维图像世界中。但除此之外,过程非常相似。它们对信息进行编码,识别对象,在潜在空间内对其进行编辑,然后解码生成新的图像。在这里,在这个潜在的空间里还有更多的步骤要做。我们可以将其视为经典GAN图像合成网络与神经渲染器的结合,神经渲染器用于从发送到网络的图像生成3D场景,正如我们看到的。
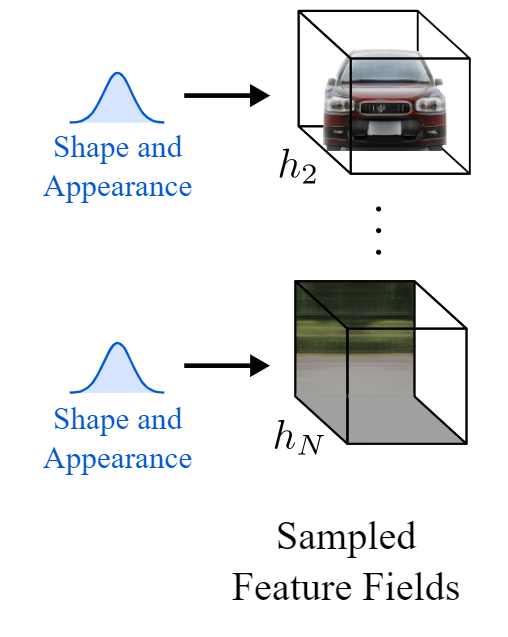
实现这一目标主要有三个步骤。对输入图像进行编码后,意味着我们已经处于潜在空间中,第一步是将图像转换为三维场景。但不仅仅是一个简单的3D场景,一个由3D元素组成的3D场景,即物体和背景。这种将图像视为由生成的体渲染组成的场景的方式允许它们更改生成图像中的摄影机角度并独立地控制对象。这是通过使用一个与我之前讨论的论文类似的模型NERV来实现的(https://youtu.be/ZkaTyBvS2w4),但是它们没有使用一个模型从输入图像生成整个锁定场景,而是使用两个单独的模型独立地生成对象和背景。这里称为采样特征字段。该网络的参数也在训练过程中学习。我不想谈细节,但它与NERF非常相似,我在另一篇文章中谈到了NERF。如果你想了解更多关于这类网络的细节,你可以观看这段关于NERV的视频,下面的参考资料中也有链接。
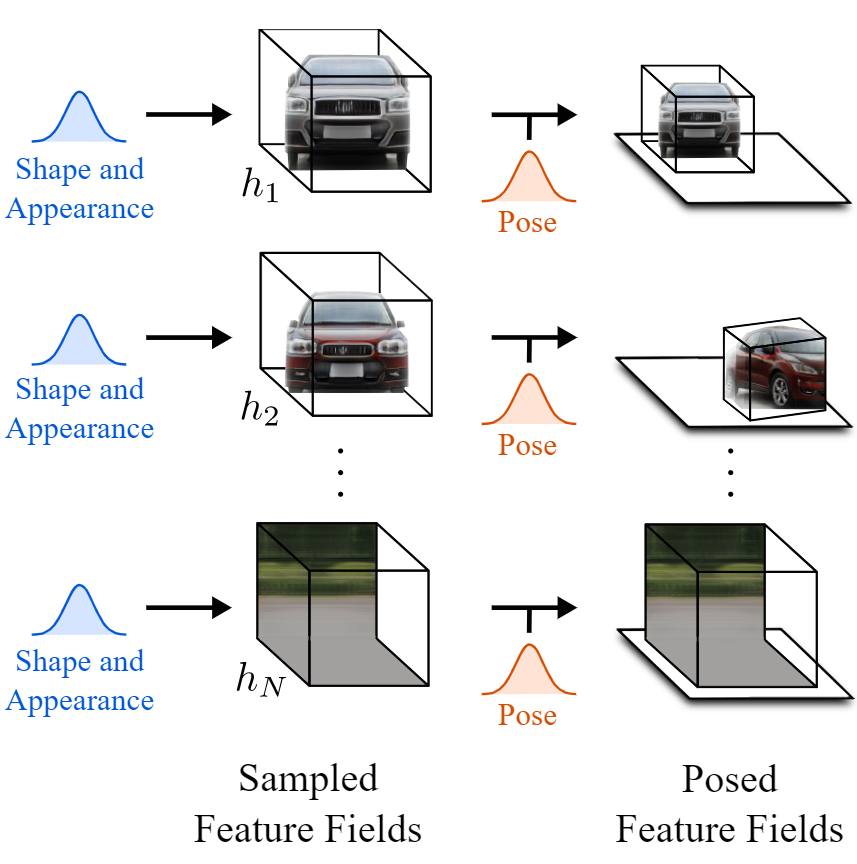
有了这个场景和分离的元素,我们可以单独编辑它们而不影响图像的其余部分。这是第二步。他们可以对物体做任何他们想做的事情,比如改变它的位置和方向。换句话说,它们改变了物体或背景的姿势。在这一点上,他们甚至可以添加新的对象放置在他们想要的任何地方。然后,通过将所有特征字段添加到一起,将它们简单地组合到包含所有对象和背景的最终三维场景中。
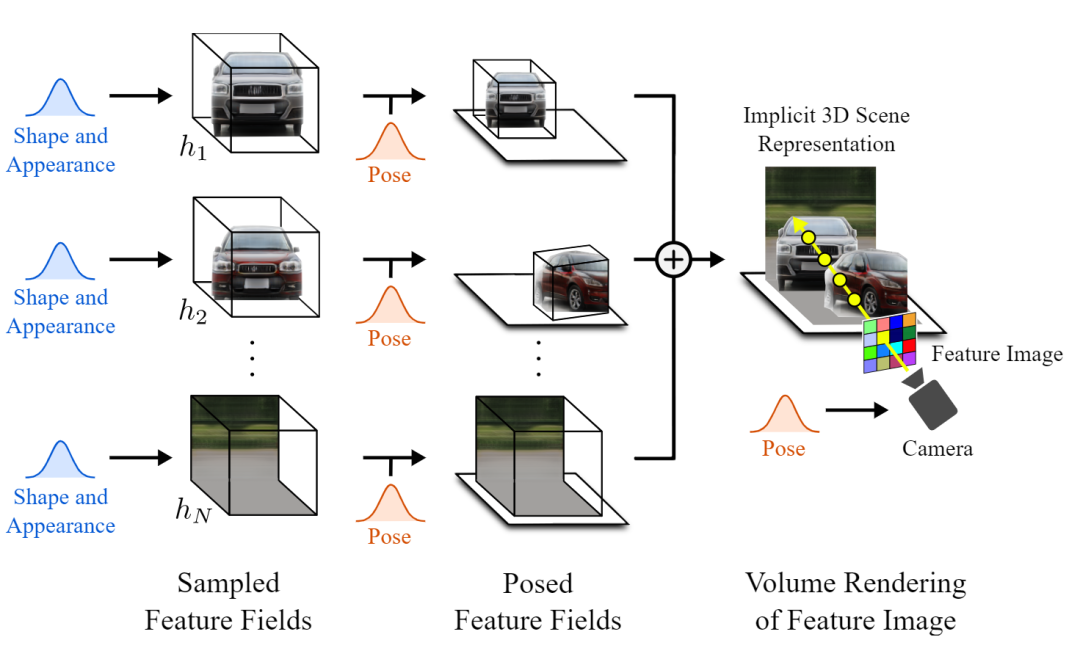
最后,我们必须回到自然图像的二维世界。所以最后一步是把这个3D场景渲染成一个规则的图像。由于我们仍然处于三维世界中,我们可以改变相机的视点来决定我们将如何看待场景。然后,我们根据该相机光线和其他参数(如alpha值和透射率)对每个像素进行评估。这就是他们所说的特征图像,但是这个特征图像是由每个像素的特征向量组成的图像。由于我们仍处于潜在空间,这些特征需要转化为RGB颜色和高分辨率图像。这是通过使用典型的解码器来完成的,就像其他GAN架构一样,将其放大到原始尺寸,同时学习RGB通道的特征转换。瞧à, 你有你的新形象,有更多的控制,什么是生成!
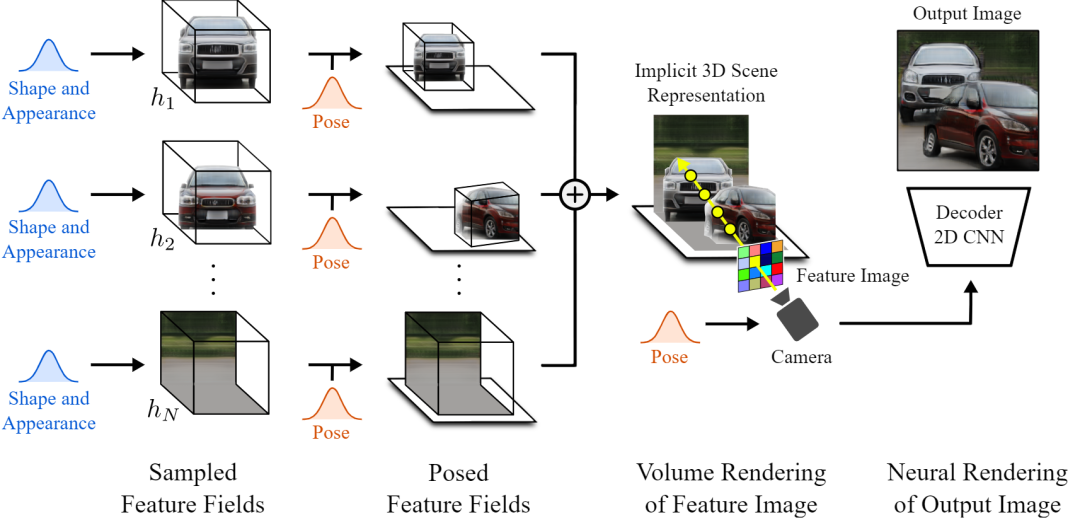
当然,正如你所看到的,它在实际数据中使用时仍然不是完美的。尽管如此,它仍然令人印象深刻,是朝着正确方向迈出的重要一步,特别是考虑到这些都是完全由GANs生成的合成图像,而且它只是第一篇能够以这种精度控制生成图像的论文。

这篇论文真的很有趣,我建议你读一下,以了解他们的模型是如何工作的。祝贺迈克尔·尼迈耶和安德烈亚斯·盖革获得当之无愧的最佳论文奖。如果你想玩的话,他们还可以在GitHub上使用这些代码。链接在下面的参考资料中谢谢你的阅读!
努力分享优质的计算机视觉相关内容,欢迎关注:
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看