
从因果关系来看小样本学习丨NeurIPS 2020

极市导读
本文提出了一种因果干预的新分类器,它具有应用广泛、无需额外训练步骤、在缺少预训练数据集时仍然大幅提高性能等三大优势。>>加入极市CV技术交流群,走在计算机视觉的最前沿
本文主要介绍我们组被NeurIPS 2020接受的论文Interventional Few-Shot Learning。论文的代码会在Github上开源:
yue-zhongqi/ifslgithub.com
我们的这篇工作,根据小样本学习当中的因果关系,提出了一种新的基于因果干预的分类器IFSL,去除了预训练带来的掺杂效果,在各种方法上取得了稳定的提升。主要的优势有:
广泛适用于各种基于微调(fine-tune)或是元学习(meta-learning)的方法,即插即用; 无需额外的训练步骤,原来模型咋训练,加上IFSL还是咋训练; 如果预训练数据集不公开,比如一些商用数据集只公开分类器和特征提取器,那么元学习的方法就不适用了,只能用微调。在这种情况下,IFSL还是可以大幅提高性能。
接下来我会具体的来介绍小样本学习和我们的IFSL。章节导视:
想看小样本学习介绍的请戳一 因果关系分析的请戳二 直接看实现方法的请戳三 看结果的请戳四
一、小样本学习的介绍
2019年,Open AI Five以碾压的表现战胜了Dota2世界冠军战队OG,然而在这令人惊叹的表现背后,是12.8万个CPU和256块P100数个月训练的结果,相当于不间断练习了45000年的游戏。很显然,目前一个鲁棒的机器学习模型还难以离开大量的数据、长时间的训练以及高昂的训练成本。而小样本学习就致力于通过极少的训练数据(1-5个样本/类)来实现模型的泛化。
那么,如何进行小样本学习呢?这一点我们可以观察人是如何快速学习的。例如一个人玩策略游戏帝国时代很厉害,那么如果去学习诸如星际争霸的其他策略游戏,就比较容易上手,因为可以运用以前的游戏经验,一通百通。同样的,对于机器而言,在少量样本上快速泛化的核心,就是借助先验知识。
预训练是(Pre-training)大家都熟悉且非常有效的获取先验知识的方法。具体就是在大型数据集上,学习一个强大的神经网络作为特征提取器,例如CV里面常见的在ImageNet上预训练的ResNet网络,或是NLP里面在Wikipedia上训练的BERT,都代表一种特征表达的先验知识。在预训练基础上,我们只需在样本数量少的目标任务中,微调部分(例如只训练最后一层fc分类器)或者全部网络的参数,便得到了一个可以解决小样本学习问题的模型。
预训练相当于给了小样本学习一个好的起点,就像一个人在上课前预习了大量的知识点。不过想要更上一层楼,还需要有效的学习方法。元学习(meta learning)的目的就是找到这种方法。具体来说,我们可以从预训练集中,每次采样出来一个“沙盒”版小样本任务,例如选5个类,每个类选5张图片作为训练集(support set),再选15张作为测试集(query set),然后我们要求模型在support set训练的结果,能够在query set上面取得好的表现。其实这种学习策略在我们身边随处可见,例如准备考试的时候,我们会提前做一些模拟测试,了解题型,规划答题节奏等等,这就是一种元学习。在小样本学习的实际操作中,我们可以使用元学习训练一个模型的初始化参数(MAML),或是一个分类器参数的生成网络(LEO)等等。通过元学习得到的知识,就构成了一种学习方法的先验知识,在预训练的网络之上,进一步提升小样本学习的表现。
综上所述,小样本学习的解决思路,可以用下面这张图来概括:我们先在一个大的数据集 上面预训练一个特征提取网络 ,之后我们既可以直接使用 在每一个小样本任务中微调(红色方块的Fine-Tuning); 也可以进一步使用元学习(Meta-Learning),将 拆成一个个由support set 和query set 组成的沙盒任务 ,训练高效的学习方法 ;元学习结束以后,我们就可以用这种高效的学习方法,在小样本学习的任务中进行微调(绿色方块的Fine-Tuning)。
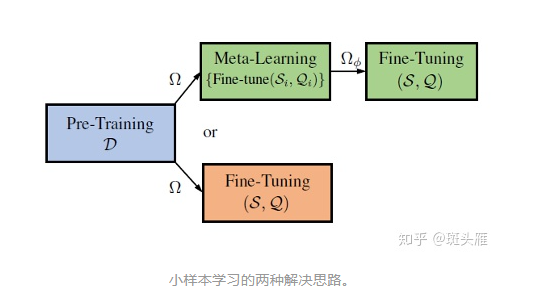
二、亦正亦邪的预训练
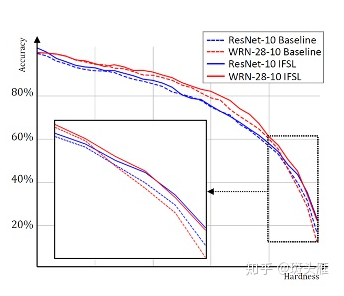
从上一章的介绍中不难看出,预训练是小样本学习中一个核心的环节,无论是基于微调的,还是基于元学习的方法,都以预训练为开始。那么从常理来说,更强的预训练,应该会带来更好的小样本学习的表现,例如在现有文献中,使用更深层的神经网络架构WRN-28-10的微调结果,往往会比相对较浅的ResNet-10表现好很多。然而我们在微调的实验中发现(见左边的直方图),虽然平均WRN-28-10(strong )更好,但当query set和support set区别很大的时候,结果是恰恰相反的,浅层的ResNet-10反而表现更佳!这是为什么呢?

这张图的右边是一个 和 区别很大的例子,其中预训练时候见过的草的颜色是support set里的一个误导因素,分类器容易踩坑,以草的颜色(见过)而非动物本身(没见过)作为分类依据。而越强的预训练模型,这些见过的草,相比于没见过的动物,就会产生越鲁棒的特征,对于分类器就更加误导了,聪明反被聪明误。为什么这个问题一直没有被发现呢?其实就是因为被现有方法基于随机取样后平均的评估策略所掩盖了。我们的工作也首次为这个现象提供了解释。
具体来说,刚才讲的这个悖论是由小样本学习当中的因果关系造成的。预训练在带来丰富的先验知识的同时,也成了学习过程中的一个混杂因子(confounder),使得分类器难以找到样本特征和样本标注之间真实的因果关系。我们用一张因果图来具体说明。
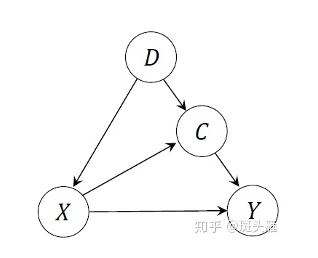
: 这里 代表预训练的先验知识, 代表图片的特征表示,箭头的意思是,我们用预训练得到的特征提取器,获得样本的特征. : 其中C代表一个样本X在预训练数据流形上面的投影;一个例子是eigenface,我们将高维的训练集(),通过PCA找到这些图片的基(也就是eigenface),这样一张人脸图片(),就可以被表示成这些基的线性组合,而线性组合的系数就是 。类似的现象在深度学习的训练中也会出现,具体可以参考我们论文里面的引用。 : 当我们用特征 训练一个分类器预测标签 的时候,分类器会不可避免的使用 里面的信息;也就是说 是特征里面低维度信息的影响,而 是 里没有包含的冗余信息带来的影响。
在这个因果图中,注意到 是 和 的共因( ),这样 被叫做 和 的混杂因子,从而导致观测到的 ,被混杂的关系 污染,而不能反映 和 间真实的因果关系了,刚才分类器被草的颜色迷惑的原因,其实就是分类器使用了 里“草”的语义信息,作为分类狮子的依据。
那么当存在混杂因子的时候,我们应该如何学习 真实的因果关系呢?这就要用到干预(intervention),即 。干预 会切断因果图中所有指向 的箭头(如下图),这样之前产生混杂的这条路 被堵住了,我们就能安全的学习想要的因果关系了。
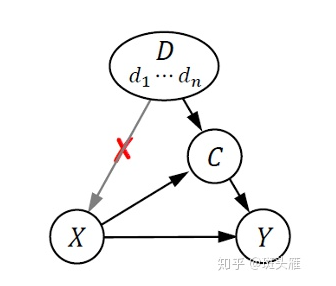
我们的这篇工作使用后门调整(backdoor adjustment)来实现 ,我们的因果图对应的后门调整是:
具体来说,就是对预训练的知识 进行分层(见图中的 ),每一层有自己的分类器 ,然后把每层分类器的结果通过先验概率 平均起来。关于混杂因子、干预和后门调整的具体介绍,大家可以参考一下我们组王谭写的:
https://zhuanlan.zhihu.com/p/111306353
三、基于干预的去混杂
上一章讲到预训练在带来特征表达的先验知识的同时,也成为了混杂因子而迷惑了分类器的训练,而我们打算通过对预训练知识分层,然后用后门调整来找到 和 之间真实的因果关系。这一章我们会来讲具体如何实现分层和后门调整。
我们是从预训练的神经网络所自带的两个属性来寻找分层的灵感的:
1)特征维度,例如ResNet-10是512维的特征,每一个维度代表CNN里面的一个通道,对应了图片中的一些视觉信息;
2)预训练的类别,例如在miniImageNet上预训练所使用的64个类,那么预训练所得到的64类分类器,就可以看作对预训练数据集知识的一种蒸馏(knowledge distillation)。
基于这些灵感,我们提出了三种不同的实现方案,分别是基于特征的调整(feature-wise adjustment),基于类别的调整(class-wise adjustment)以及两种结合起来(combined adjustment)。具体这三种调整是如何对应后门调整公式的,大家可以参考论文第三章,这里我只是讲一下具体的实现。
可以看到,我们基于干预的这个方法只改变了分类器的架构,因此可以普遍的加入基于微调或元学习的小样本学习方法,并且无需增加额外的训练步骤。
四、实验结果
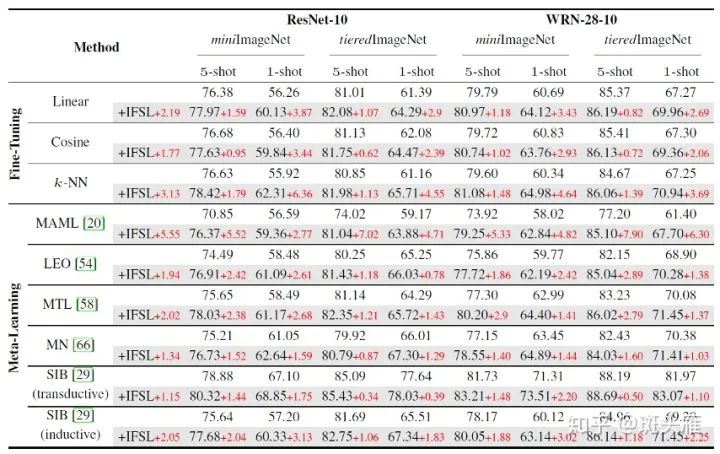
【普遍适用,涨点明显】因为我们的方法是在分类器层面的改动,所以可以普遍的加入到各种微调和元学习的方法当中。我们在常用的微调方法(linear,cosine和k-NN),以及5种不同思路的元学习方法上面做了大量的验证,在miniImageNet和tieredImageNet上面取得了普遍的提高。
【去除预训练的混杂】我们提出了一种新的Hardness-specific Acc来诊断小样本学习。对于每一个测试样本,根据它和训练集support set的相似程度,我们定义了一个难度系数,这样我们可以观察模型在不同测试样本难度下的表现,而越难的样本就越容易在上面被预训练的知识误导。下图展示了微调当中baseline和ifsl的hardness-specific acc,可以看到IFSL(实线)在各个难度下都超过了baseline(虚线),说明起到了去除混杂的作用。更详细的分析可以参考论文。
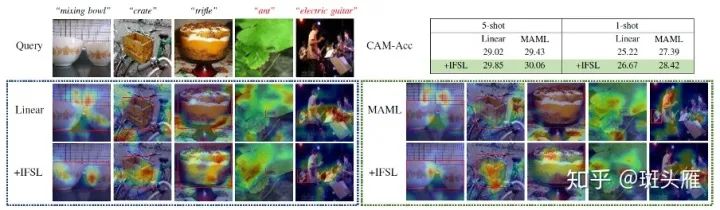
【帮助模型聚焦物体】模型在做预测的时候,是根据图片上的哪一部分呢?因此我们提出了CAM-Acc:在一张图片上先计算Grad-CAM分数(越高代表模型越关注这一部分),CAM-Acc是Grad-CAM分数高于0.9的区域中,在物体bounding box内部的比重。我们来看一下Grad-CAM可视化的结果,以及CAM-Acc的表现。通过可视化和CAM-Acc的分数,可以看到IFSL的模型的确能够多注意物体本身。当然也有失败的时候,比如看到当物体太小的时候(蚂蚁),baseline和IFSL都只能依赖背景中的context去做预测了。
结语
预训练的先验知识,是近些年来小样本学习分数快速提升的重要原因。我们的这篇工作,其实是从因果的角度分析了预训练对于学习一个分类模型的影响,揭示了基于 的分类器会被先验知识混杂,想当然的做出预测;而基于干预 的去混杂方法,就是在一个不熟悉的小样本学习任务中,平衡先验知识的影响,做到三思而后行。在这个思路下,我们提出了IFSL分类器,简单、普适且有效。
事实上,这种对先验知识的处理方法,可以被应用于任何使用预训练的任务当中,因为下游任务中的训练数据,比起大规模预训练来说,都相当于小样本学习了。也欢迎大家参考我们搭建的因果框架,在使用到预训练的不同场景中,尝试去除预训练知识所带来的掺杂。
最后附上我们论文的引用:
@inproceedings{yue2020interventional,
title={Interventional Few-Shot Learning},
author={Yue, Zhongqi and Zhang, Hanwang and Sun, Qianru and Hua, Xian-Sheng},
booktitle= {NeurIPS},
year={2020}
}
也推荐一波我们组凯爷在因果关系上非常solid的研究:
推荐阅读
