
Batch Normalization应该放在ReLU非线性激活层的前面还是后面?
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

编辑:CVDaily 转载自:计算机视觉Daily
https://www.zhihu.com/question/283715823
本文仅作为学术分享,如果侵权,会删文处理
BN 放在ReLU的前面还是后面?这个问题是AI面试的高频题
Batch-normalized 应该放在非线性激活层的前面还是后面?
我看网上的中文资料基本都是说,将BN 层放在非线性激活层的前面,但是
在 Deep Learning for Computer Vision with Python 中,有以下讨论,

作者:论智
https://www.zhihu.com/question/283715823/answer/438882036
在BN的原始论文中,BN是放在非线性激活层前面的(arXiv:1502.03167v3,第5页)
We add the BN transform immediately before the nonlinearity
(注意:before的黑体是我加的,为了突出重点)
但是,François Chollet爆料说BN论文的作者之一Christian把BN放在ReLU后面(你的问题里引用的文字也提到了这一段)。
I can guarantee that recent code written by Christian applies relu before BN.
另外,Jeremy Howard直接主张把BN放在非线性激活后面
You want the batchnorm after the non-linearity, and before the dropout.
“应该”放在前面还是后面?这个“应该”其实有两种解释:
放在前面还是后面比较好?
为什么要放在前面还是后面?
对于第一问,目前在实践上,倾向于把BN放在ReLU后面。也有评测表明BN放ReLU后面效果更好。
对于第二问,实际上,我们目前对BN的机制仍然不是特别清楚,这里只能尝试做些(玄学)解释,不一定正确。
BN,也就是Batch-Normalization,这名字就能让我们想到普通的normalization(归一化),也就是将输入传给神经网络之前对输入做的normalization。这个normalization是对输入操作的,是在输入层之前进行的。那么,从这个角度上来说,Batch-Normalization可以视作对传给隐藏层的输入的normalization。想象一下,如果我们把网络中的某一个隐藏层前面的网络层全部砍掉,那么这个隐藏层就变成了输入层,传给它的输入需要normalization,就在这一层之间,这个位置,就是原本的BN层的位置。从这方面来说,BN层放非线性激活之后,是很自然的。
然后,我们再来考虑一些具体的激活函数。我们看到,无论是tanh
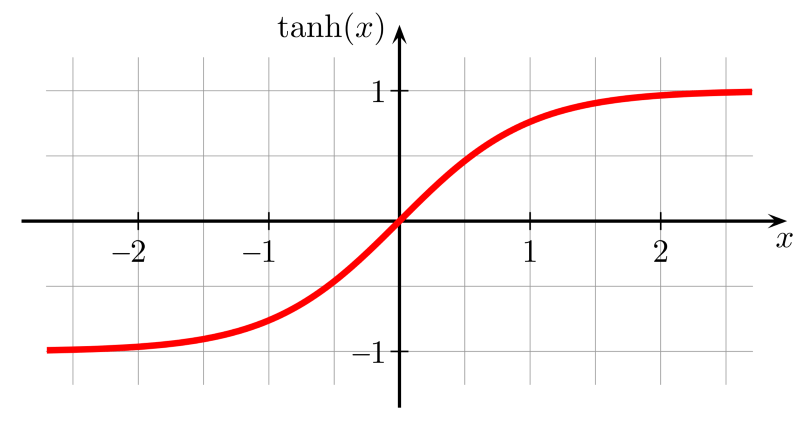
还是sigmoid
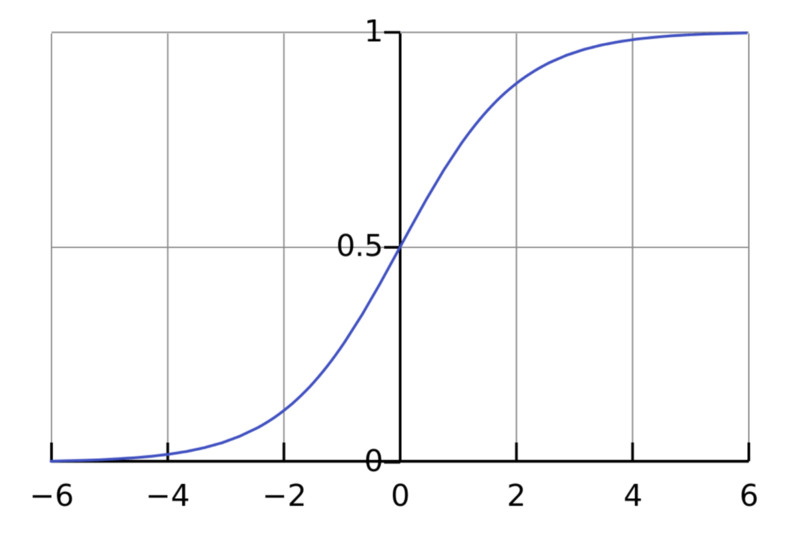
函数图像的两端,相对于x的变化,y的变化都很小(这其实很正常,毕竟tanh就是拉伸过的sigmoid)。也就是说,容易出现梯度衰减的问题。那么,如果在tanh或sigmoid之前,进行一些normalization处理,就可以缓解梯度衰减的问题。我想这可能也是最初的BN论文选择把BN层放在非线性激活之前的原因。
但是ReLU的画风和它们完全不一样啊。
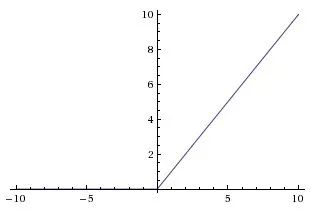
实际上,最初的BN论文虽然也在使用ReLU的Inception上进行了试验,但首先研究的是sigmoid激活。因此,试验ReLU的,我猜想作者可能就顺便延续了之前把BN放前面的配置,而没有单独针对ReLU进行处理。
总结一下,BN层的作用机制也许是通过平滑隐藏层输入的分布,帮助随机梯度下降的进行,缓解随机梯度下降权重更新对后续层的负面影响。因此,实际上,无论是放非线性激活之前,还是之后,也许都能发挥这个作用。只不过,取决于具体激活函数的不同,效果也许有一点差别(比如,对sigmoid和tanh而言,放非线性激活之前,也许顺便还能缓解sigmoid/tanh的梯度衰减问题,而对ReLU而言,这个平滑作用经ReLU“扭曲”之后也许有所衰弱)。
作者:王超锋
https://www.zhihu.com/question/283715823/answer/444230597
个人理解上和@论智差不多一致
实验上,放后面更有效。为什么放后面有效,谈一下我自己的理解。例如,这里两层卷积:
1、before, conv1-bn1-ReLU1-conv2-bn2-ReLU2
2、after,conv1-ReLU1-bn1-conv2-ReLU2-bn2
BN与常用的数据归一化最大的区别就是有α和β两个参数,这两个参数主要作用是在加速收敛和表征破坏之间做的trade off。在初期数据归一化比较明显,所以网络可以迅速收敛。至于为什么数据归一化可以加速收敛,这篇博客解释的不错,可以参考下,Batch Normalization详解。随着训练来到中后期这两个参数学习到差不多的时候,主要是用来恢复上一层输入分布。
所以这么去理解,上面的两个结构的斜线加粗部分。1和2中都相当于作conv2的输入做了归一化,从conv2的看来,其输入都是ReLU1之后的数据,但区别在于1中ReLU1截断了部分bn1归一化以后的数据,所以很有可能归一化的数据已经不再完全满足0均值和单位方差,而2中ReLU1之后的数据做了归一化,归一化后仍满足0均值和单位方差。所以放后边更有效也是可以理解的。
以上纯属个人理解,其实可以做这么个实验,在1结构的中在加一个BN,conv1-bn1-ReLU1-bn-conv2-bn2-ReLU2,把截断后的数据在做个归一化,这样和原始的1比较下看看是否更有效。如果有的话,说明conv2更喜欢0均值和单位方差的分布~,不过我也没试过。不知道会不会被打脸( ̄ε(# ̄)☆╰╮( ̄▽ ̄///)
作者:王艺程
https://www.zhihu.com/question/283715823/answer/443733242
在我所见过的所有包含BN的网络结构中,BN都是在ReLU之前的。下面给出一种解释
为了方便大家理解,先介绍一下我们在CVPR2018发表的论文《Person Re-identification with Cascaded Pairwise Convolutions》中提出的一种简单的层:Channel Scaling (CS, 通道放缩层)。CS层将每一输入通道乘以一恒正因子后作为输出。在CS层存在于卷积层后,ReLU层前时,我们认为CS层可以在网络训练过程中引导卷积权值取正,进而缓解零梯度问题。具体的解释除了看论文,还可以看下图。

BN也可以解决零梯度问题,有两条途径,下面直观地定性讲讲:
当对于绝大部分输入特征图,filter绝大部分响应值为负时,会产生零梯度问题,在卷积层后加入BN层后,BN层中该filter对应通道的均值为负,BN中的减均值处理会使得相当一部分响应值变为正,进而解决了零梯度问题。(这段讨论忽略了BN中的bias项和scaling项)
BN中的scaling项初始化为1,在训练过程中一般取值为正,因此可通过类似CS的途径来缓解零梯度问题;其实,如果scaling项一直取值为负,也可通过类似CS的途径来缓解零梯度问题。(这段讨论中忽略了BN中的normalization计算)
前述两条途径均存在缺陷,使得带BN的网络的训练不稳定(至少在我们的实验中是这样):
BN中的均值和方差不是通过随机梯度下降法训练的,而是逐Batch统计并滑动平均,受不同Batch中样本情况差异的影响大,在训练过程中可能出现较大波动或改变,进而影响网络功能。
训练过程中,BN层中scaling项的取值有可能由正变负或者由负变正,这种情况翻转了对应通道的含义,可能对网络功能造成损害;此外,如果scaling项时而取正时而取负,无法实现类似CS的功能。
-------------
【补充】上面提到的我们的那篇论文存在靠不合理评测方式提升分数的问题,并且第三个贡献——Sample Rate Leaning策略的优势在调整网络结构后难以体现。至少根据现有实验,我觉得CS的效果比较明显,并且有很合理的理论解释。
作者:star all
https://www.zhihu.com/question/283715823/answer/700870267
和一位答友类似,我见过的很多网络也是都把bn放到激活前面。我做一下解释:
现在我们假设所有的激活都是relu,也就是使得负半区的卷积值被抑制,正半区的卷积值被保留。而bn的作用是使得输入值的均值为0,方差为1,也就是说假如relu之前是bn的话,会有接近一半的输入值被抑制,一半的输入值被保留。
所以bn放到relu之前的好处可以这样理解:bn可以防止某一层的激活值全部都被抑制,从而防止从这一层往前传的梯度全都变成0,也就是防止梯度消失。(当然也可以防止梯度爆炸)
还有一个好处,把bn放到激活前面是有可以把卷积的weight和bn的参数进行合并的,所以它有利于网络在做前向inference时候进行加速。
作者:郭嘉
https://www.zhihu.com/question/283715823/answer/553603362
前面答案说了一大堆bn放在relu后面的好处和理论依据。
而我用resnet18训练手部检测,只改变bn和relu的顺序,和有些答主一样,bn放在relu前面效果稍微好一点。
深度学习的理论真的有那么肯定的话,就不需要做那么多实验来调整网络了,根据自己的使用场景,自己实验才是正确的答案。

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~