
原来ReLU这么好用!一文带你深度了解ReLU激活函数!
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
在神经网络中,激活函数负责将来自节点的加权输入转换为该输入的节点或输出的激活。ReLU 是一个分段线性函数,如果输入为正,它将直接输出,否则,它将输出为零。它已经成为许多类型神经网络的默认激活函数,因为使用它的模型更容易训练,并且通常能够获得更好的性能。在本文中,我们来详细介绍一下ReLU,主要分成以下几个部分:
1、Sigmoid 和 Tanh 激活函数的局限性
2、ReLU(Rectified Linear Activation Function)
3、如何实现ReLU
4、ReLU的优点
5、使用ReLU的技巧
1. Sigmoid 和 Tanh 激活函数的局限性
一个神经网络由层节点组成,并学习将输入的样本映射到输出。对于给定的节点,将输入乘以节点中的权重,并将其相加。此值称为节点的summed activation。然后,经过求和的激活通过一个激活函数转换并定义特定的输出或节点的“activation”。
最简单的激活函数被称为线性激活,其中根本没有应用任何转换。 一个仅由线性激活函数组成的网络很容易训练,但不能学习复杂的映射函数。线性激活函数仍然用于预测一个数量的网络的输出层(例如回归问题)。
非线性激活函数是更好的,因为它们允许节点在数据中学习更复杂的结构 。两个广泛使用的非线性激活函数是sigmoid 函数和双曲正切 激活函数。
Sigmoid 激活函数 ,也被称为 Logistic函数神经网络,传统上是一个非常受欢迎的神经网络激活函数。函数的输入被转换成介于0.0和1.0之间的值。大于1.0的输入被转换为值1.0,同样,小于0.0的值被折断为0.0。所有可能的输入函数的形状都是从0到0.5到1.0的 s 形。在很长一段时间里,直到20世纪90年代早期,这是神经网络的默认激活方式。
双曲正切函数 ,简称 tanh,是一个形状类似的非线性激活函数,输出值介于-1.0和1.0之间。在20世纪90年代后期和21世纪初期,由于使用 tanh 函数的模型更容易训练,而且往往具有更好的预测性能,因此 tanh 函数比 Sigmoid激活函数更受青睐。
Sigmoid和 tanh 函数的一个普遍问题是它们值域饱和了 。这意味着,大值突然变为1.0,小值突然变为 -1或0。此外,函数只对其输入中间点周围的变化非常敏感。
无论作为输入的节点所提供的求和激活是否包含有用信息,函数的灵敏度和饱和度都是有限的。一旦达到饱和状态,学习算法就需要不断调整权值以提高模型的性能。
最后,随着硬件能力的提高,通过 gpu 的非常深的神经网络使用Sigmoid 和 tanh 激活函数不容易训练。在大型网络深层使用这些非线性激活函数不能接收有用的梯度信息。错误通过网络传播回来,并用于更新权重。每增加一层,错误数量就会大大减少。这就是所谓的消失梯度 问题,它能有效地阻止深层(多层)网络的学习。
虽然非线性激活函数的使用允许神经网络学习复杂的映射函数,但它们有效地阻止了学习算法与深度网络的工作。在2000年代后期和2010年代初期,通过使用诸如波尔兹曼机器和分层训练或无监督的预训练等替代网络类型,这才找到了解决办法。
2. ReLU(Rectified Linear Activation Function)
为了训练深层神经网络,需要一个激活函数神经网络,它看起来和行为都像一个线性函数,但实际上是一个非线性函数,允许学习数据中的复杂关系 。该函数还必须提供更灵敏的激活和输入,避免饱和。
因此,ReLU出现了,采用 ReLU 可以是深度学习革命中为数不多的里程碑之一 。ReLU激活函数是一个简单的计算,如果输入大于0,直接返回作为输入提供的值;如果输入是0或更小,返回值0。
我们可以用一个简单的 if-statement 来描述这个问题,如下所示:
if input > 0:
return input
else:
return 0
对于大于零的值,这个函数是线性的,这意味着当使用反向传播训练神经网络时,它具有很多线性激活函数的理想特性。然而,它是一个非线性函数,因为负值总是作为零输出。由于矫正函数在输入域的一半是线性的,另一半是非线性的,所以它被称为分段线性函数(piecewise linear function ) 。
3. 如何实现ReLU
我们可以很容易地在 Python 中实现ReLU激活函数。
# rectified linear function
def rectified(x):
return max(0.0, x)
我们希望任何正值都能不变地返回,而0.0或负值的输入值将作为0.0返回。
下面是一些修正的线性激活函数的输入和输出的例子:
# demonstrate the rectified linear function
# rectified linear function
def rectified(x):
return max(0.0, x)
# demonstrate with a positive input
x = 1.0
print('rectified(%.1f) is %.1f' % (x, rectified(x)))
x = 1000.0
print('rectified(%.1f) is %.1f' % (x, rectified(x)))
# demonstrate with a zero input
x = 0.0
print('rectified(%.1f) is %.1f' % (x, rectified(x)))
# demonstrate with a negative input
x = -1.0
print('rectified(%.1f) is %.1f' % (x, rectified(x)))
x = -1000.0
print('rectified(%.1f) is %.1f' % (x, rectified(x)))
输出如下:
rectified(1.0) is 1.0
rectified(1000.0) is 1000.0
rectified(0.0) is 0.0
rectified(-1.0) is 0.0
rectified(-1000.0) is 0.0
我们可以通过绘制一系列的输入和计算出的输出,得到函数的输入和输出之间的关系。下面的示例生成一系列从 -10到10的整数,并计算每个输入的校正线性激活,然后绘制结果。
# plot inputs and outputs
from matplotlib import pyplot
# rectified linear function
def rectified(x):
return max(0.0, x)
# define a series of inputs
series_in = [x for x in range(-10, 11)]
# calculate outputs for our inputs
series_out = [rectified(x) for x in series_in]
# line plot of raw inputs to rectified outputs
pyplot.plot(series_in, series_out)
pyplot.show()
运行这个例子会创建一个图,显示所有负值和零输入都突变为0.0,而正输出则返回原样:
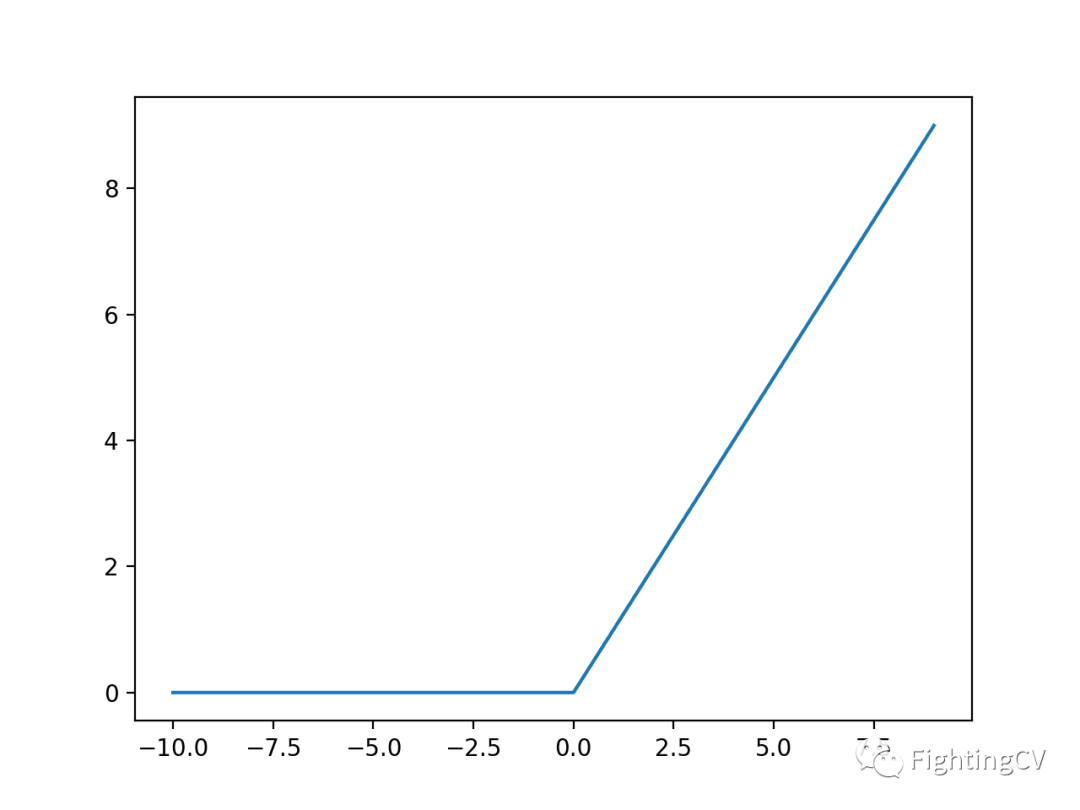
ReLU函数的导数是斜率。负值的斜率为0.0,正值的斜率为1.0。
传统上,神经网络领域已经不能是任何不完全可微的激活函数,而ReLU是一个分段函数。从技术上讲,当输入为0.0时,我们不能计算ReLU的导数,但是,我们可以假设它为0。
4. ReLU的优点
4.1. 计算简单性
tanh 和 sigmoid 激活函数需要使用指数计算, 而ReLU只需要max(),因此他计算上更简单,计算成本也更低 。
4.2. 代表性稀疏
ReLU的一个重要好处是,它能够输出一个真正的零值 。这与 tanh 和 sigmoid 激活函数不同,后者学习近似于零输出,例如一个非常接近于零的值,但不是真正的零值。这意味着负输入可以输出真零值,允许神经网络中的隐层激活包含一个或多个真零值。这就是所谓的稀疏表示,是一个理想的性质,在表示学习,因为它可以加速学习和简化模型。
4.3. 线性行为
ReLU看起来更像一个线性函数,一般来说,当神经网络的行为是线性或接近线性时,它更容易优化 。
这个特性的关键在于,使用这个激活函数进行训练的网络几乎完全避免了梯度消失的问题,因为梯度仍然与节点激活成正比。
4.4. 训练深度网络
ReLU的出现使得利用硬件的提升和使用反向传播成功训练具有非线性激活函数的深层多层网络成为可能 。
5. 使用ReLU的技巧
5.1. 使用 ReLU 作为默认激活函数
很长一段时间,默认的激活方式是Sigmoid激活函数。后来,Tanh成了激活函数。对于现代的深度学习神经网络,默认的激活函数是ReLU激活函数 。
5.2. 对 MLPs,CNNs 使用 ReLU,但不是 RNNs
ReLU 可以用于大多数类型的神经网络,它通常作为多层感知机神经网络和卷积神经网络的激活函数 ,并且也得到了许多论文的证实。传统上,LSTMs 使用 tanh 激活函数来激活cell状态,使用 Sigmoid激活函数作为node输出。而ReLU通常不适合RNN类型网络的使用。
5.3. 尝试更小的bias输入值
偏置是节点上具有固定值的输入,这种偏置会影响激活函数的偏移,传统的做法是将偏置输入值设置为1.0。当在网络中使用 ReLU 时,可以将偏差设置为一个小值,例如0.1 。
5.4. 使用“He Weight Initialization”
在训练神经网络之前,网络的权值必须初始化为小的随机值。当在网络中使用 ReLU 并将权重初始化为以零为中心的小型随机值时,默认情况下,网络中一半的单元将输出零值。有许多启发式方法来初始化神经网络的权值,但是没有最佳权值初始化方案。何恺明的文章指出Xavier 初始化和其他方案不适合于 ReLU ,对 Xavier 初始化进行一个小的修改,使其适合于 ReLU,提出He Weight Initialization,这个方法更适用于ReLU 。
5.5. 缩放输入数据
在使用神经网络之前对输入数据进行缩放是一个很好的做法。这可能涉及标准化变量,使其具有零均值和单位方差,或者将每个值归一化为0到1。如果不对许多问题进行数据缩放,神经网络的权重可能会增大,从而使网络不稳定并增加泛化误差。无论是否在网络中使用 ReLU,这种缩放输入的良好实践都适用。
5.6. 使用惩罚权重
ReLU 的输出在正域上是无界的。这意味着在某些情况下,输出可以继续增长。因此,使用某种形式的权重正则化可能是一个比较好的方法,比如 l1或 l2向量范数。这对于提高模型的稀疏表示(例如使用 l 1正则化)和降低泛化误差都是一个很好的方法 。
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
