
Batch Normalization和它的“后浪”们

极市导读
本文对归一化相关技术近几年的发展进行了总结,介绍了多种适用于不同应用场景方法的思路。主要涉及方法有LRN,BN,LN, IN, GN, FRN, WN, BRN, CBN, CmBN等。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
归一化相关技术已经经过了几年的发展,目前针对不同的应用场合有相应的方法,在本文将这些方法做了一个总结,介绍了它们的思路,方法,应用场景。主要涉及到:LRN,BN,LN, IN, GN, FRN, WN, BRN, CBN, CmBN等。
本文又名“BN和它的后浪们”,是因为几乎在BN后出现的所有归一化方法都是针对BN的三个缺陷改进而来,在本文也介绍了BN的三个缺陷。相信读者会读完此文会对归一化方法有个较为全面的认识和理解。
LRN(2012)
局部响应归一化(Local Response Normalization, 即LRN)首次提出于AlexNet。自BN提出后,其基本被抛弃了,因此这里只介绍它的来源和主要思想。
LRN的创意来源于神经生物学的侧抑制,被激活的神经元会抑制相邻的神经元。用一句话来形容LRN:让响应值大的feature map变得更大,让响应值小的变得更小。
其主要思想在于让不同卷积核产生feature map之间的相关性更小,以实现不同通道上的feature map专注于不同的特征的作用,例如A特征在一通道上更显著,B特征在另一通道上更显著。
Batch Normalization(2015)
论文:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
论文中关于BN提出的解释:训练深度神经网络非常复杂,因为在训练过程中,随着先前各层的参数发生变化,各层输入的分布也会发生变化,图层输入分布的变化带来了一个问题,因为图层需要不断适应新的分布,因此训练变得复杂,随着网络变得更深,网络参数的细微变化也会放大。
由于要求较低的学习率和仔细的参数初始化,这减慢了训练速度,并且众所周知,训练具有饱和非线性的模型非常困难。我们将此现象称为内部协变量偏移,并通过归一化层输入来解决该问题。
其它的解释:假设输入数据包含多个特征x1,x2,…xn。每个功能可能具有不同的值范围。例如,特征x1的值可能在1到5之间,而特征x2的值可能在1000到99999之间。
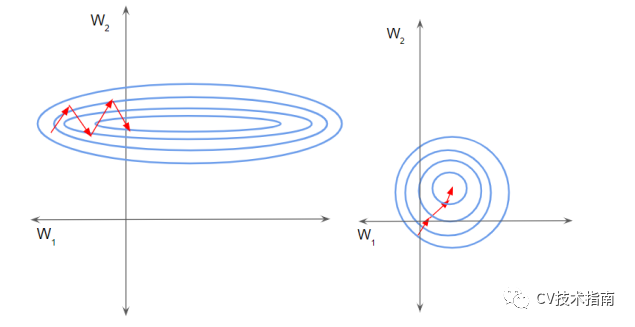
如下左图所示,由于两个数据不在同一范围,但它们是使用相同的学习率,导致梯度下降轨迹沿一维来回振荡,从而需要更多的步骤才能达到最小值。且此时学习率不容易设置,学习率过大则对于范围小的数据来说来回震荡,学习率过小则对范围大的数据来说基本没什么变化。
如下右图所示,当进行归一化后,特征都在同一个大小范围,则loss landscape像一个碗,学习率更容易设置,且梯度下降比较平稳。
实现算法:

在一个batch中,在每一BN层中,对每个样本的同一通道,计算它们的均值和方差,再对数据进行归一化,归一化的值具有零均值和单位方差的特点,最后使用两个可学习参数gamma和beta对归一化的数据进行缩放和移位。
此外,在训练过程中还保存了每个mini-batch每一BN层的均值和方差,最后求所有mini-batch均值和方差的期望值,以此来作为推理过程中该BN层的均值和方差。
注:BN放在激活函数后比放在激活函数前效果更好。
实际效果:1)与没有BN相比,可使用更大的学习率2)防止过拟合,可去除Dropout和Local Response Normalization3)由于dataloader打乱顺序,因此每个epoch中mini-batch都不一样,对不同mini-batch做归一化可以起到数据增强的效果。4)明显加快收敛速度5)避免梯度爆炸和梯度消失
注:BN存在一些问题,后续的大部分归一化论文,都是在围绕BN的这些缺陷来改进的。为了行文的方便,这些缺陷会在后面各篇论文中逐一提到。
BN、LN、IN和GN的区别与联系
下图比较明显地表示出了它们之间的区别。(N表示N个样本,C表示通道,这里为了表达方便,把HxW的二维用H*W的一维表示。)
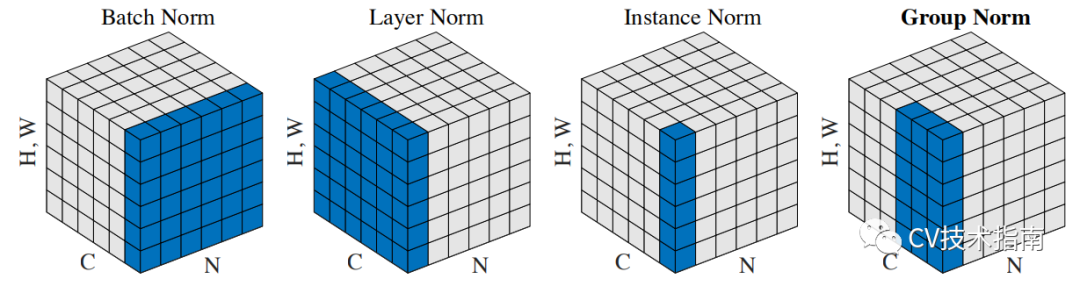
后面这三个解决的主要问题是BN的效果依赖于batch size,当batch size比较小时,性能退化严重。可以看到,IN,LN和GN都与batch size无关。
它们之间的区别在于计算均值和方差的数据范围不同,LN计算单个样本在所有通道上的均值和方差,IN值计算单个样本在每个通道上的均值和方差,GN将每个样本的通道分成g组,计算每组的均值和方差。
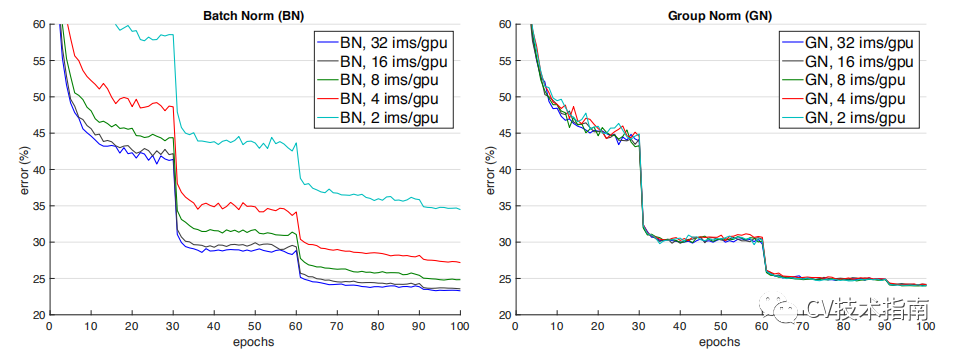
它们之间的效果对比。(注:这个效果是只在同一场合下的对比,实际上它们各有自己的应用场景,且后三者在各自的应用场合上都明显超过了BN)
Instance Normalization(2016)
论文:Instance Normalization: The Missing Ingredient for Fast Stylization
在图像视频等识别任务上,BN的效果是要优于IN的。但在GAN,style transfer和domain adaptation这类生成任务上,IN的效果明显比BN更好。
从BN与IN的区别来分析产生这种现象的原因:BN对多个样本统计均值和方差,而这多个样本的domain很可能是不一样的,相当于模型把不同domain的数据分布进行了归一化。
Layer Normalization (2016)
论文:Layer Normalization
BN的第一个缺陷是依赖Batch size,第二个缺陷是对于RNN这样的动态网络效果不明显,且当推理序列长度超过训练的所有序列长度时,容易出问题。为此,提出了Layer Normalization。
当我们以明显的方式将批归一化应用于RNN时,我们需要为序列中的每个时间步计算并存储单独的统计信息。如果测试序列比任何训练序列都长,这是有问题的。LN没有这样的问题,因为它的归一化项仅取决于当前时间步长对层的总输入。它还只有一组在所有时间步中共享的增益和偏置参数。(注:LN中的增益和偏置就相当于BN中的gamma 和beta)
LN的应用场合:RNN,transformer等。
Group Normalization(2018)
论文:Group Normalization
如下图所示,当batch size减少时,BN退化明显,而Group Normalization始终一致,在batch size比较大的时候,略低于BN,但当batch size比较小的时候,明显优于BN。
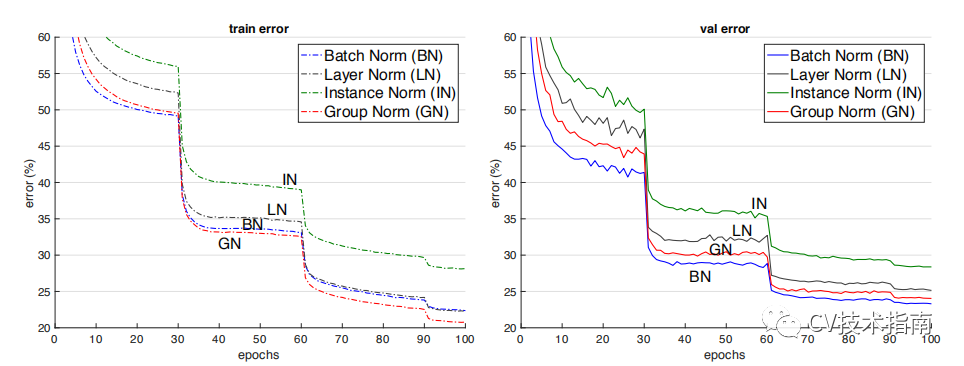
但GN有两个缺陷,其中一个是在batchsize大时略低于BN,另一个是由于它是在通道上分组,因此它要求通道数是分组数g的倍数。
GN应用场景:在目标检测,语义分割等要求尽可能大的分辨率的任务上,由于内存限制,为了更大的分辨率只能取比较小的batch size,可以选择GN这种不依赖于batchsize的归一化方法。
GN实现算法

Weights Normalization(2016)
论文:Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks
前面的方法都是基于feature map做归一化,这篇论文提出对Weights做归一化。
解释这个方法要费挺多笔墨,这里用一句话来解释其主要做法:将权重向量w分解为一个标量g和一个向量v,标量g表示权重向量w的长度,向量v表示权重向量的方向。
这种方式改善了优化问题的条件,并加速了随机梯度下降的收敛,不依赖于batch size的特点,适用于循环模型(如 LSTM)和噪声敏感应用(如深度强化学习或生成模型),而批量归一化不太适合这些应用。
Weight Normalization也有个明显的缺陷:WN不像BN有归一化特征尺度的作用,因此WN的初始化需要慎重,为此作者提出了对向量v和标量g的初始化方法。
Batch Renormalization(2017)
论文:Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-Normalized Models
前面我们提到BN使用训练过程中每个mini-batch的均值和方差的期望作为推理过程中的均值和方差,这样做的前提是mini-batch与样本总体是独立同分布的。因此BN的第三个缺陷是当mini-batch中的样本非独立同分布时,性能比较差。
基于第一个缺陷batchsize太小时性能退化和第三个缺陷,作者提出了Batch Renormalization(简称BRN)。
BRN与BN的主要区别在于BN使用训练过程中每个mini-batch的均值和方差的期望来当作整个数据集的均值和方差,而训练过程中每个mini-batch都有自己的均值和方差,因此在推理阶段的均值和方差与训练时不同,而BRN提出在训练过程中就不断学习修正整个数据集的均值和方差,使其尽可能逼近整个数据集的均值和方差,并最终用于推理阶段。
BRN实现算法如下:

注:这里r和d表示尺度缩放和平移,不参与反向传播。
当使用小batchsize或非独立同分布的mini-batch进行训练时,使用BRN训练的模型的性能明显优于BN。同时,BRN保留了BN的优势,例如对初始化的敏感性和训练效率
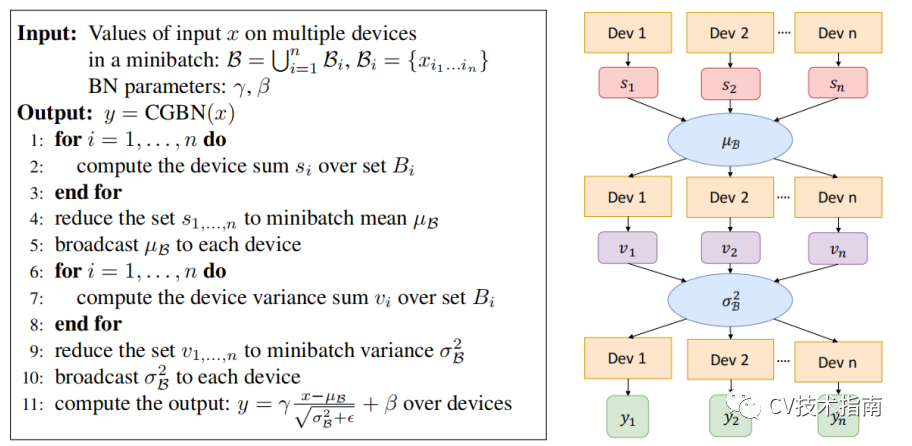
Cross-GPU BN(2018)
论文:MegDet: A Large Mini-Batch Object Detector
在使用多卡分布式训练的情况下,输入数据被等分成多份,在各自的卡上完成前向和回传,参数更新,BN是针对单卡上的样本做的归一化,因此实际的归一化的样本数并不是batchsize。例如batchsize=32,用四张卡训练,实际上只在32/4=8个样本上做归一化。
Cross-GPU Batch Normalization的思想就是在多张卡上做归一化。
具体实现算法如下:
FRN(2019)
论文:Filter Response Normalization Layer: Eliminating Batch Dependence in the Training of Deep Neural Networks
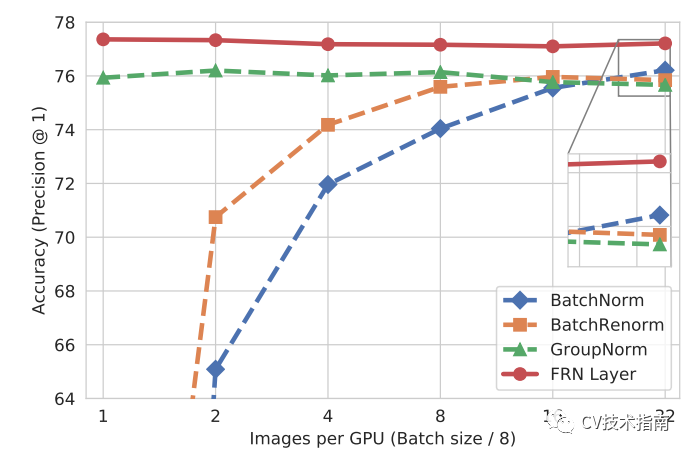
FRN仍然是基于小batchsize会退化性能的问题改进的。
FRN由两个组件构成,一个是Filter Response Normalization (FRN),一个是Thresholded Linear Unit (TLU)。
前者跟Instance Normalization非常相似,也是基于单样本单通道,所不同的是IN减去了均值,再除以标准差。而FRN没有减去均值。作者给出的理由如下:虽然减去均值是归一化方案的正常操作,但对于batch independent的归一化方案来说,它是任意的,没有任何理由。
TLU则是在ReLU的基础上加了一个阈值,这个阈值是可学习的参数。这是考虑到FRN没有减去均值的操作,这可能使得归一化的结果任意地偏移0,如果FRN之后是ReLU激活层,可能产生很多0值,这对于模型训练和性能是不利的。
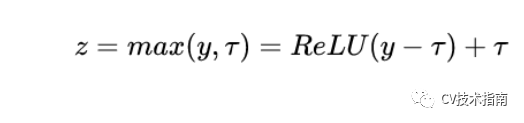
FRN实现算法

实验效果
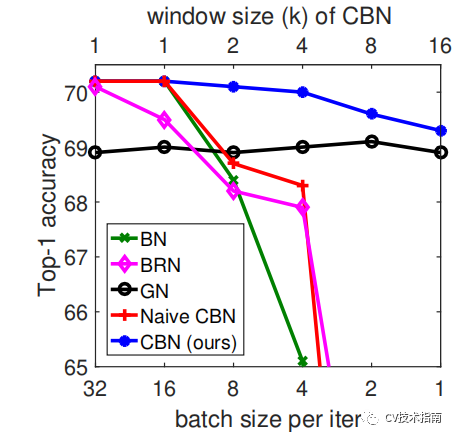
Cross-Iteration BN(2020)
论文:Cross-Iteration Batch Normalization
CBN的主要思想在于将前k-1个iteration的样本参与当前均值和方差的计算。但由于前k-1次iteration的数据更新,因此无法直接拿来使用。论文提出了一个处理方式是通过泰勒多项式来近似计算出前k-1次iteration的数据。
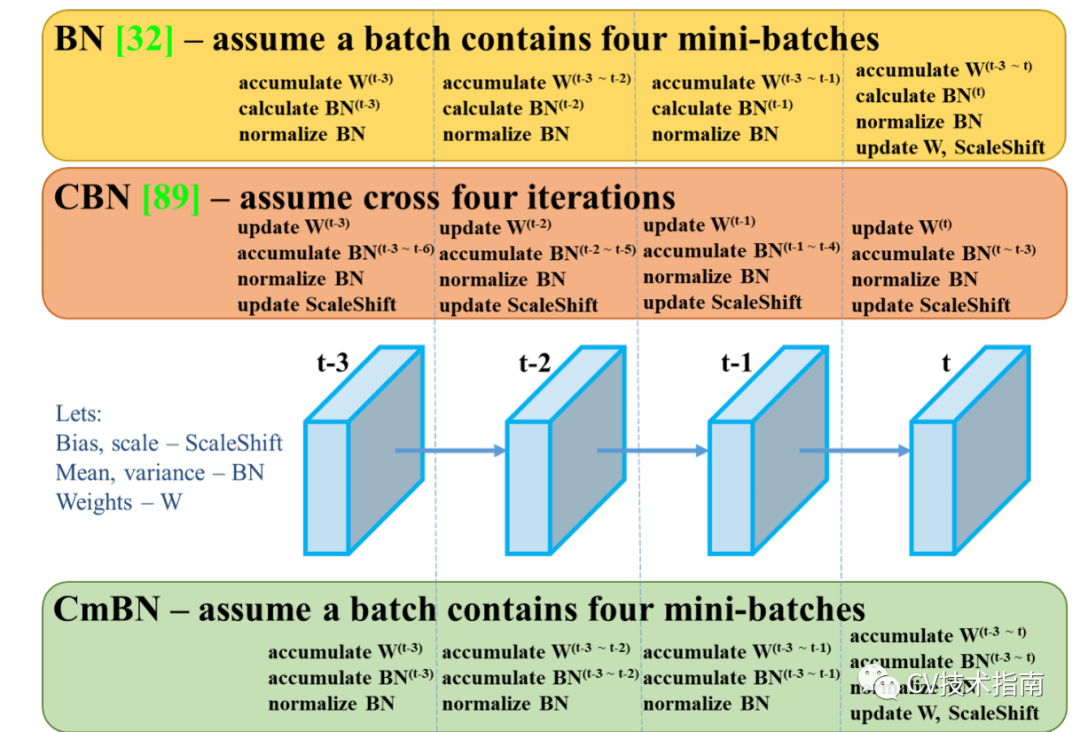
在Yolo_v4中还提出改进版,在每个batch中只统计四个mini-batches的数据,并在第四个mini-batch后才更新权重,尺度缩放和偏移。
实验效果
总结
本文介绍了目前比较经典的归一化方法,其中大部分都是针对BN改进而来,本文比较详尽地介绍了它们的主要思想,改进方式,以及应用场景,部分方法并没有详细介绍实现细节,对于感兴趣或有需要的读者请自行阅读论文原文。
除了以上方法外,还有很多归一化方法,例如Eval Norm,Normalization propagation,Normalizing the normalizers等。但这些方法并不常用,这里不作赘述。
参考论文
1.Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
2.Instance Normalization: The Missing Ingredient for Fast Stylization
3.Layer Normalization
4.Group Normalization
5.Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks
6.Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-Normalized Models
7.MegDet: A Large Mini-Batch Object Detector
8.Filter Response Normalization Layer: Eliminating Batch Dependence in the Training of Deep Neural Networks
9.Cross-Iteration Batch Normalization
10.YOLOv4: Optimal Speed and Accuracy of Object Detection
11.EvalNorm: Estimating Batch Normalization Statistics for Evaluation
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“79”获取CVPR 2021:TransT 直播链接~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
