
10个重要问题概览Transformer全部内容
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


来自|知乎 作者丨张春阳
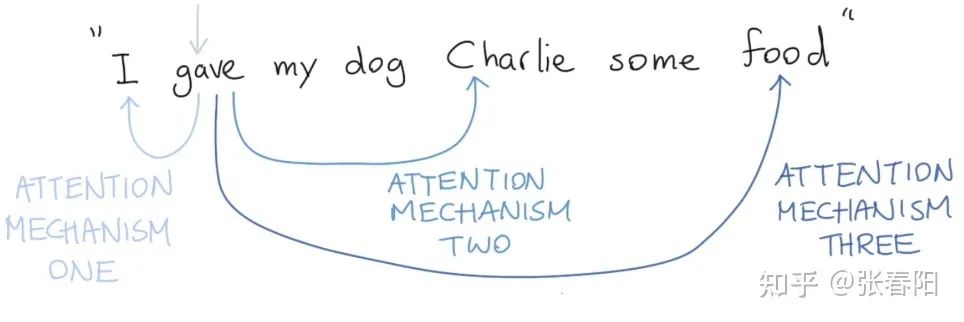
Attention 机制是用来做什么的 ?
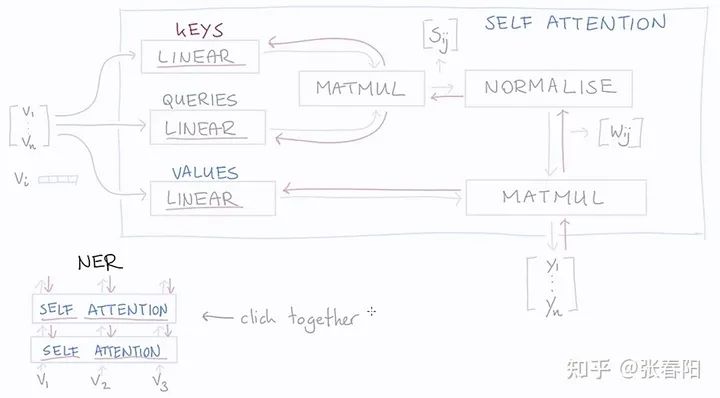
Self-attention 是怎么从 Attention 过度过来的 ?
Attention 和 self-attention 的区别是什么 ?
Self-attention 为什么能 work ?
怎么用 Pytorch 实现 self-attention ?
Transformer 的作者对 self-attention 做了哪些 tricks ?
怎么用 Pytorch/Tensorflow2.0 实现在 Transfomer 中的 self-attention ?
完整的 Transformer Block 是什么样的?
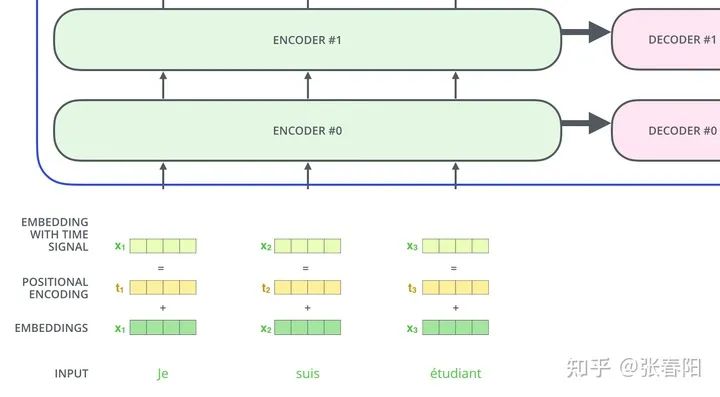
怎么捕获序列中的顺序信息呢 ?
怎么用 Pytorch 实现一个完整的 Transformer 模型?
Attention 机制是用来做什么的 ?




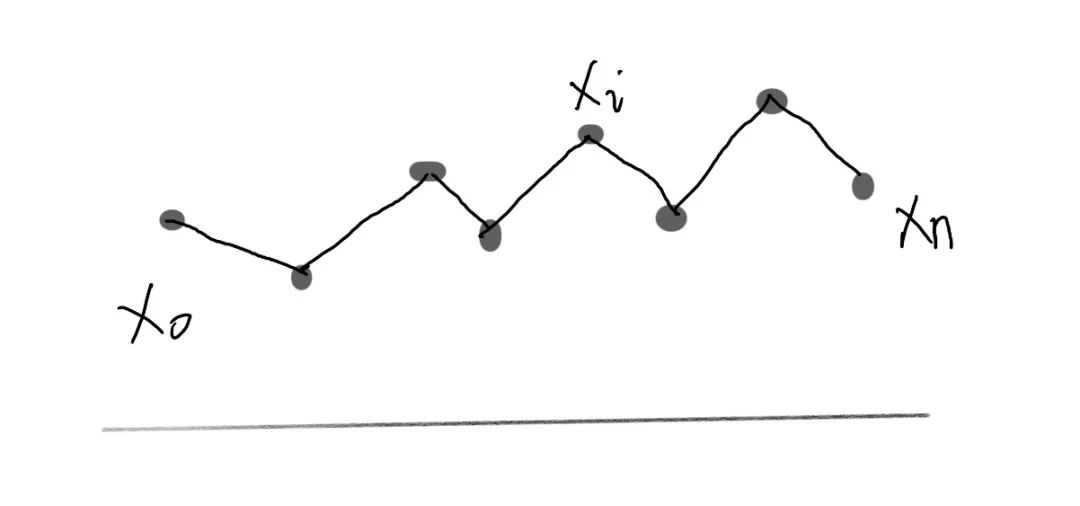
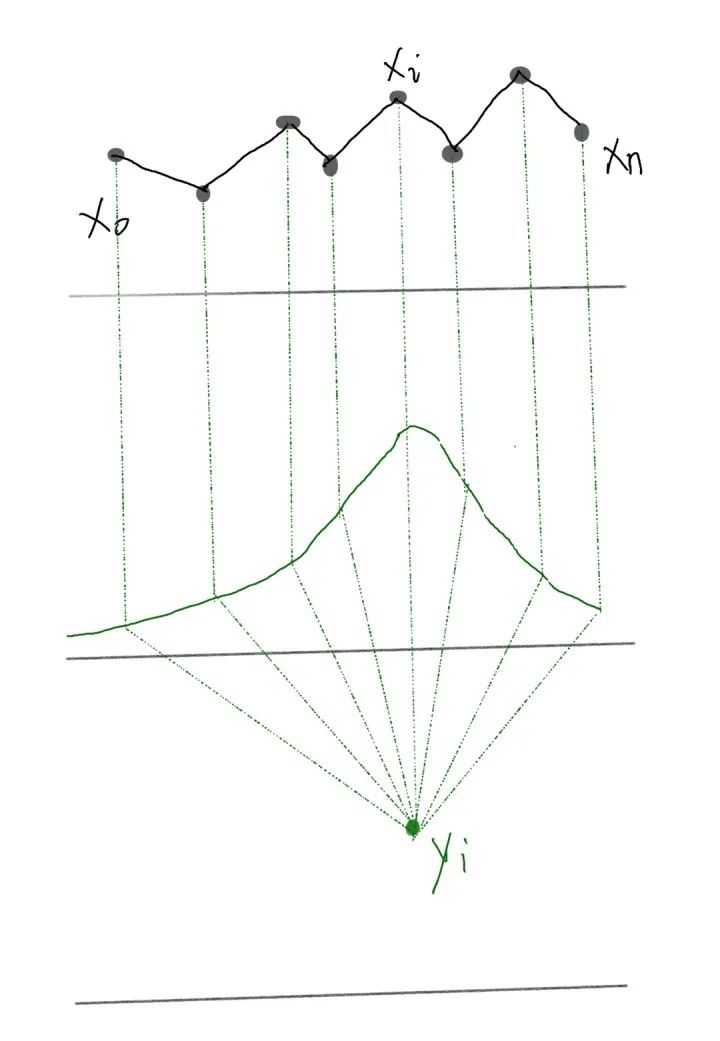
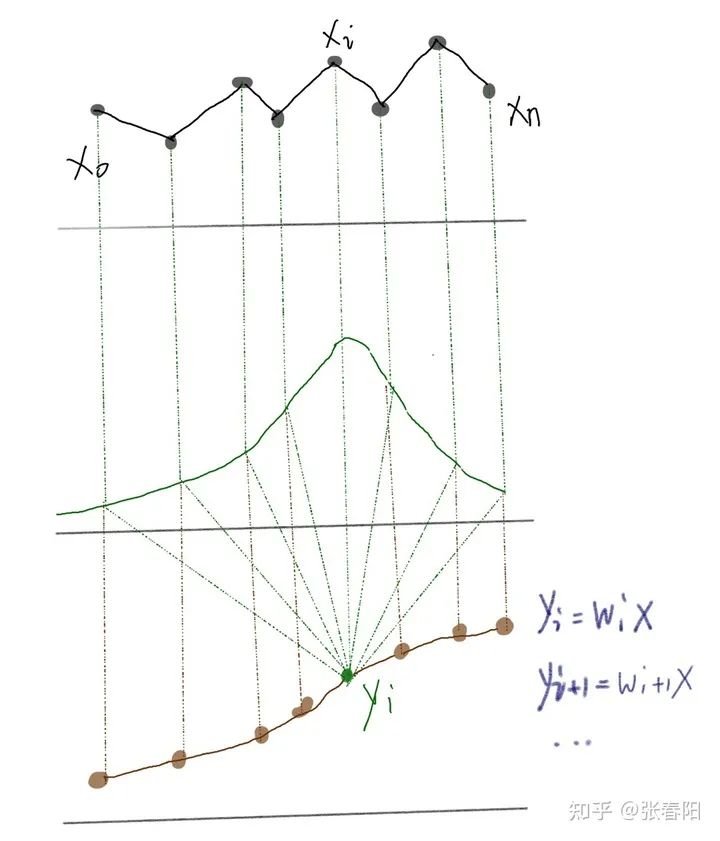
Self-attention 是怎么从 Attention 过度过来的 ?
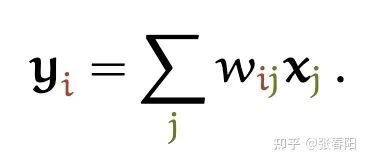
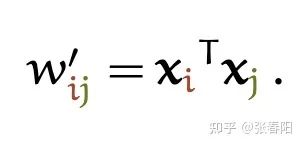
和 是一对输入和输出。对于下一个输出的向量 ,我们有一个全新的输入序列和一个不同的权重值。
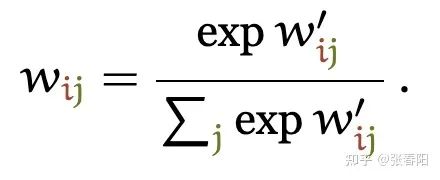
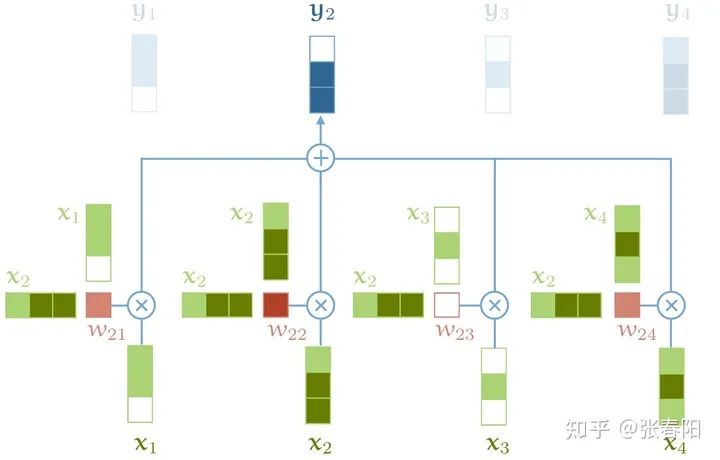
Attention 和 self-attention 的区别是什么 ?
在神经网络中,通常来说你会有输入层(input),应用激活函数后的输出层(output),在RNN当中你会有状态(state)。如果attention (AT) 被应用在某一层的话,它更多的是被应用在输出或者是状态层上,而当我们使用self-attention(SA),这种注意力的机制更多的实在关注input上。 Attention (AT) 经常被应用在从编码器(encoder)转换到解码器(decoder)。比如说,解码器的神经元会接受一些AT从编码层生成的输入信息。在这种情况下,AT连接的是两个不同的组件(component),编码器和解码器。但是如果我们用SA,它就不是关注的两个组件,它只是在关注你应用的那一个组件。那这里他就不会去关注解码器了,就比如说在Bert中,使用的情况,我们就没有解码器。 SA可以在一个模型当中被多次的、独立的使用(比如说在Transformer中,使用了18次;在Bert当中使用12次)。但是,AT在一个模型当中经常只是被使用一次,并且起到连接两个组件的作用。 SA比较擅长在一个序列当中,寻找不同部分之间的关系。比如说,在词法分析的过程中,能够帮助去理解不同词之间的关系。AT却更擅长寻找两个序列之间的关系,比如说在翻译任务当中,原始的文本和翻译后的文本。这里也要注意,在翻译任务重,SA也很擅长,比如说Transformer。 AT可以连接两种不同的模态,比如说图片和文字。SA更多的是被应用在同一种模态上,但是如果一定要使用SA来做的话,也可以将不同的模态组合成一个序列,再使用SA。 对我来说,大部分情况,SA这种结构更加的general,在很多任务作为降维、特征表示、特征交叉等功能尝试着应用,很多时候效果都不错。
Self-attention 为什么能 work ?
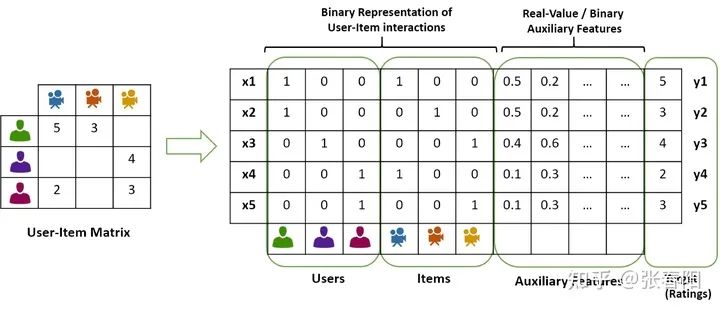
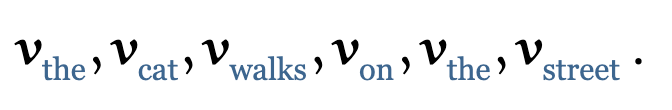
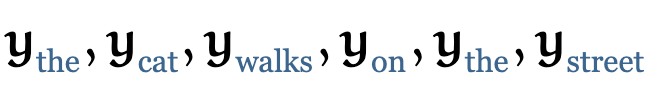
到目前为止,我们还没有用到需要学习的参数。基础的self-attention实际上完全取决于我们创建的输入序列,上游的embeding layer驱动着self-attention学习对于文本语义的向量表示。 Self-attention看到的序列只是一个集合(set),不是一个序列,它并没有顺序。如果我们重新排列集合,输出的序列也是一样的。后面我们要使用一些方法来缓和这种没有顺序所带来的信息的缺失。但是值得一提的是,self-attention本身是忽略序列的自然输入顺序的。
怎么用 Pytorch 实现self-attention ?
我不能实现的,也是我没有理解的。
-- 费曼
import torchimport torch.nn.functional as F# assume we have some tensor x with size (b, t, k)x = ...raw_weights = torch.bmm(x, x.transpose(1, 2))# - torch.bmm is a batched matrix multiplication. It# applies matrix multiplication over batches of# matrices.
weights = F.softmax(raw_weights, dim=2)
y = torch.bmm(weights, x)以上,经过两个简单的矩阵乘法和一个softmax,我们就得到了self-attention。
Transformer 的作者对 Self-attention 做了哪些 tricks ?
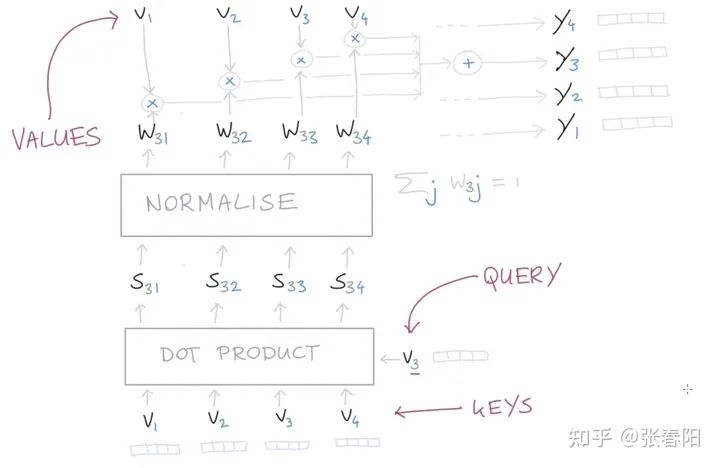
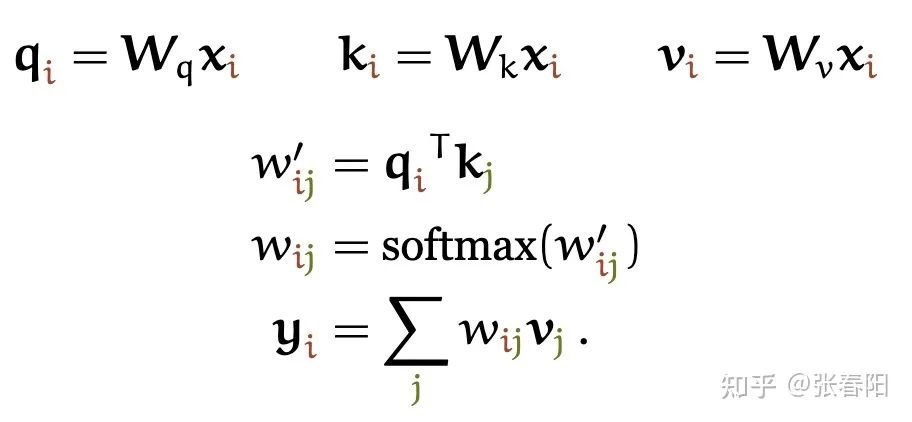
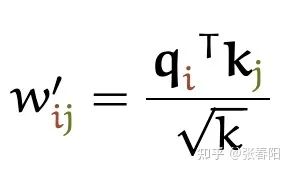
这里分母为什么要使用 呢?我们想象一下,当我们有一个所有的值都为 的在 空间内的值。那它的欧式距离就为 。除以其实就是在除以向量平均的增长长度。
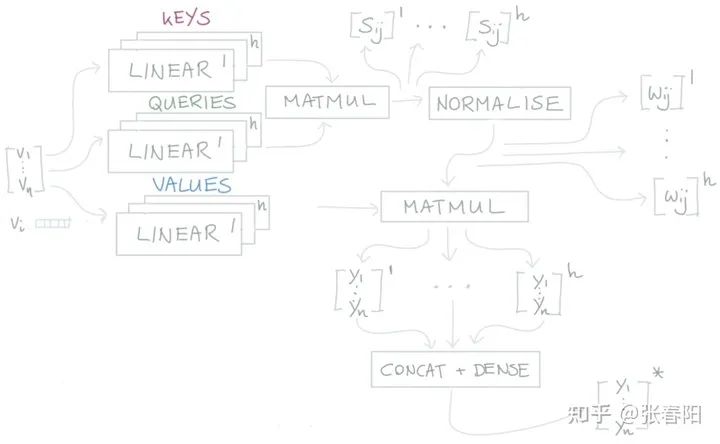
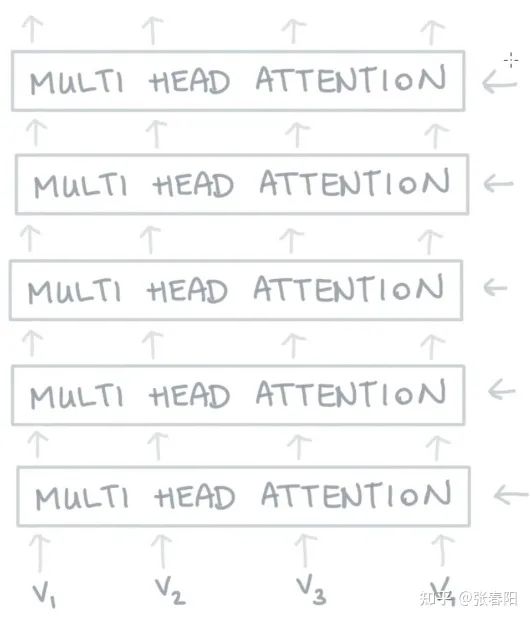
Narrow and wide self-attention
通常,我们有两种方式来实现multi-head的self-attention。默认的做法是我们会把embedding的向量 切割成块,比如说我们有一个256大小的embedding vector,并且我们使用8个attention head,那么我们会把这vector切割成8个维度大小为32的块。对于每一块,我们生成它的queries,keys和values,它们每一个的size都是32,那么也就意味着我们矩阵 的大小都是 。
那还有一种方法是,我们可以让矩阵的大小都是 ,并且把每一个attention head都应用到全部的256维大小的向量上。第一种方法的速度会更快,并且能够更节省内存,第二种方法能够得到更好的结果(同时也花费更多的时间和内存)。这两种方法分别叫做narrow and wide self-attention。
怎么用 Pytorch/Tensorflow2.0 实现在 Transfomer 中的self-attention ?
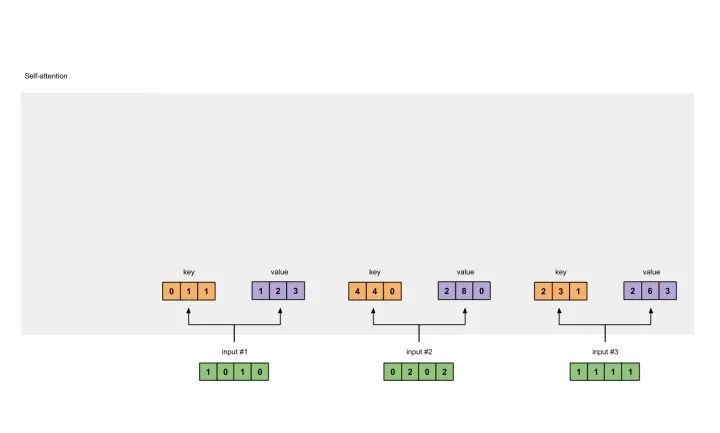
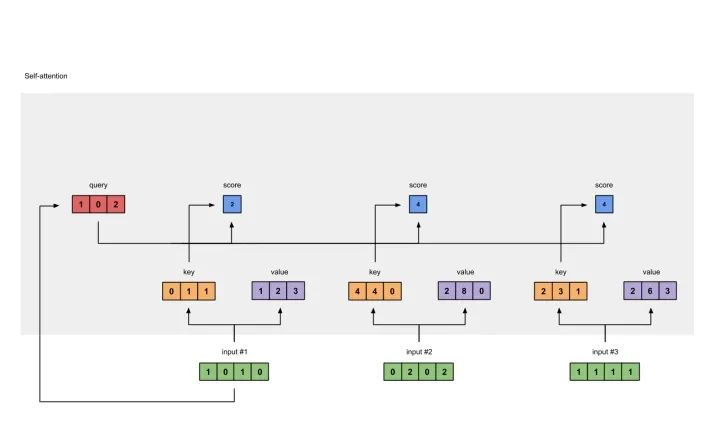
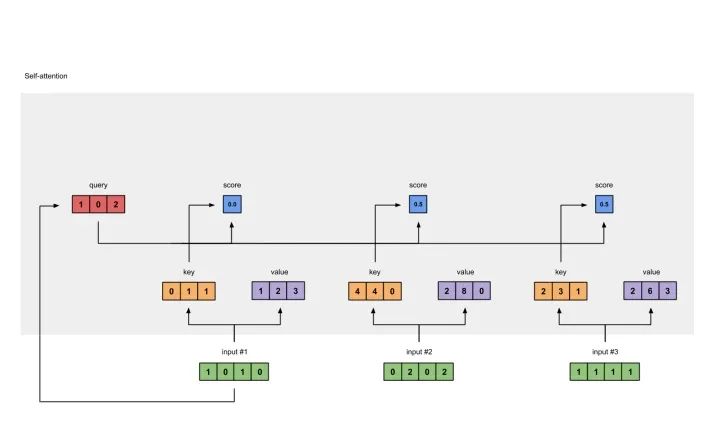
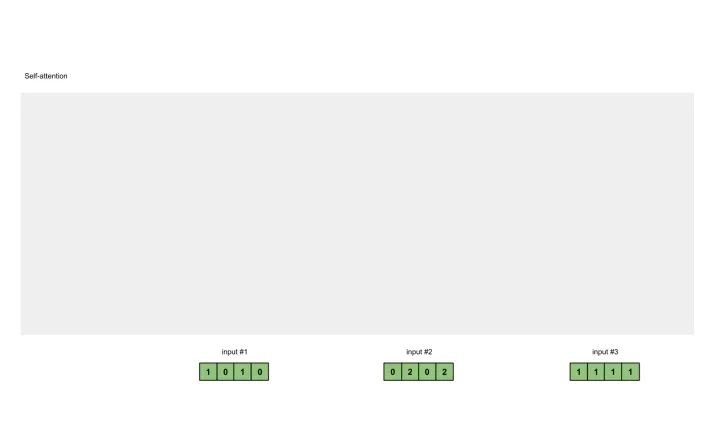
准备输入 初始化参数 获取key,query和value 给input1计算attention score 计算softmax 给value乘上score 给value加权求和获取output1 重复步骤4-7,获取output2,output3
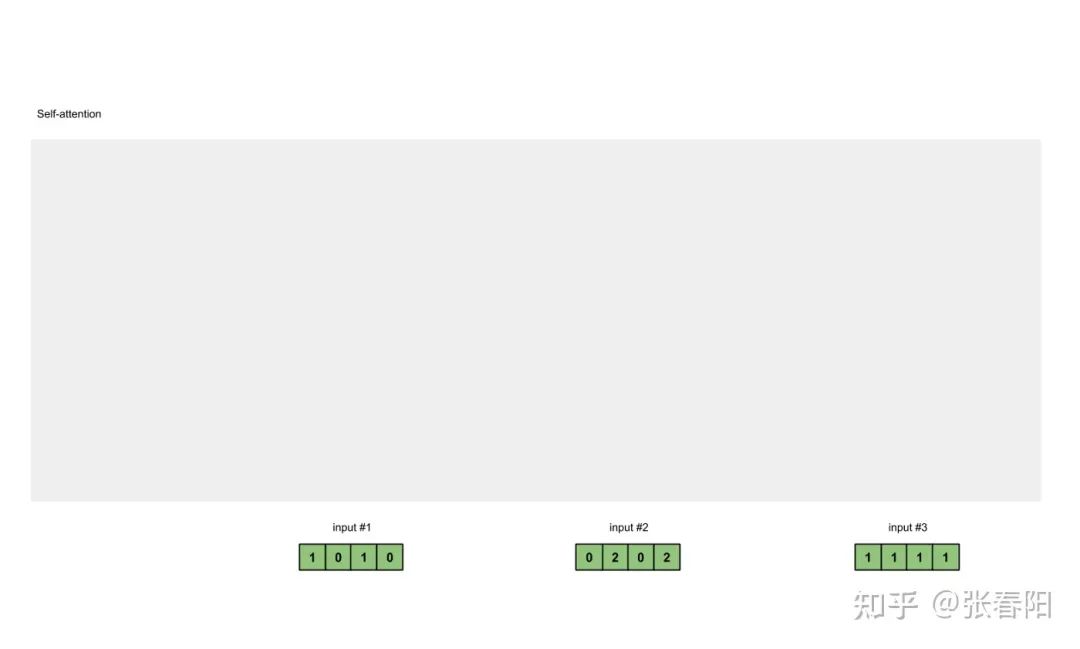
Input 1: [1, 0, 1, 0]Input 2: [0, 2, 0, 2]Input 3: [1, 1, 1, 1]
2 初始化参数

后面我们会看到,value的维度,同样也是我们输出的维度。
[[0, 0, 1],[1, 1, 0],[0, 1, 0],[1, 1, 0]]query的参数:
[[1, 0, 1],[1, 0, 0],[0, 0, 1],[0, 1, 1]]value的参数:
[[0, 2, 0],[0, 3, 0],[1, 0, 3],[1, 1, 0]]
通常在神经网络的初始化过程中,这些参数都是比较小的,一般会在_Gaussian, Xavier and Kaiming distributions随机采样完成。_

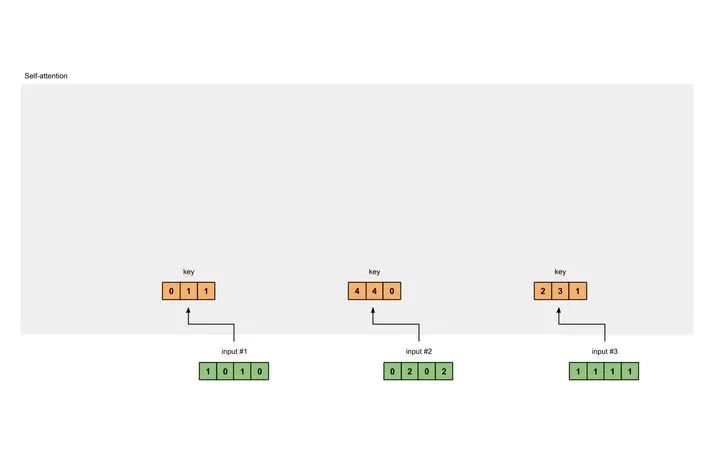
[0, 0, 1][1, 0, 1, 0] x [1, 1, 0] = [0, 1, 1][0, 1, 0][1, 1, 0]
[0, 0, 1][0, 2, 0, 2] x [1, 1, 0] = [4, 4, 0][0, 1, 0][1, 1, 0]
[0, 0, 1][1, 1, 1, 1] x [1, 1, 0] = [2, 3, 1][0, 1, 0][1, 1, 0]
[0, 0, 1][1, 0, 1, 0] [1, 1, 0] [0, 1, 1][0, 2, 0, 2] x [0, 1, 0] = [4, 4, 0][1, 1, 1, 1] [1, 1, 0] [2, 3, 1]
[0, 2, 0][1, 0, 1, 0] [0, 3, 0] [1, 2, 3][0, 2, 0, 2] x [1, 0, 3] = [2, 8, 0][1, 1, 1, 1] [1, 1, 0] [2, 6, 3]
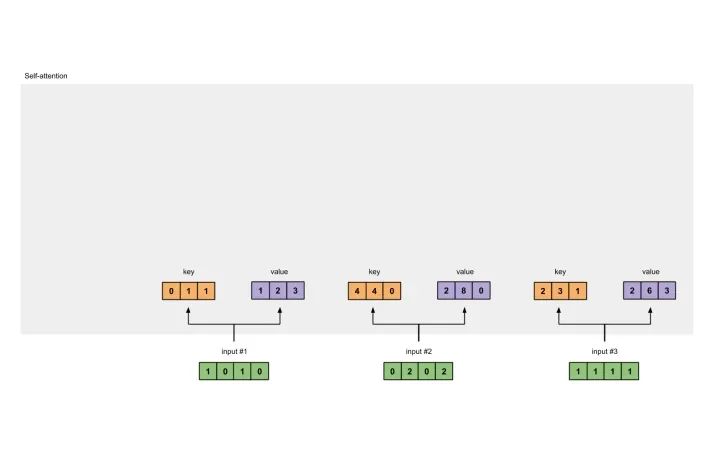
[1, 0, 1][1, 0, 1, 0] [1, 0, 0] [1, 0, 2][0, 2, 0, 2] x [0, 0, 1] = [2, 2, 2][1, 1, 1, 1] [0, 1, 1] [2, 1, 3]
在我们实际的应用中,有可能会在点乘后,加上一个bias的向量。
[0, 4, 2][1, 0, 2] x [1, 4, 3] = [2, 4, 4][1, 0, 1]
softmax([2, 4, 4]) = [0.0, 0.5, 0.5]
1: 0.0 * [1, 2, 3] = [0.0, 0.0, 0.0]2: 0.5 * [2, 8, 0] = [1.0, 4.0, 0.0]3: 0.5 * [2, 6, 3] = [1.0, 3.0, 1.5]
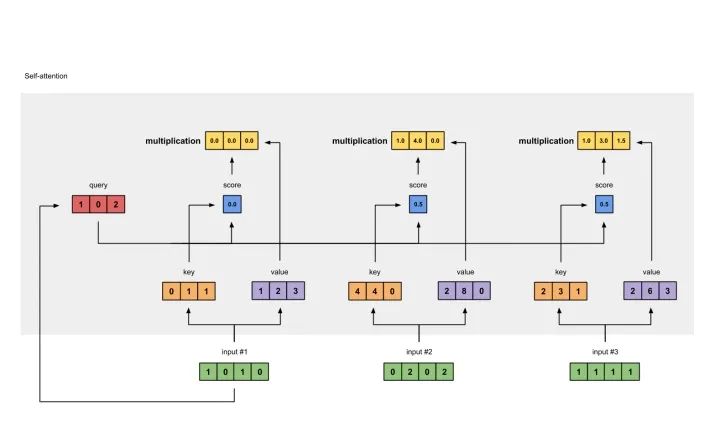
[0.0, 0.0, 0.0]+ [1.0, 4.0, 0.0]+ [1.0, 3.0, 1.5]-----------------= [2.0, 7.0, 1.5]
完整的 Transformer Block 是什么样的?
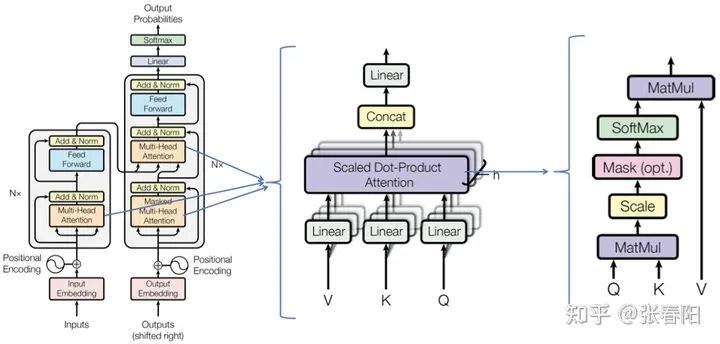
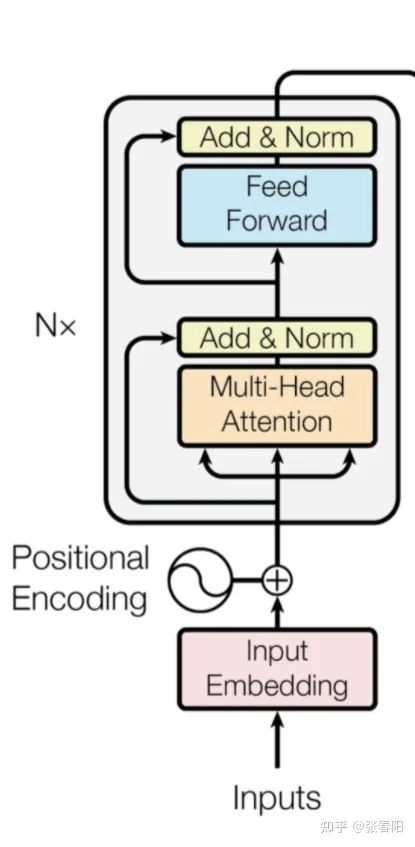
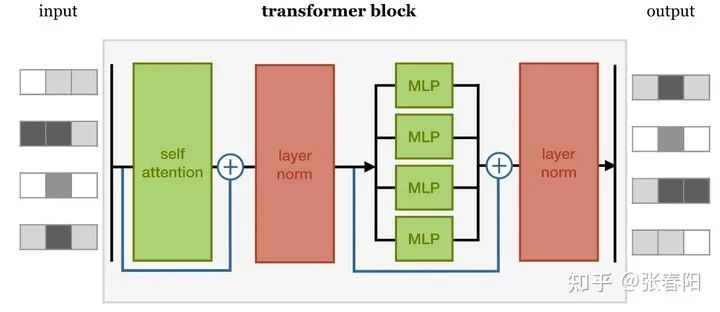
self-attention layer normalization layer feed forward layer another normalization layer
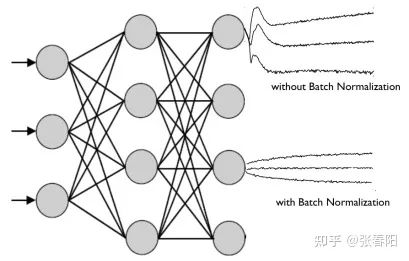
Normaliztion 和 residual connections 是我们经常使用的,帮助加快深度神经网络训练速度和准确率的 tricks。
class TransformerBlock(nn.Module):def __init__(self, k, heads):super().__init__()self.attention = SelfAttention(k, heads=heads)self.norm1 = nn.LayerNorm(k)self.norm2 = nn.LayerNorm(k)self.ff = nn.Sequential(nn.Linear(k, 4 * k),nn.ReLU(),nn.Linear(4 * k, k))def forward(self, x):attended = self.attention(x)x = self.norm1(attended + x)fedforward = self.ff(x)return self.norm2(fedforward + x)
怎么捕获序列中的顺序信息呢 ?
position embeddings
position encodings
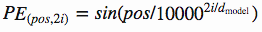
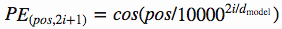
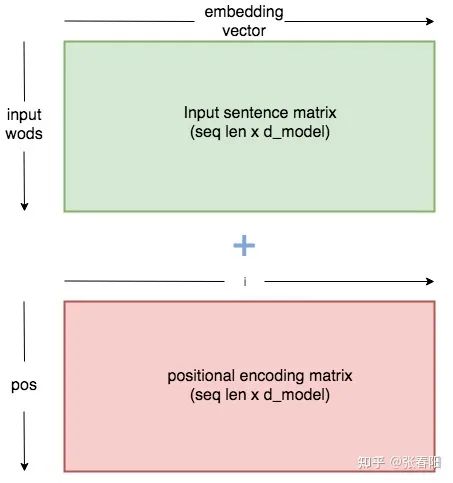
class PositionalEncoder(nn.Module):def __init__(self, d_model, max_seq_len = 80):super().__init__()self.d_model = d_model# 根据pos和i创建一个常量pe矩阵pe = torch.zeros(max_seq_len, d_model)for pos in range(max_seq_len):for i in range(0, d_model, 2):pe[pos, i] = \math.sin(pos / (10000 ** ((2 * i)/d_model)))pe[pos, i + 1] = \math.cos(pos / (10000 ** ((2 * (i + 1))/d_model)))pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):# 让 embeddings vector 相对大一些x = x * math.sqrt(self.d_model)# 增加位置常量到 embedding 中seq_len = x.size(1)x = x + Variable(self.pe[:,:seq_len], \requires_grad=False).cuda()return x
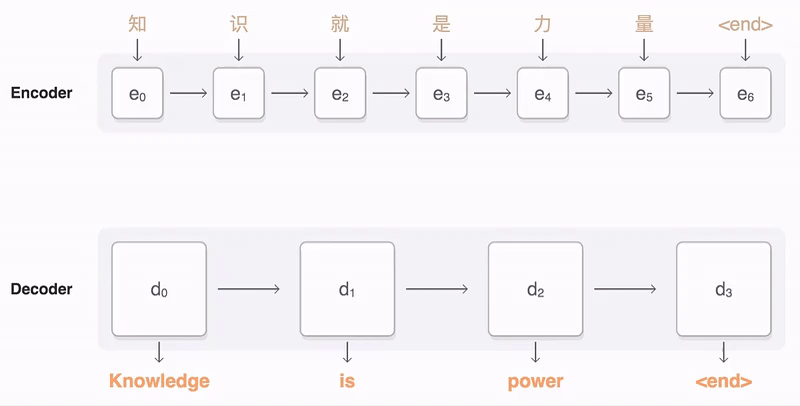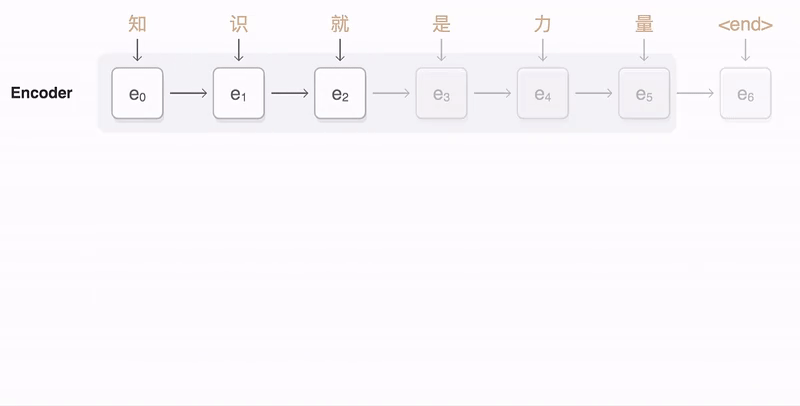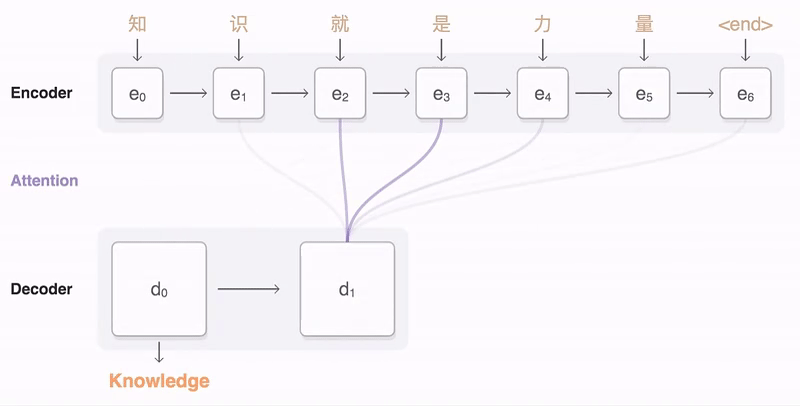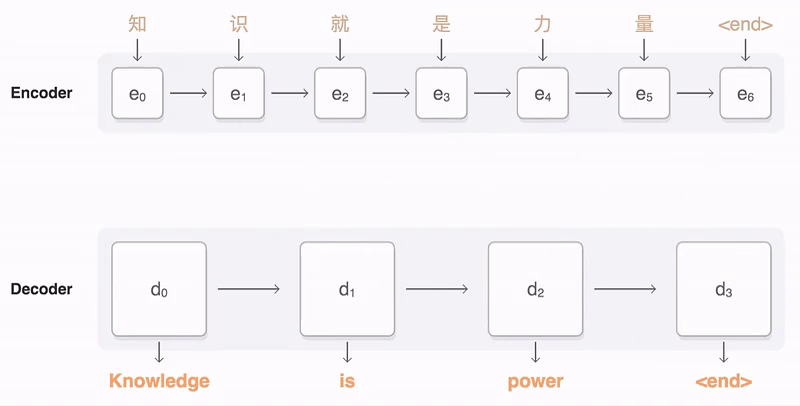
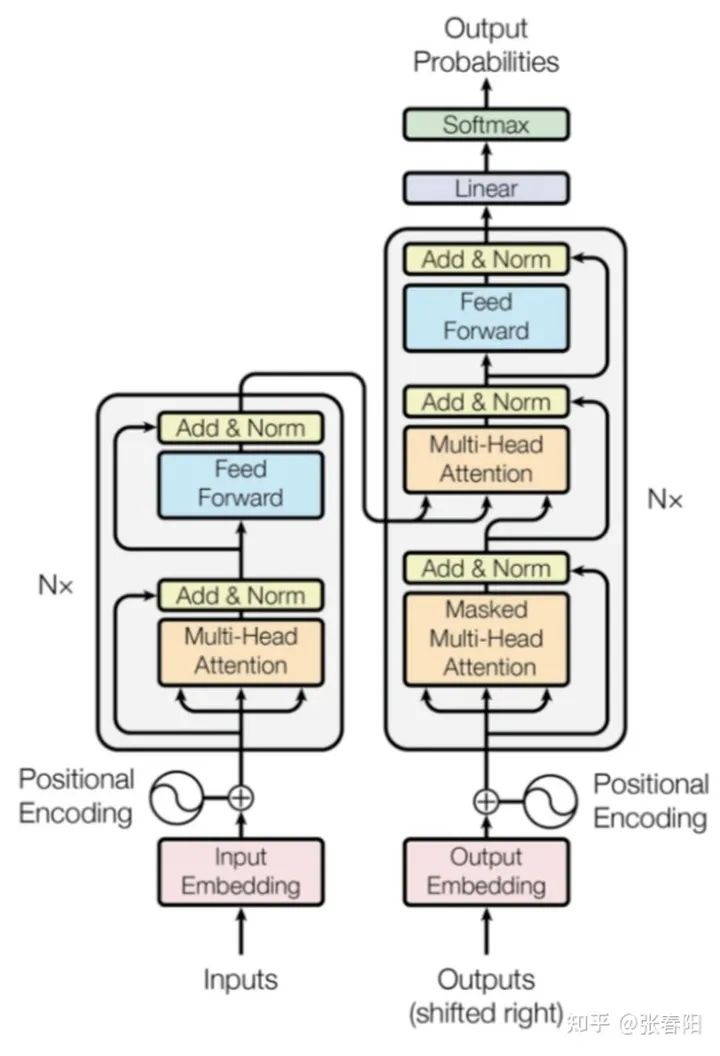
怎么用 Pytorch 实现一个完整的 Transformer 模型?
Tokenize Input Embedding Positional Encoder Transformer Block Encoder Decoder Transformer
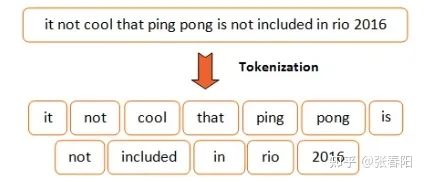
class Tokenize(object):def __init__(self, lang):self.nlp = importlib.import_module(lang).load()def tokenizer(self, sentence):sentence = re.sub(r"[\*\"“”\n\\…\+\-\/\=\(\)‘•:\[\]\|’\!;]", " ", str(sentence))sentence = re.sub(r"[ ]+", " ", sentence)sentence = re.sub(r"\!+", "!", sentence)sentence = re.sub(r"\,+", ",", sentence)sentence = re.sub(r"\?+", "?", sentence)sentence = sentence.lower()return [tok.text for tok in self.nlp.tokenizer(sentence) if tok.text != " "]
class Embedding(nn.Module):def __init__(self, vocab_size, d_model):super().__init__()self.d_model = d_modelself.embed = nn.Embedding(vocab_size, d_model)def forward(self, x):return self.embed(x)
class PositionalEncoder(nn.Module):def __init__(self, d_model, max_seq_len = 80):super().__init__()self.d_model = d_model# 根据pos和i创建一个常量pe矩阵pe = torch.zeros(max_seq_len, d_model)for pos in range(max_seq_len):for i in range(0, d_model, 2):pe[pos, i] = \math.sin(pos / (10000 ** ((2 * i)/d_model)))pe[pos, i + 1] = \math.cos(pos / (10000 ** ((2 * (i + 1))/d_model)))pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):# 让 embeddings vector 相对大一些x = x * math.sqrt(self.d_model)# 增加位置常量到 embedding 中seq_len = x.size(1)x = x + Variable(self.pe[:,:seq_len], \requires_grad=False).cuda()return x
3 Transformer Block
self-attention layer normalization layer feed forward layer another normalization layer
def attention(q, k, v, d_k, mask=None, dropout=None):scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)# mask掉那些为了padding长度增加的token,让其通过softmax计算后为0if mask is not None:mask = mask.unsqueeze(1)scores = scores.masked_fill(mask == 0, -1e9)scores = F.softmax(scores, dim=-1)if dropout is not None:scores = dropout(scores)output = torch.matmul(scores, v)return output
这个 attention 的代码中,使用 mask 的机制,这里主要的意思是因为在去给文本做 batch化的过程中,需要序列都是等长的,不足的部分需要 padding。但是这些 padding 的部分,我们并不想在计算的过程中起作用,所以使用 mask 机制,将这些值设置成一个非常大的负值,这样才能让 softmax 后的结果为0。关于 mask 机制,在 Transformer 中有 attention、encoder 和 decoder 中,有不同的应用,我会在后面的文章中进行解释。
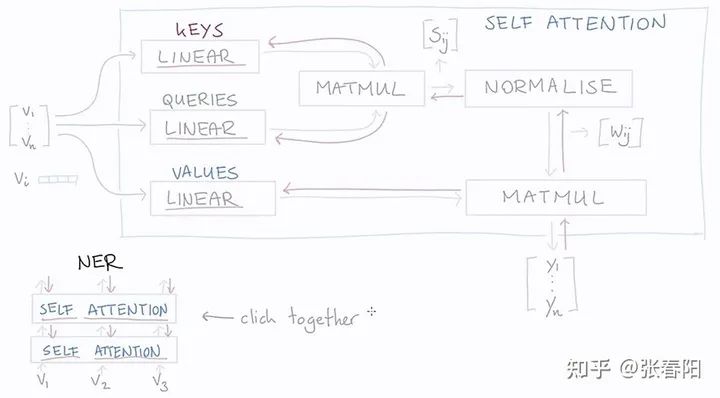
class MultiHeadAttention(nn.Module):def __init__(self, heads, d_model, dropout = 0.1):super().__init__()self.d_model = d_modelself.d_k = d_model // headsself.h = headsself.q_linear = nn.Linear(d_model, d_model)self.v_linear = nn.Linear(d_model, d_model)self.k_linear = nn.Linear(d_model, d_model)self.dropout = nn.Dropout(dropout)self.out = nn.Linear(d_model, d_model)def forward(self, q, k, v, mask=None):bs = q.size(0)k = self.k_linear(k).view(bs, -1, self.h, self.d_k)q = self.q_linear(q).view(bs, -1, self.h, self.d_k)v = self.v_linear(v).view(bs, -1, self.h, self.d_k)k = k.transpose(1,2)q = q.transpose(1,2)v = v.transpose(1,2)scores = attention(q, k, v, self.d_k, mask, self.dropout)concat = scores.transpose(1,2).contiguous()\.view(bs, -1, self.d_model)output = self.out(concat)return output
class NormLayer(nn.Module):def __init__(self, d_model, eps = 1e-6):super().__init__()self.size = d_model# 使用两个可以学习的参数来进行 normalisationself.alpha = nn.Parameter(torch.ones(self.size))self.bias = nn.Parameter(torch.zeros(self.size))self.eps = epsdef forward(self, x):norm = self.alpha * (x - x.mean(dim=-1, keepdim=True)) \/ (x.std(dim=-1, keepdim=True) + self.eps) + self.biasreturn norm
class FeedForward(nn.Module):def __init__(self, d_model, d_ff=2048, dropout = 0.1):super().__init__()# We set d_ff as a default to 2048self.linear_1 = nn.Linear(d_model, d_ff)self.dropout = nn.Dropout(dropout)self.linear_2 = nn.Linear(d_ff, d_model)def forward(self, x):x = self.dropout(F.relu(self.linear_1(x)))x = self.linear_2(x)
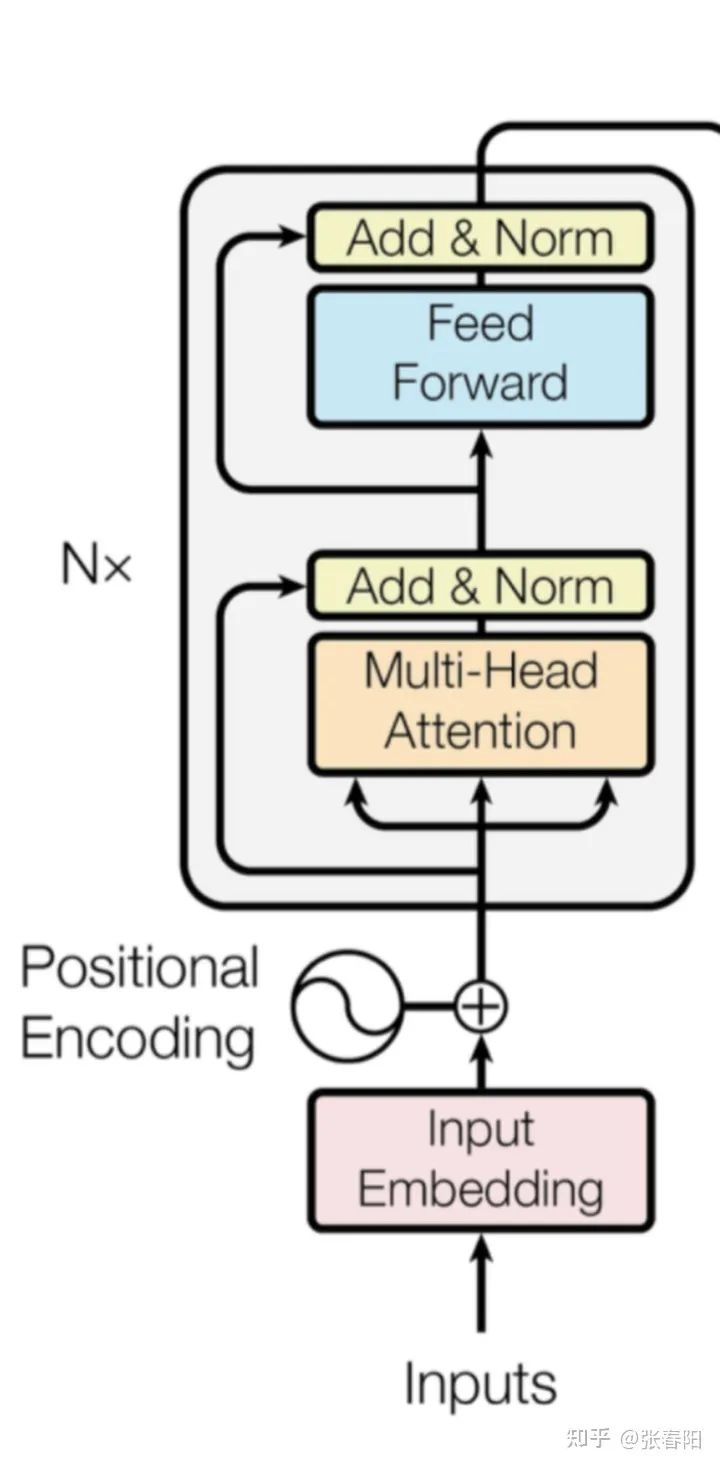
class EncoderLayer(nn.Module):def __init__(self, d_model, heads, dropout=0.1):super().__init__()self.norm_1 = Norm(d_model)self.norm_2 = Norm(d_model)self.attn = MultiHeadAttention(heads, d_model, dropout=dropout)self.ff = FeedForward(d_model, dropout=dropout)self.dropout_1 = nn.Dropout(dropout)self.dropout_2 = nn.Dropout(dropout)def forward(self, x, mask):x2 = self.norm_1(x)x = x + self.dropout_1(self.attn(x2,x2,x2,mask))x2 = self.norm_2(x)x = x + self.dropout_2(self.ff(x2))return xclass Encoder(nn.Module):def __init__(self, vocab_size, d_model, N, heads, dropout):super().__init__()self.N = Nself.embed = Embedder(vocab_size, d_model)self.pe = PositionalEncoder(d_model, dropout=dropout)self.layers = get_clones(EncoderLayer(d_model, heads, dropout), N)self.norm = Norm(d_model)def forward(self, src, mask):x = self.embed(src)x = self.pe(x)for i in range(self.N):x = self.layers[i](x, mask)return self.norm(x)
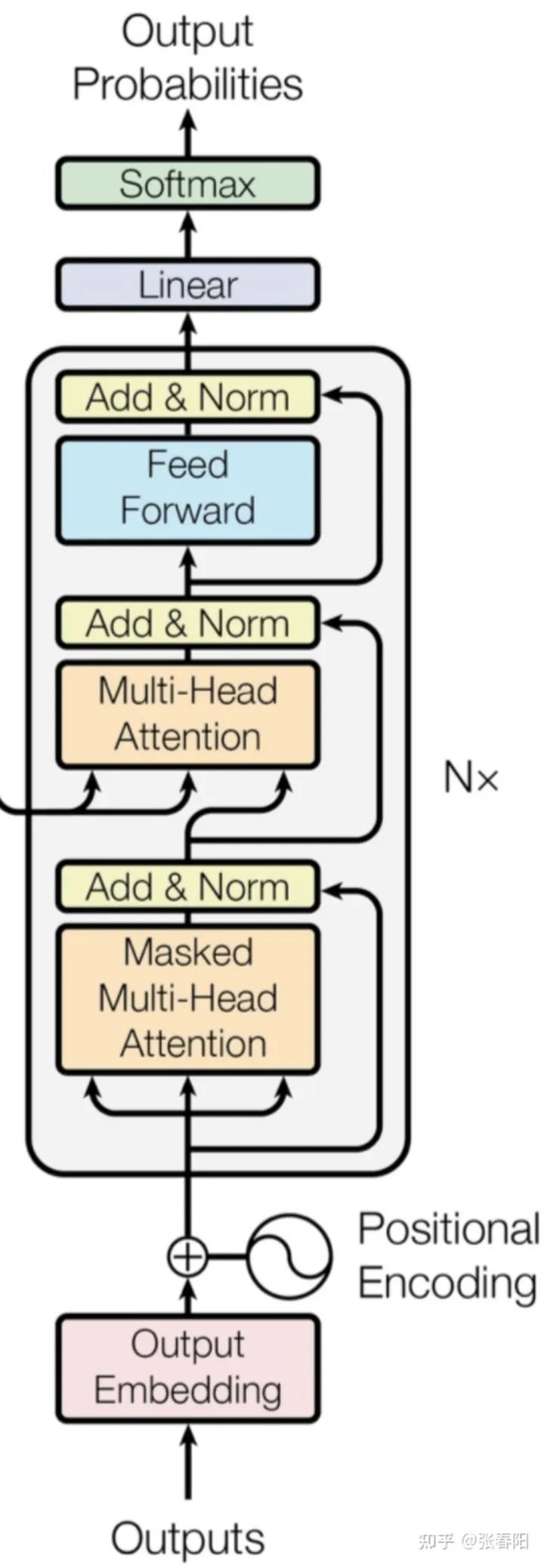
class DecoderLayer(nn.Module):def __init__(self, d_model, heads, dropout=0.1):super().__init__()self.norm_1 = Norm(d_model)self.norm_2 = Norm(d_model)self.norm_3 = Norm(d_model)self.dropout_1 = nn.Dropout(dropout)self.dropout_2 = nn.Dropout(dropout)self.dropout_3 = nn.Dropout(dropout)self.attn_1 = MultiHeadAttention(heads, d_model, dropout=dropout)self.attn_2 = MultiHeadAttention(heads, d_model, dropout=dropout)self.ff = FeedForward(d_model, dropout=dropout)def forward(self, x, e_outputs, src_mask, trg_mask):x2 = self.norm_1(x)x = x + self.dropout_1(self.attn_1(x2, x2, x2, trg_mask))x2 = self.norm_2(x)x = x + self.dropout_2(self.attn_2(x2, e_outputs, e_outputs, \src_mask))x2 = self.norm_3(x)x = x + self.dropout_3(self.ff(x2))return xclass Decoder(nn.Module):def __init__(self, vocab_size, d_model, N, heads, dropout):super().__init__()self.N = Nself.embed = Embedder(vocab_size, d_model)self.pe = PositionalEncoder(d_model, dropout=dropout)self.layers = get_clones(DecoderLayer(d_model, heads, dropout), N)self.norm = Norm(d_model)def forward(self, trg, e_outputs, src_mask, trg_mask):x = self.embed(trg)x = self.pe(x)for i in range(self.N):x = self.layers[i](x, e_outputs, src_mask, trg_mask)return self.norm(x)
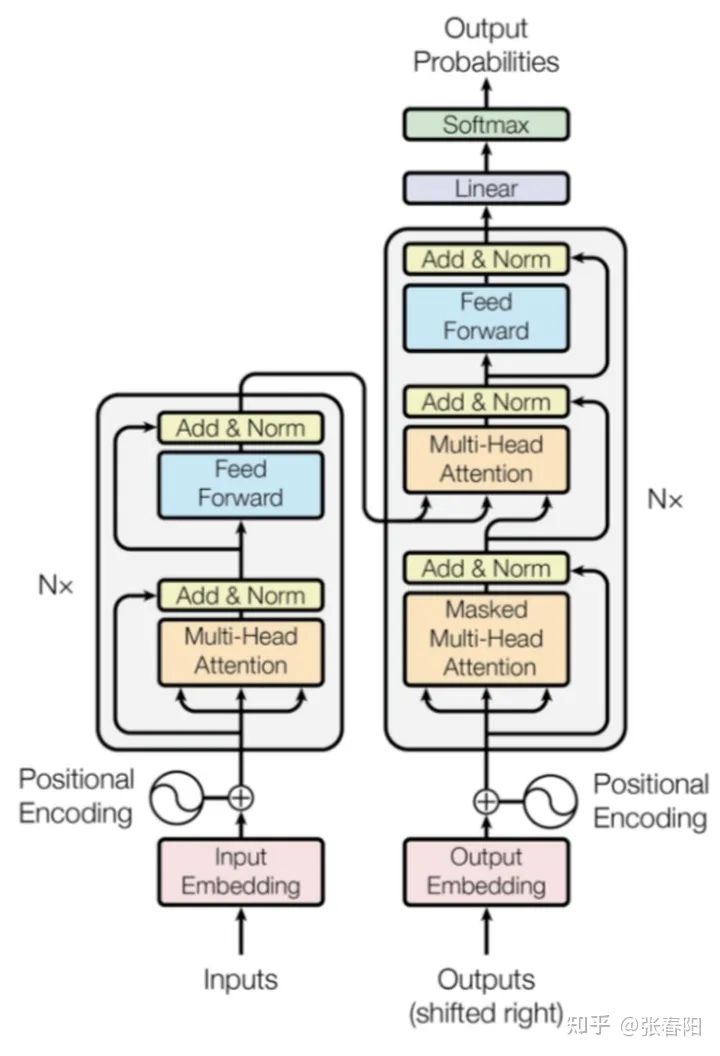
class Transformer(nn.Module):def __init__(self, src_vocab, trg_vocab, d_model, N, heads, dropout):super().__init__()self.encoder = Encoder(src_vocab, d_model, N, heads, dropout)self.decoder = Decoder(trg_vocab, d_model, N, heads, dropout)self.out = nn.Linear(d_model, trg_vocab)def forward(self, src, trg, src_mask, trg_mask):e_outputs = self.encoder(src, src_mask)d_output = self.decoder(trg, e_outputs, src_mask, trg_mask)output = self.out(d_output)return output
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!
评论