
Google团队发布,一文概览Transformer模型的17大高效变种
来源:黄浴知乎 本文约3600字,建议阅读10分钟
本文介绍了去年9月谷歌发表的综述论文“Efficient Transformers: A Survey“,其中介绍道在NLP领域transformer已经是成功地取代了RNN(LSTM/GRU),在CV领域也出现了应用,比如目标检测和图像加注,还有RL领域。


论文题目:
Efficient Transformers: A Survey
论文链接:
https://arxiv.org/pdf/2009.06732
Transformer回顾
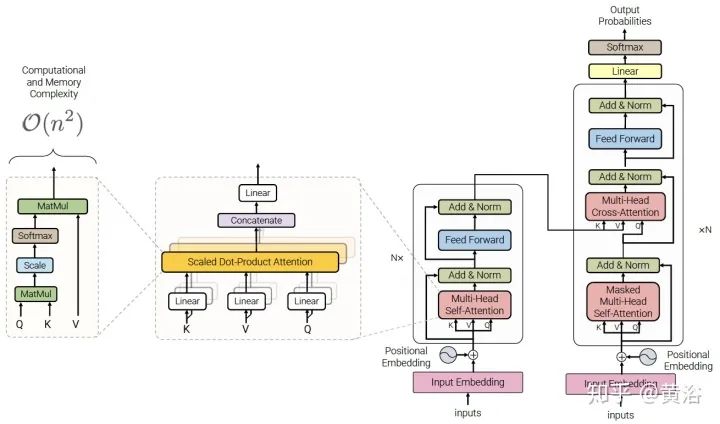

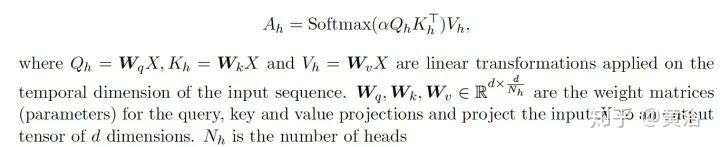




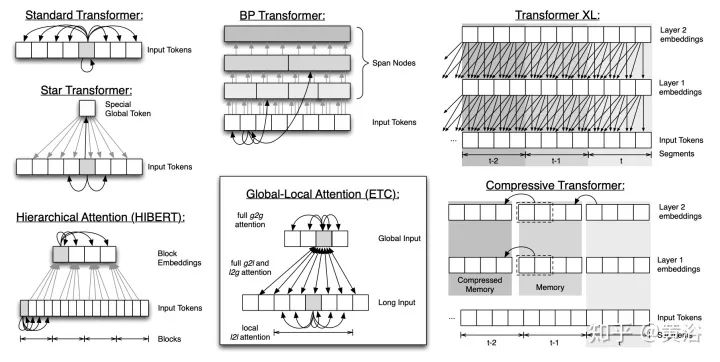
Efficient Transformers
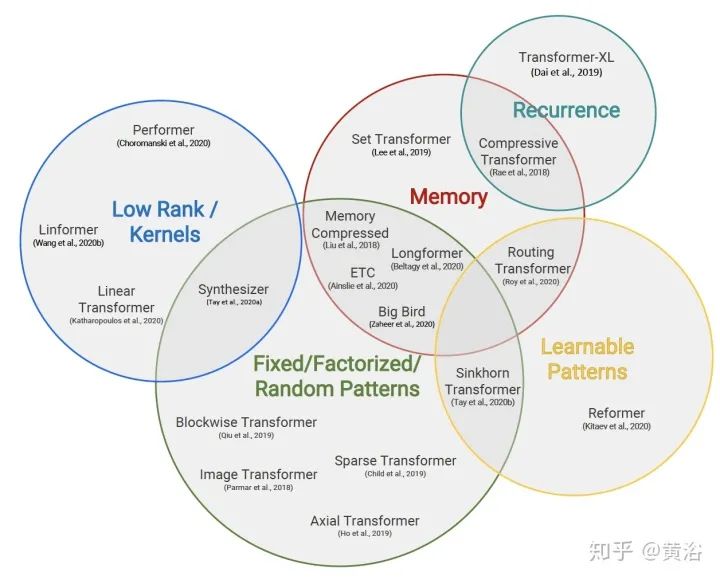
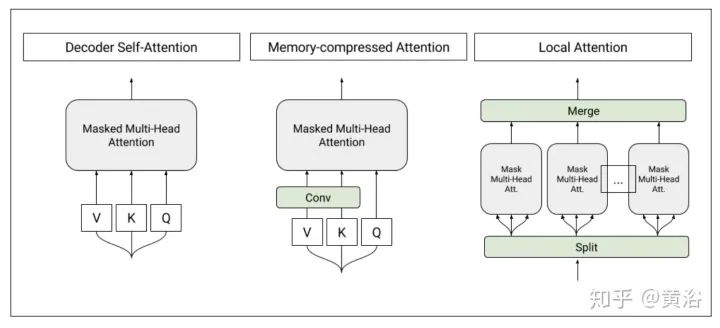
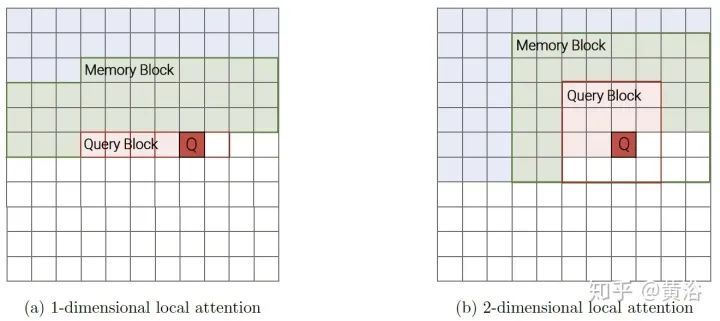
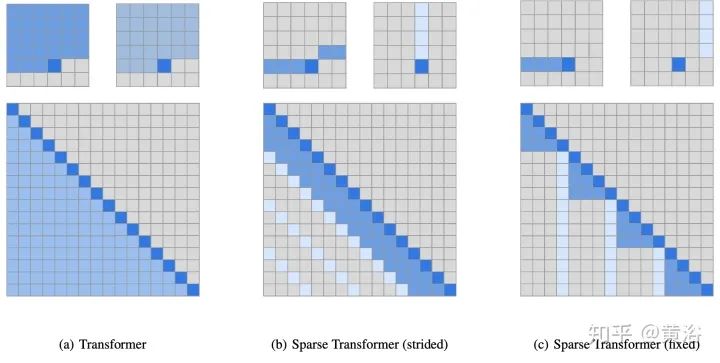
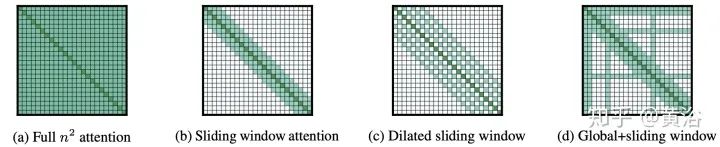
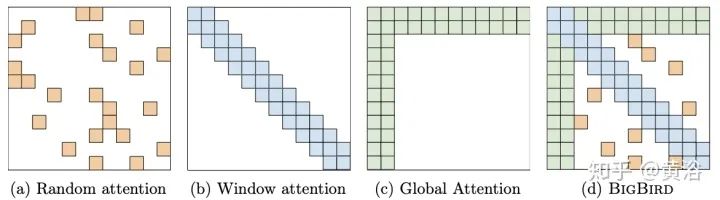
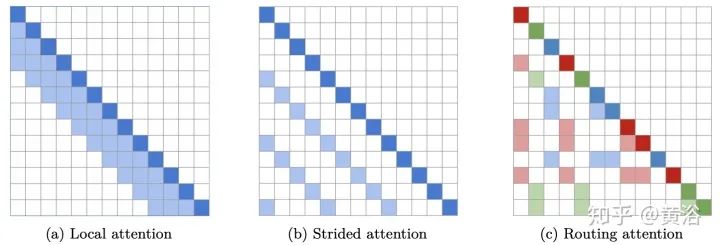
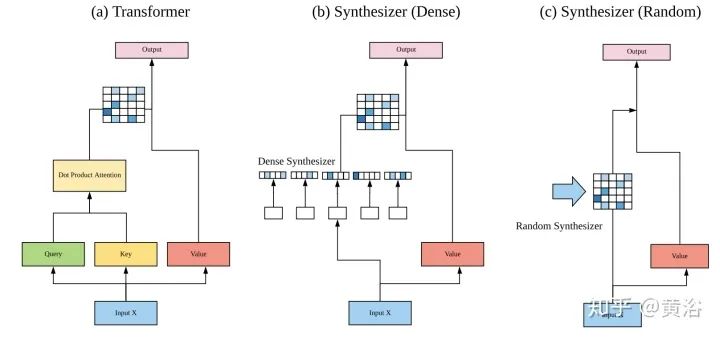
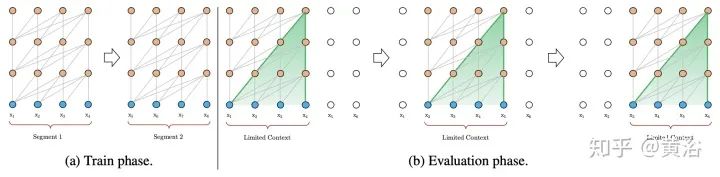
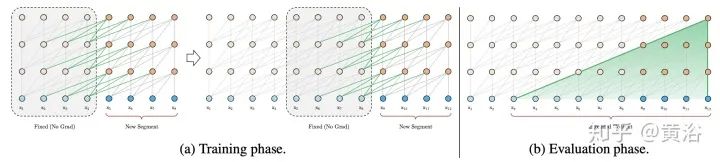
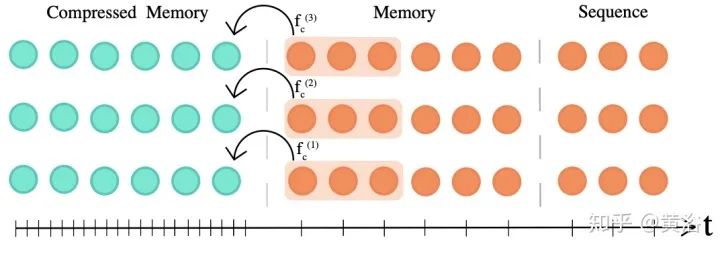
Blockwise Patterns这种技术在实践中最简单的示例是blockwise(或chunking)范式,将输入序列分为固定块,考虑局部接受野(local receptive fields)块。这样的示例包括逐块和/或局部attention。将输入序列分解为块可将复杂度从N^2降低到B^2(块大小),且B << N,从而显著降低了开销。这些blockwise或chunking的方法可作为许多更复杂模型的基础。 Strided patterns是另一种方法,即仅按固定间隔参与。诸如Sparse Transformer和/或Longformer之类的模型,采用“跨越式”或“膨胀式“视窗。 Compressed Patterns是另一条进攻线,使用一些合并运算对序列长度进行下采样,使其成为固定模式的一种形式。例如,Compressed Attention使用跨步卷积有效减少序列长度。
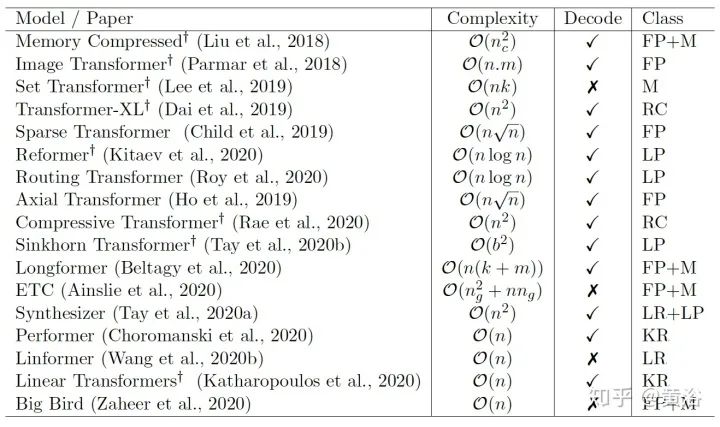
内存和计算复杂度分析

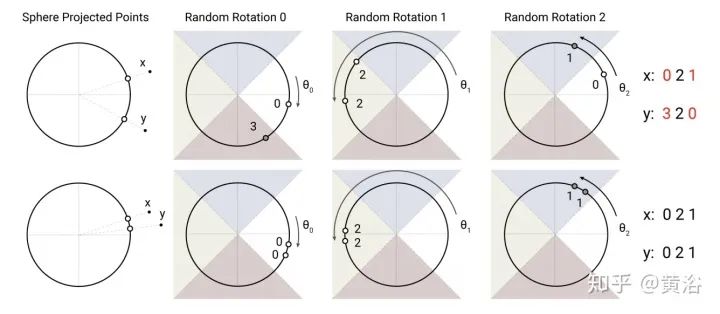
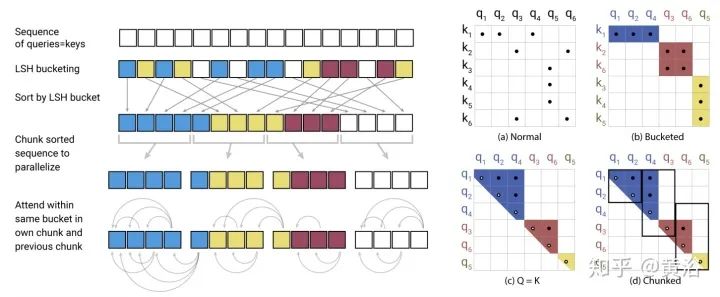
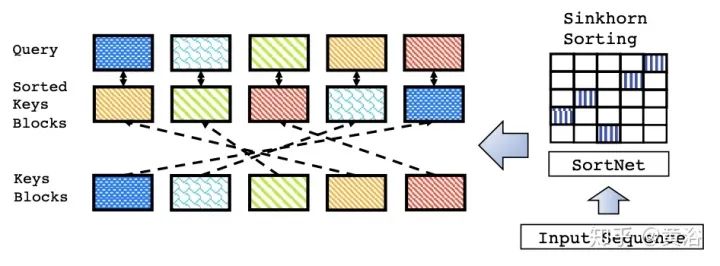
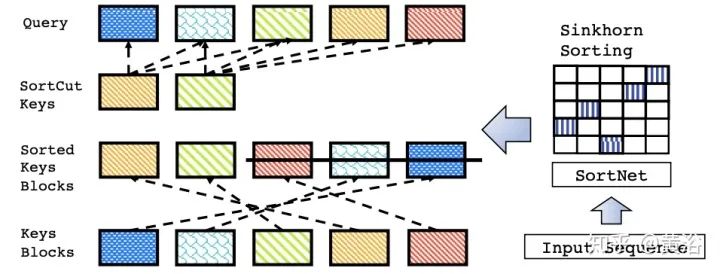


评估基准
效率方面的比较
Weight Sharing
Quantization / Mixed Precision
Knowledge Distillation (KD)
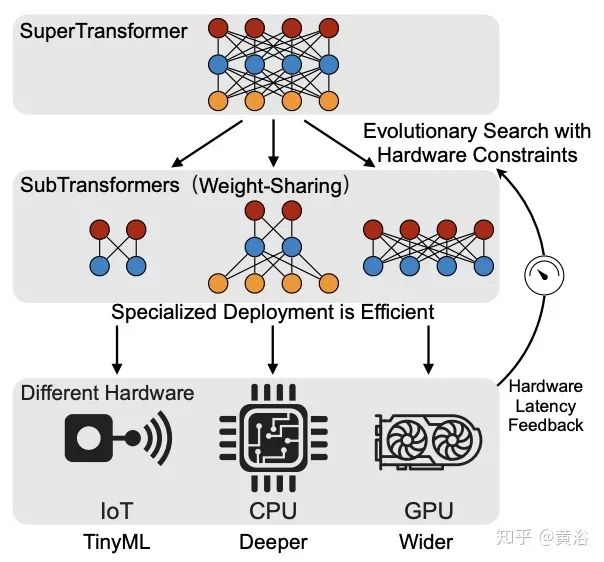
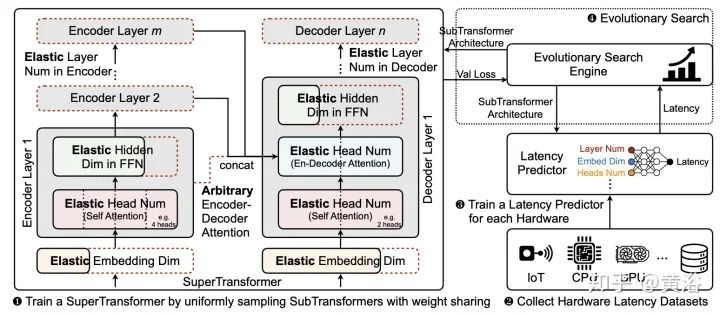
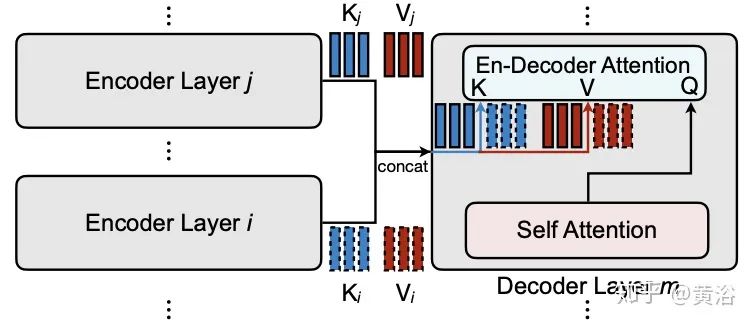
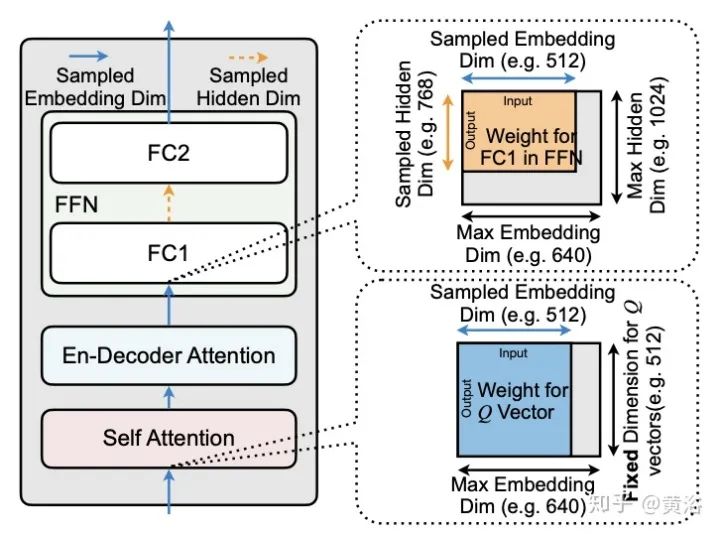
Neural Architecture Search (NAS)
Task Adapters
评论