Transformer预训练模型已经变革NLP领域,一文概览当前现状
来源:机器之心
Transformer 为自然语言处理领域带来的变革已无需多言。近日,印度国立理工学院、生物医学人工智能创业公司 Nference.ai 的研究者全面调查了 NLP 领域中基于 Transformer 的预训练模型,并将调查结果汇集成了一篇综述论文。本文将按大致脉络翻译介绍这篇论文,并重点关注其中的讨论部分,因为研究者在其中指出了该领域新的研究机会。尤其需要说明:研究者将该论文命名为「 AMMUS 」,即 AMMU Smiles,这是为了纪念他们的朋友 K.S.Kalyan。

第 2 节将简单介绍自监督学习,这是 T-PTLM 的核心技术。
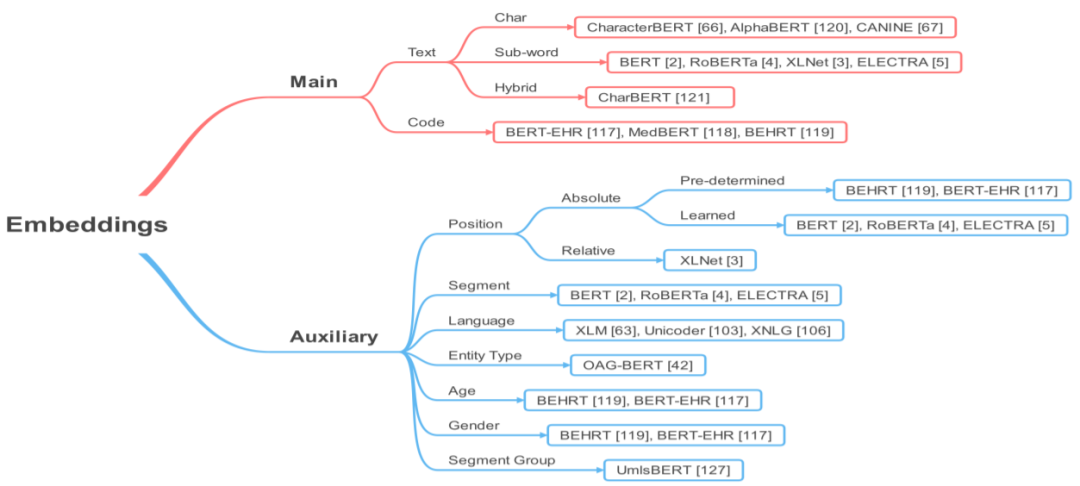
第 3 节将介绍与 T-PTLM 相关的一些核心概念,包括预训练、预训练方法、预训练任务、嵌入和下游适应方法。
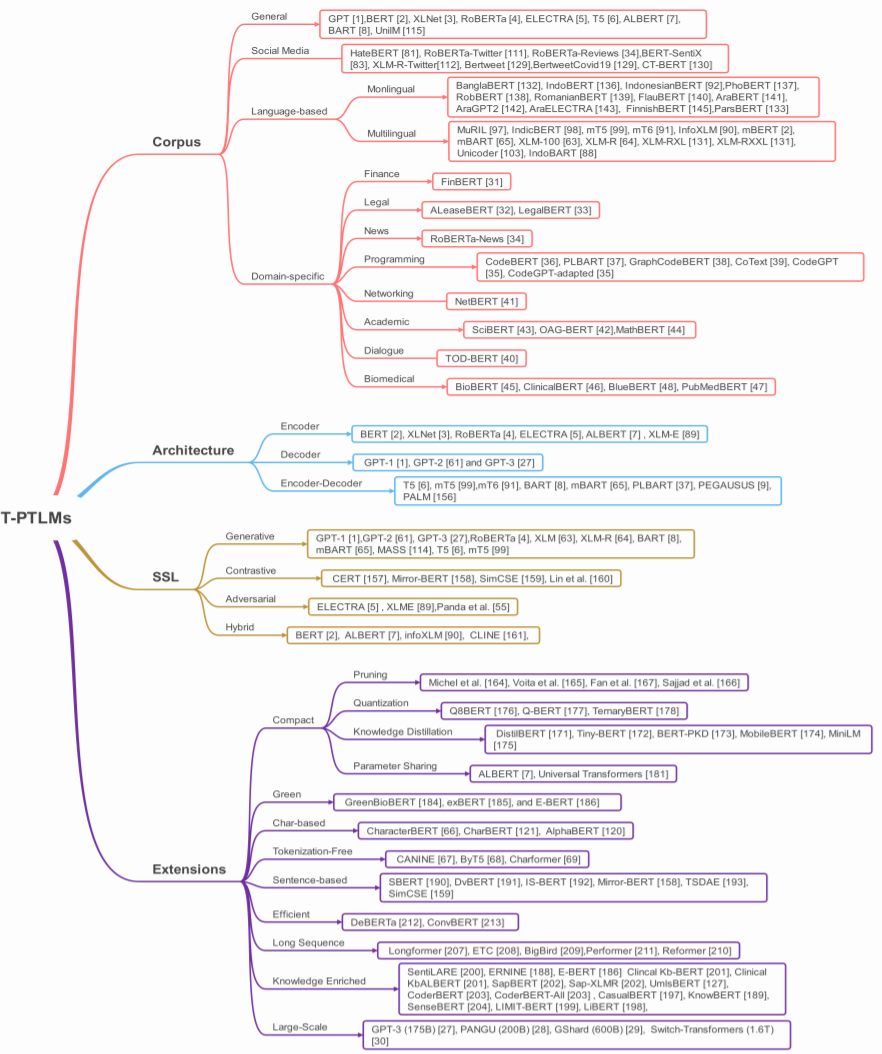
第 4 节将给出一种针对 T-PTLM 的新型分类法。这种分类法考虑了四大方面,即预训练语料库、架构、自监督学习类型和扩展方法。
第 5 节将给出一种针对不同下游适应方法的新型分类法并将详细解释每个类别。
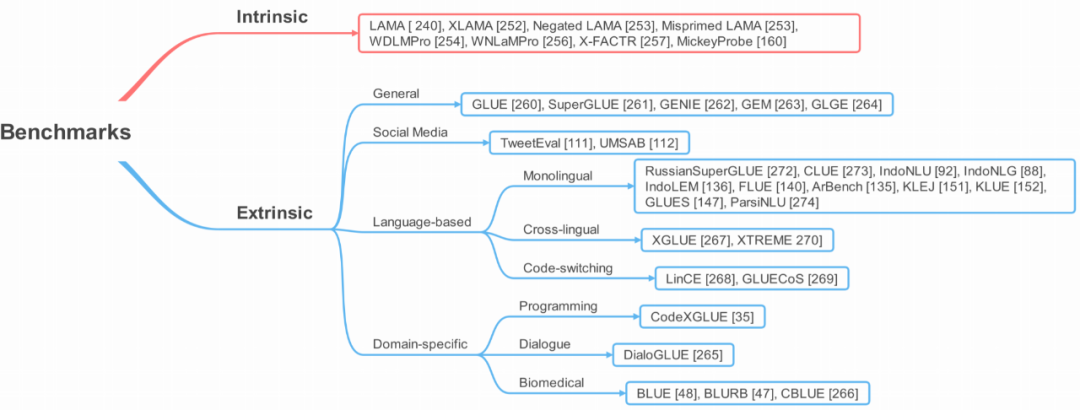
第 6 节将简要介绍多种用于评估 T-PTLM 进展的基准,包括内部基准和外部基准。
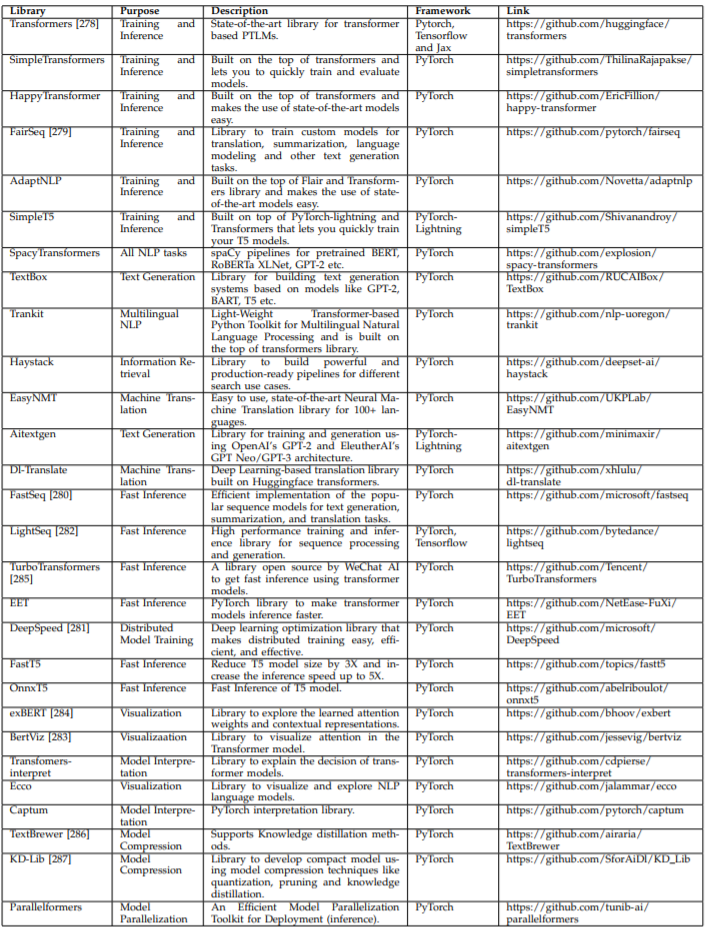
第 7 节将给出一些适用于 T-PTLM 的软件库,从 Huggingface Transformers 到 Transformer-interpret。
第 8 节将简单讨论一些可能有助于进一步改进这些模型的未来研究方向。
严重依赖人类标注的实例,而获取这些实例耗时费力。
缺乏泛化能力,容易出现虚假相关的问题。
医疗和法律等许多领域缺乏有标注数据,这会限制 AI 模型在这些领域的应用。
难以使用大量免费可用的无标注数据进行学习。
学习通用语言表征,这能为下游模型提供优良的背景。
通过学习大量免费可用的无标注文本数据来获得更好的泛化能力。
通过利用大量无标注文本,预训练有助于模型学习通用语言表征。
只需增加一两个特定的层,预训练模型可以适应下游任务。因此这能提供很好的初始化,从而避免从头开始训练下游模型(只需训练特定于任务的层)。
让模型只需小型数据集就能获得更好的表现,因此可以降低对大量有标注实例的需求。
深度学习模型由于参数数量大,因此在使用小型数据集训练时,容易过拟合。而预训练可以提供很好的初始化,从而可避免在小型数据集上过拟合,因此可将预训练视为某种形式的正则化。
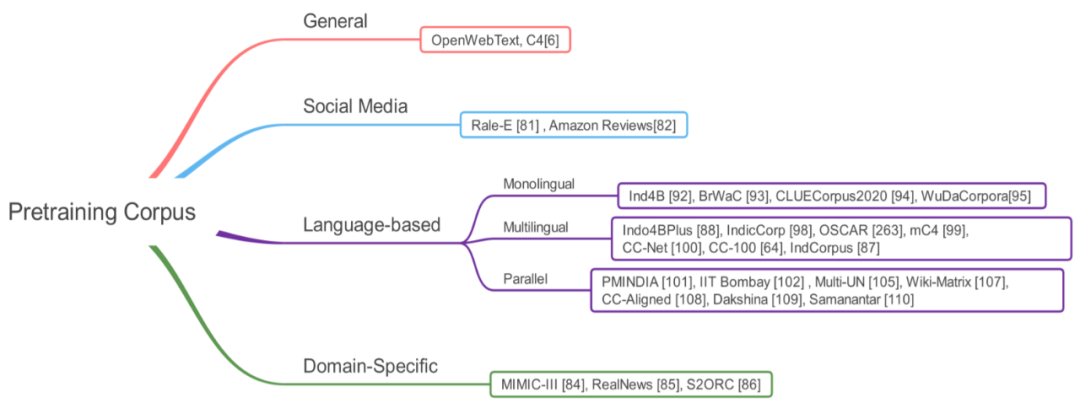
准备预训练语料库
生成词汇库
设计预训练任务
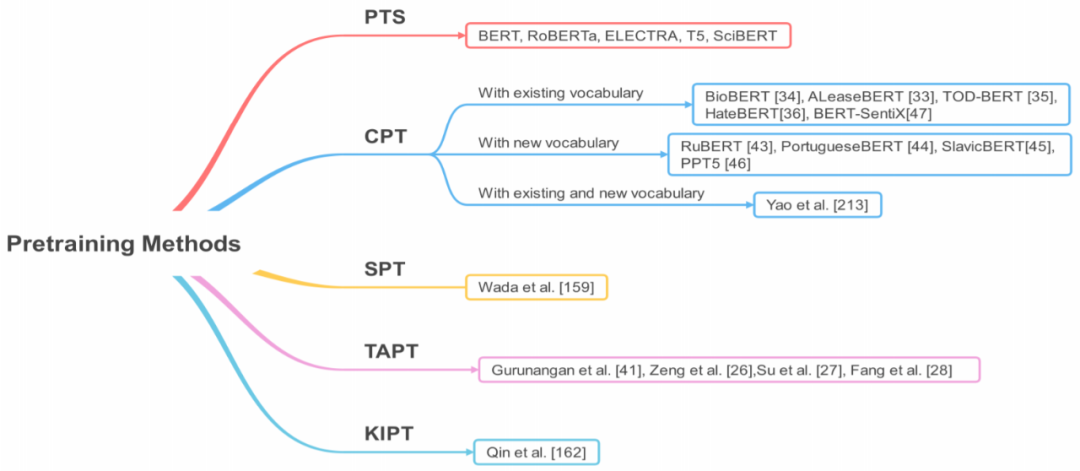
选择预训练方法
选择预训练动态
闲聊语言建模(CLM)
掩码语言建模(MLM)
替代 token 检测(RTD)
混洗 token 检测(STD)
随机 token 替换(RTS)
互换语言建模(SLM)
翻译语言建模(TLM)
替代语言建模(ALM)
句子边界目标(SBO)
下一句子预测(NSP)
句子顺序预测(SOP)
序列到序列语言模型(Seq2SeqLM)
去噪自动编码器(DAE)