
【源头活水】Transformer in CV—— Vision Transformer
更多内容、请置顶或星标
“问渠那得清如许,为有源头活水来”,通过前沿领域知识的学习,从其他研究领域得到启发,对研究问题的本质有更清晰的认识和理解,是自我提高的不竭源泉。为此,我们特别精选论文阅读笔记,开辟“源头活水”专栏,帮助你广泛而深入的阅读科研文献,敬请关注。
地址:https://www.zhihu.com/people/lim0-34
图片数据是如何被编码为Transformer能够处理的形式的 Transformer以及其中核心的self attention机制是如何work的
01
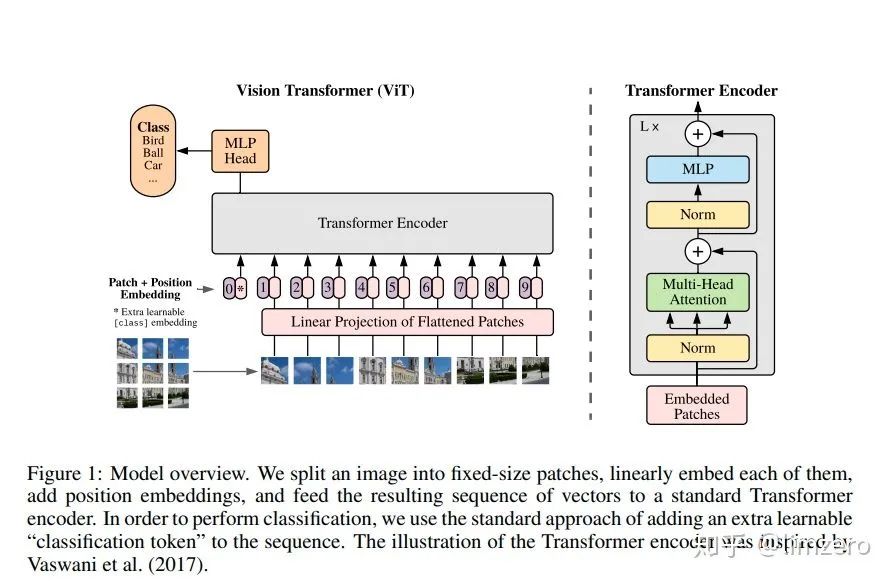
class ViT(nn.Module):def __init__(self, *, image_size, patch_size, num_classes, dim, transformer, pool = 'cls', channels = 3):super().__init__()assert image_size % patch_size == 0, 'image dimensions must be divisible by the patch size'assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'num_patches = (image_size // patch_size) ** 2 #切片数量(2048//32)**2==64**2==4096patch_dim = channels * patch_size ** 2 #一张2048x2048的图被分为32x32大小的4096块,每一块3通道,将每一块展平:32x32x3=3072 所以patch_dim维度为:3072self.patch_size = patch_size #patch_size:16self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))#位置编码:[1,4096+1,dim=512]self.patch_to_embedding = nn.Linear(patch_dim, dim)#将3072维度(像素点)embeding到512维度的空间self.cls_token = nn.Parameter(torch.randn(1, 1, dim))#每一个维度都有一个类别的标志位self.transformer = transformerself.pool = poolself.to_latent = nn.Identity()#占位符self.mlp_head = nn.Sequential(# 分类头nn.LayerNorm(dim),nn.Linear(dim, num_classes))def forward(self, img):p = self.patch_size#32'''#img:[batch, 3, 2048, 2048]#'batch 3 (h 32) (w 32)'->'batch (h,w) (32 32 3)'将图像分块,且每块展平(像素为单位连接起来)'''x = rearrange(img, 'b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = p, p2 = p)#[batch, 4096, 3072] 4096块,每一块展开为3072维向量x = self.patch_to_embedding(x)#[batch, 4096, 512] 将3072维度的像素嵌入到512的空间b, n, _ = x.shapecls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)#[1,1,512]->[b,1,512]x = torch.cat((cls_tokens, x), dim=1)#[batch,4096+1,512]x += self.pos_embedding[:, :(n + 1)]#加上位置编码信息'''以上步骤干的事情:- 输入图片分块->展平:[batch,c,h,w]->[batch,num_patch,c*patch_size*patch_size]- 原始的像素嵌入到指定维度(dim):[batch,num_patch,c*patch_size*patch_size]->[batch,num_patch,dim]- 每一个样本的每一个维度都加入类别token,给分片的图像多加一片,专门用来表示类别- [batch,num_patch,dim]->[batch,num_patch+1,dim]- 给所有的"片(patch)"加入位置编码信息.这里的位置编码初始化为随机数,是通过网络学习出来的以上步骤产生的输出结果即可送入到Transformer里面进行编码[batch,num_patch+1,dim]经过transformer的编码将会出来一个[batch,num_patch+1,dim]的向量'''x = self.transformer(x)#[batch,num_patch+1,dim]->[batch,num_patch+1,dim]x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]#[batch,dim]x = self.to_latent(x)return self.mlp_head(x)
输入图片分块->展平:[batch,c,h,w]->[batch,num_patch,c*patch_size*patch_size] 原始的像素嵌入到指定维度(dim):[batch,num_patch,c*patch_size*patch_size]->[batch,num_patch,dim] 每一个样本的每一个维度都加入类别token,给分片的图像多加一片,专门用来表示类别 [batch,num_patch,dim]->[batch,num_patch+1,dim] 给所有的"片(patch)"加入位置编码信息.这里的位置编码初始化为随机数,是通过网络学习出来的 以上步骤产生的输出结果即可送入到Transformer里面进行编码 [batch,num_patch+1,dim]经过transformer的编码将会出来一个[batch,num_patch+1,dim]的向量
02
class Transformer(nn.Module):def __init__(self, dim, depth=6, heads, dim_head, mlp_dim, dropout):super().__init__()self.layers = nn.ModuleList([])for _ in range(depth):self.layers.append(nn.ModuleList([Residual(PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout))),Residual(PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout)))]))def forward(self, x, mask = None):for attn, ff in self.layers:x = attn(x, mask = mask)x = ff(x)return x
class Attention(nn.Module):def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):super().__init__()inner_dim = dim_head * heads#64*8=512:8个head,每个head:64维.self.heads = headsself.scale = dim ** -0.5#对应Attention公式里面的分母self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)#输入的维度映射到多头注意力机制的维度,将输入处理成qkv矩阵self.to_out = nn.Sequential(nn.Linear(inner_dim, dim),nn.Dropout(dropout))def forward(self, x, mask = None):#x:(batch,num_patch+1,dim)b, n, _, h = *x.shape, self.headsqkv = self.to_qkv(x).chunk(3, dim = -1)#([batch=1,num_patch+1=65,inner_dim=512])# 'batch=1 num_patch=65 (head=8 dim_head=64) -> [batch=1 head=8 num_patch=65 dim_head=64]'q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = h), qkv)'''此时:q,k,v的维度都是[batch=1 head=8 num_patch=65 dim_head=64]'''dots = torch.einsum('bhid,bhjd->bhij', q, k) * self.scale'''(num_patch=65,dim_head=64)*(num_patch=65,dim_head=64)^T->(num_patch=65,num_patch=65),向量的内积可以理解为相似度,q的一行代表了其中的一个patch,k同理,二者相乘,代表了序列中两个patch之间的相似度.这其实类似与信息检索之中的query,key匹配过程,这个相似度就可以作为权重.而v初始化为q,k一样的形状,也代表了输入的每个patch的特征,为了让该特征具有更好的表征能力,每一个patch的特征都应该有其余所有patch(包括该patch自己加权而来,这里的权重即为q*k^T)'''mask_value = -torch.finfo(dots.dtype).max#指定mask_value为dots.dtype下的最小值if mask is not None:mask = F.pad(mask.flatten(1), (1, 0), value = True)assert mask.shape[-1] == dots.shape[-1], 'mask has incorrect dimensions'mask = mask[:, None, :] * mask[:, :, None]dots.masked_fill_(~mask, mask_value)del maskattn = dots.softmax(dim=-1)#注意softmax的维度,按照行进行的softmaxout = torch.einsum('bhij,bhjd->bhid', attn, v)#(num_patch=65,num_patch=65)*(num_patch=65,dim_head=64)->(num_patch=65,dim_head=64)'''此处得到的out可以理解为通过前面的attention矩阵和v获得了对每一个patch(word)的更好的嵌入表示.'''out = rearrange(out, 'b h n d -> b n (h d)')out = self.to_out(out)return out
class FeedForward(nn.Module):def __init__(self, dim, hidden_dim, dropout = 0.):super().__init__()self.net = nn.Sequential(nn.Linear(dim, hidden_dim),nn.GELU(),nn.Dropout(dropout),nn.Linear(hidden_dim, dim),nn.Dropout(dropout))def forward(self, x):return self.net(x)
03
— END —
想要了解更多资讯
点这里👇关注我,记得标星呀~
想要了解更多资讯,请扫描上方二维码,关注机器学习研究
评论