
谈一谈ImageNet预训练网络的形状偏见 (shape bias)
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
考虑到这些二维平面设计图像确实和自然图像存在很大的差异,或者说domain gap,这一结果也并不令人意外。它们单纯以形状传达语义,而没有自然图像中丰富的纹理。为了解决这个问题,我去调研了一下CNN和shape结合的工作,发现了一些有趣的事情。已经有研究者表明,ImageNet上预训练的CNN是对形状有偏见的——
首先问大家三个简单的问题。
这是什么?

是大象的皮。
这又是什么?

是猫。
那下面这个呢?

相信大部分人都会觉得,这是一只猫,一只有着大象外皮纹路的猫。
我们当然希望人类在图像问题上的好朋友,卷积神经网络,也会这么想。事实上呢?看看在ImageNet上预训练的ResNet-50网络对最后一张图给出的结果:
63.9% Indian elephant 26.4% indri 9.6% black swan
令人失望!我们在ImageNet这样的大数据集上一顿暴训,它还是睁着眼睛告诉我们这是一只大象。
划重点!这不是简单的failure case,而是近两年研究者发现的卷积神经网络在ImageNet预训练后出现的对于颜色和纹理的偏好现象。这与人类不同,目前普遍认为,人类主要是通过形状来辨别物体的。对于上面这种形状和纹理有冲突(texture-shape cue conflict)的图像,卷积神经网络更倾向用颜色和纹理来进行预测,而非形状。
研究人员为了证实这个观点,严格遵循心理学实验流程设定,进行了五项实验。
在前四项实验中,研究者将16类共160张白色背景的自然图像做四种不同的变换,分别交给人类被试者和ImageNet上预训练的卷积神经网络做其中物体的识别。这四种变换包括:
转灰度:使用skimage.color.rgb2gray实现 转黑白:二值化方法+人工检查 提取边缘:使用MATLAB实现Canny Edge Extractor 纹理图:使用每类3张共48张纹理图像,如动物的毛发或密集排布的某种物体
实验结果如下所示:
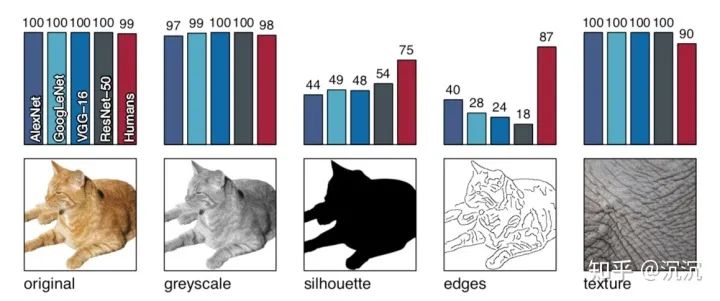
所有的原图和纹理图都可以被人类和神经网络正确地识别;灰度图像也维持了较高的识别率。但来到黑白图和边缘图的时候,人类在识别的准确率上产生了明显的优势,这说明人类可以更好地应对那些纹理较少或几乎没有纹理的图像信息。而对于神经网络,这种图像域的偏移(图像空间和训练空间不一致)带来了不小的麻烦。
第五个实验中,研究人员又祭出了他们的法宝——纹理形状不一致性(cue conflict)。他们使用迭代式风格迁移方法,将纹理图的风格迁移到了一些自然图像上,构造了16类共1280张这种纹理形状不一致的图像,让人类和神经网络进行识别。并观察其在形状和纹理之间的偏好。注意,这不是一个正确与否的问题,仅仅是判断时候的偏好。

一些实验中遇到的纹理形状不一致图像
结果不出所料。红色圆圈表示了不同类别下人类对于纹理和形状的偏好情况,不同的蓝色标志表示了不同神经网络架构(AlexNet、VGG-16、GoogLeNet、ResNet-50)的偏好情况。越靠左说明对形状的偏好性越强,反之说明对于纹理的偏好性越强。虽然各类别图像的情况不甚相同,但也很好地支持了前四个实验的结论。
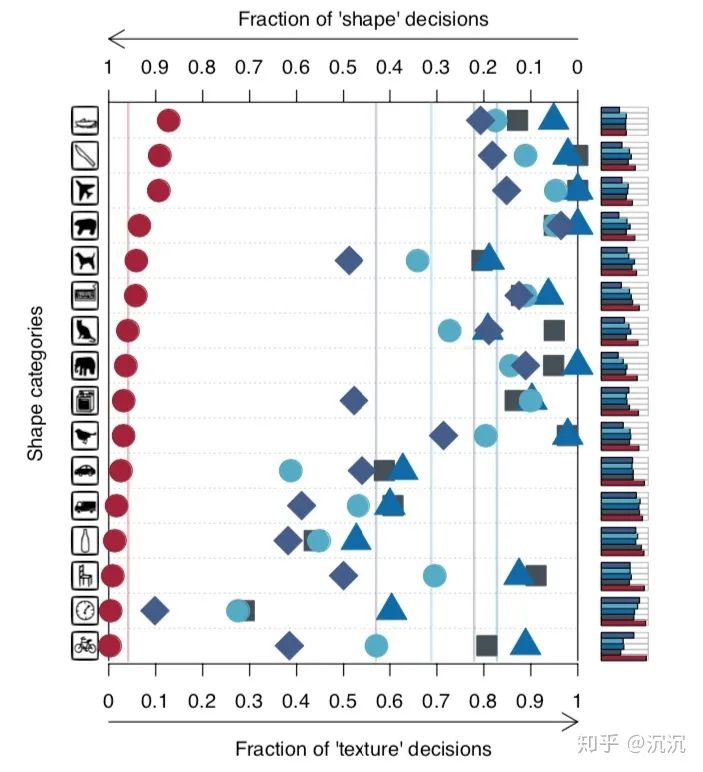
实验五结果可视化
一个对于卷积神经网络工作原理的常见解释是,它通过不断的卷积和池化操作,从提取最简单的边角特征,到不断融合这些浅层特征来表达更为复杂的形状。现在看来,形状并不是卷积神经网络做出判断的主要依据,颜色和纹理才是。这就是所谓的对颜色和纹理的偏好现象。
研究者表明,一个可能的原因是,卷积神经网络仅通过局部的纹理就收集到了足够的信息来做出判断。
多项工作尝试使用不同的方法“扭转”预训练卷积神经网络的这种偏好,实验也证实提高卷积神经网络对形状的偏好可以使提取的特征更加鲁棒、提升分类等任务的准确度。下面简单介绍其中三种。
风格迁移训练
Geirhos等人对ImageNet数据集使用AdaIN方法进行随机的风格迁移(style transfer),构成新的Stylized-ImageNet数据集。原数据集和新数据集分别记为IN和SIN。

Stylized-ImageNet数据样例
通过在IN和SIN上的混合训练以及微调过程,得到的Shape-ResNet模型对于变形失真图像的鲁棒性增强、在ImageNet数据集上的分类准确性和Pascal VOC上目标检测的准确性都有所提升。
域对抗训练
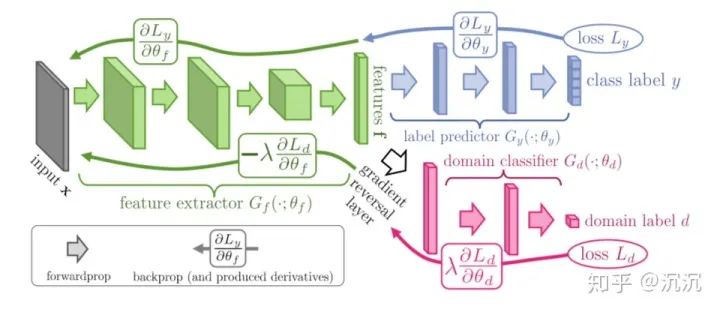
Brochu验证了Geirhos等人工作的有效性,并进一步使用域对抗训练的方法解决这一问题。
该方法通过域分类器(domain classifier)和梯度反向层(gradient reversal layer)实现对于不同域一致性特征的学习。
基于拼图的自监督学习

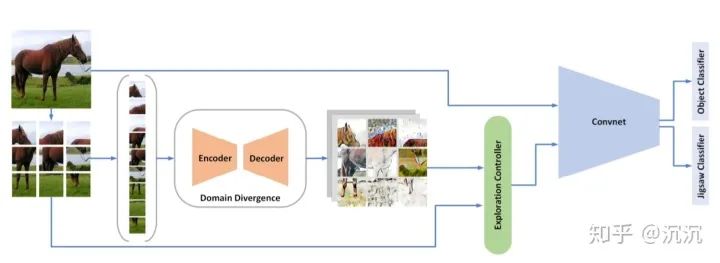
拼图(jigsaw)是一种常见的自监督学习方法。神经网络通过拼图正确顺序的监督信息学习如何恢复打乱的图像块,进而学习到图像特征,不需要任何图像类别的标识。
Asadi等人训练神经网络同时完成图像分类和风格化图像拼图两项任务,取得了准确度更高的结果。
应用场景
除了上面说的可以使提取的特征更加鲁棒、提升分类检测等任务的准确率之外,拥有形状偏好的预训练神经网络模型其实可以在非自然图像上有着很好的应用。漫画、手绘、平面设计作品一类的图像,由于其本身纹理信息不丰富、主要以形状来表征内容,因此使用有形状偏好的预训练神经网络可以帮助模型更好地收敛。当我们的研究工作中遇到对形状敏感的任务时,如果ImageNet预训练神经网络的效果不佳,不妨想想是不是它的纹理偏好在作怪~
参考资料
论文
ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness
Increasing Shape Bias in ImageNet-Trained Networks Using Transfer Learning and Domain-Adversarial Methods
Towards Shape Biased Unsupervised Representation Learning for Domain Generalization
开源工作
Stylized-ImageNet数据集、相关代码及预训练模型:https://github.com/rgeirhos/texture-vs-shape
推荐阅读
