
2022年,预训练何去何从?
©作者 | 李政
研究方向 | 自然语言处理
来源 | PaperWeekly

大规模预训练
如何解释预训练模型的理论基础(如大模型智能的参数规模极限存在吗) 如何将大模型高效、低成本的应用于实际系统 如何克服构建大模型的数据质量、训练效率、算力消耗、模型交付等诸多障碍 如何解决目前大部分大模型普遍缺乏认知能力的问题

对比学习
数据增强生成正例的变化有限 随机搭配成负例,含有除正例组合外其他组合全部为 0 的诱导 0,1 标签的赋予太过绝对,对相似性表述不够准确
score(X,X^{'}) >> score(X,Y)
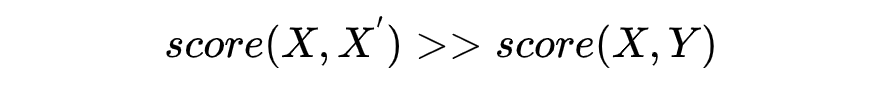
loss = -log \frac{exp(score(X,X^{'}))}{score(X,X^{'})+\sum_{i=1}^{N}score(X,Y_i)}
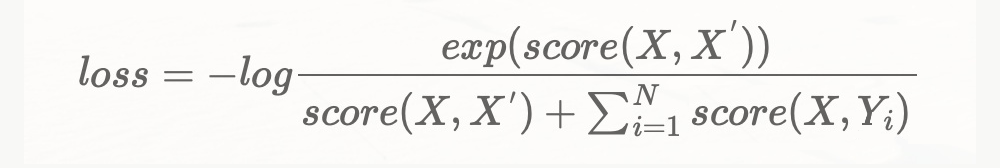

Prompt
x^{'}=f_{prompt}(x)

y = f(x^{'})
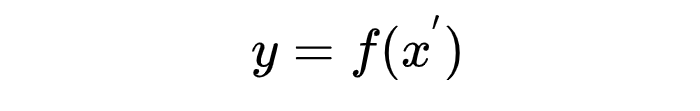

展望未来
太阳有几只眼睛?
姚明与奥尼尔身高谁比较高?
猫咪可以吃生蛋黄吗?猫咪是可以吃蛋黄的。这里特定煮熟的白水蛋,猫咪不能吃生鸡蛋,因为生鸡蛋中有细菌。
物质都是由分子构成的吗?物质都是由分子构成的,分子又由原子构成-错的!因为有些物质是不含分子的。
大模型一方面在不少问题上取得了以往难以预期的成功,另一方面其巨大的训练能耗和碳排放是不能忽视的问题。个人以为,大模型未来会在一些事关国计民生的重大任务上发挥作用,而在其他一些场景下或许会通过类似集成学习的手段来利用小模型,尤其是通过很少量训练来 “复用” 和集成已有的小模型来达到不错的性能。
我们提出了一个叫做 “学件” 的思路,目前在做一些这方面的探索。大致思想是,假设很多人已经做了模型并且乐意放到某个市场去共享,市场通过建立规约来组织和管理学件,以后的人再做新应用时,就可以不用从头收集数据训练模型,可以先利用规约去市场里找找看是否有比较接近需求的模型,然后拿回家用自己的数据稍微打磨就能用。这其中还有一些技术挑战需要解决,我们正在研究这个方向。
另一方面,有可能通过利用人类的常识和专业领域知识,使模型得以精简,这就要结合逻辑推理和机器学习。逻辑推理比较善于利用人类知识,机器学习比较善于利用数据事实,如何对两者进行有机结合一直是人工智能中的重大挑战问题。麻烦的是逻辑推理是严密的基于数理逻辑的 “从一般到特殊”的演绎过程,机器学习是不那么严密的概率近似正确的 “从特殊到一般”的归纳过程,在方法论上就非常不一样。已经有的探索大体上是以其中某一方为倚重,引入另一方的某些成分,我们最近在探索双方相对均衡互促利用的方式。

回顾自身算法经历
5.1 需求分析
业务属于什么样的任务
算法需要侧重的方向
训练数据及线上数据的情况
线上的指标
线下的评估方式
……
5.2 模型选型及设计
5.3 数据分析
数据是否存在噪声:标点、大小写、特殊符号等 训练集测试集分布是否存在差异,测试集能否反映模型在具体业务下的表现 数据存在哪些特征,通过引入额外的特征,模型可以表现地更好 训练集分布:标签分布、长度分布等,是否会给模型带来类别不均衡、长文本等问题 数据量大小,数据量足够时可以继续预训练
5.4 模型训练及优化
设置合适的超参数【可以通过一些超参数搜索算法】
选择合适的优化器【adam/adamw/sgd】
学习率调整的策略
对抗训练 对比学习 UDA等数据增强方式 继续预训练 多任务学习 伪标签 SWA ……
5.5 分析负例
5.5.1 检查数据质量是否过差
5.5.2 根据指标进行分析
recall低
召回率表示召回的数量,测试集数据未召回较多,则从下列角度检查数据:
训练集测试集数据差异是否较大,即训练集中是否存在类似数据,若不存在则引入更多数据或者对该数据进行数据增强。这种情况,常见原因为数据分布不均衡-少数数据训练不充分;训练集、测试集分布差异较大导致。 训练集中存在类似数据,检查训练集中该种情况有无标注错误:漏标、错标。
precision低
检查数据分布,是否数据分布不均衡。数据不均衡导致模型倾向于预测数量较多的数据,精确率下降。
标签定义是否准确,是否存在两类标签混淆的情况。这种情况,需要考虑对标签进行融合。
数据增强
resample
reweight
集成学习
交叉验证
置信学习
聚类分析