
【深度学习】一文探索“预训练”的奥秘!
作者:王奥迪,单位:中国移动云能力中心
2022年下半年开始,涌现出一大批“大模型”的优秀应用,其中比较出圈的当属AI作画与ChatGPT,刷爆了各类社交平台,其让人惊艳的效果,让AI以一个鲜明的姿态,站到了广大民众面前,让不懂AI的人也能直观地体会到AI的强大。
大模型即大规模预训练模型,本文就和大家聊一聊
预训练模型的起源与发展
。
1. 前言
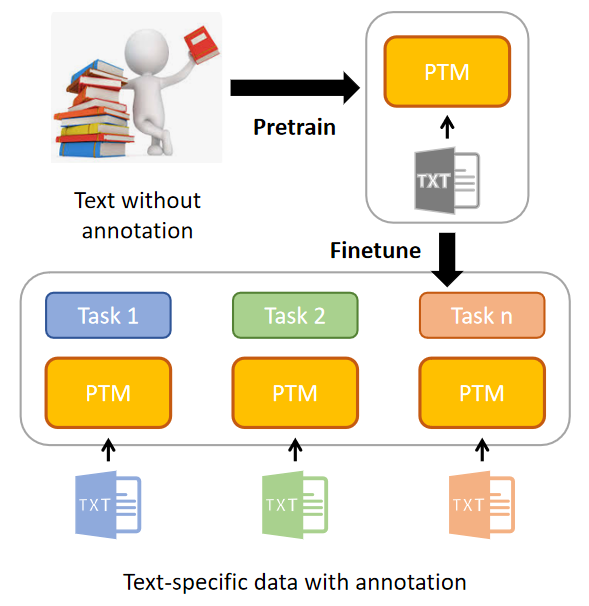
图1 NLP模型开发领域的标准范式“pretrain+finetune”
近年来,由于预训练模型(Pretrained Models, PTMs)的蓬勃发展,“预训练(pretrain)+微调(finetune)”成为了AI模型开发领域的标准范式。预训练模型的作用可想而知,它极大推进了AI的落地,让AI模型的开发从手工作坊模式走向工厂模式,快速适应AI市场的定制化需求。但它绝非一个空降神器,预训练的研究最早起源于迁移学习。迁移学习的核心思想,即运用已有的知识来学习新的知识,通俗来说就是将一个预训练的模型被重新用在另一个任务中。早期的预训练模型主要基于有标签数据,预训练模型的第一个浪潮发生在CV领域,得益于ImageNet[1]数据集中所富含的强大的视觉信息,其包含了上百万张上千种类别的图片,覆盖了日常生活中的各种物体,在ImageNet上预训练的模型(比如ResNet50)广泛应用于图像领域的各个下游任务,均取得了卓越的进展。而在NLP领域,由于下游任务的多样性以及数据标注的复杂性,导致无法获得一个像ImageNet这样大规模的有标签数据,所以NLP领域尝试使用自监督学习的方法来获取预训练模型,自监督学习的主要思想就是利用文本间的内在联系为监督信号。通过自我监督学习,可以利用大量未标记的文本数据来捕获通用的语言知识。早期NLP领域的NLP模型主要是词嵌入(word embedding)的研究,比如word2Vec[2],Glove[3]等,它们至今在各种NLP任务中仍发挥着重要的作用。2017年出现的Transformer结构[4],给NLP领域预训练模型的发展带来了绝大的突破。Transformer的成功,也诱使CV领域加入了自监督预训练模型的赛道。如今,自监督预训练已经成为当前人工智能研究的重点,几乎所有的最新的 PTM都是采用类Transformer结构与自监督学习的方法,接下来介绍比较有代表性的自监督预训练语言模型。
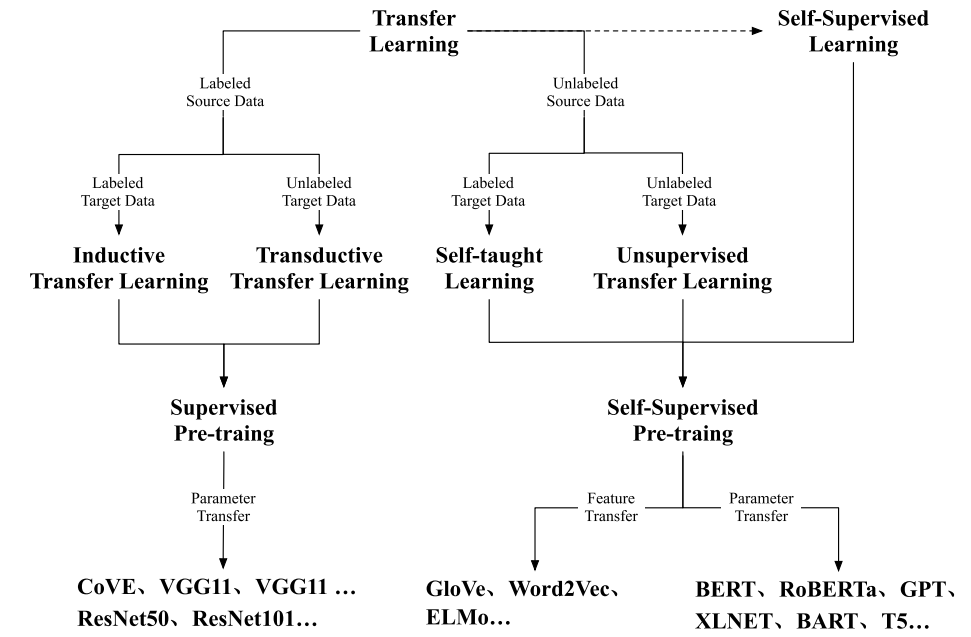
图2 预训练的起源与发展[5]
2. 模型结构
PTM成功的关键是自监督学习和Transformer。本节从占主导地位的神经架构 Transformer 开始。然后介绍两个具有里程碑意义的基于 Transformer 的 PTM,GPT[6]和BERT[7]。所有后续的PTMs基本都是这两个模型的变体。
2.1 Transformer
Transformer是一种序列到序列(seq2seq)架构,由编码器(encoder)和解码器(decoder)组成。说起Transformer,就不得不提它的注意力机制(Attention),对于注意力机制的原理解析可参考[5],这里主要总结下transformer中存在的三种注意力机制:
Self-attention:存在于encoder中的注意力层中,使用前一层的输出作为Q,K,V。给定一个词,自注意力计算其与输入序列中的所有单词的注意力得分,来表示其他单词对给定词汇特征表示的贡献程度。
Mask-attention:存在于decoder阶段,通过掩膜的手段,控制注意力得分的计算过程仅当前词汇左侧的词参与。因为decoder是一个从左到右逐词生成的过程。
Cross-attention:同样是存在于decoder阶段,使用前一层的输出作为Q,同时使用encoder的输出作为K,V。交叉注意力机制的主要作用在于生成词过程中能够利用其输入序列的信息,这在诸如机器翻译和文本摘要的seq2seq任务中尤为重要。
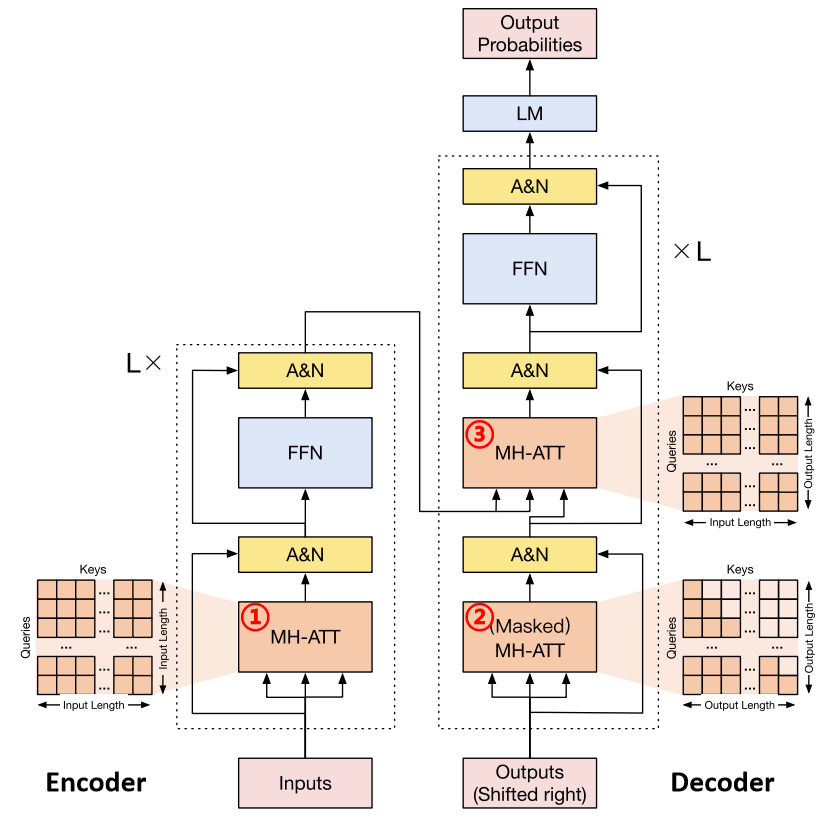
图3 Transformer网络结构示意图[5]
2.2 GPT
GPT是第一个在Transformer结构上应用自监督学习目标的PTM,它仅使用了Transformer的decoder作为基础结构,由于采用自监督学习,所以删去了cross-attention层。GPT是一个标准的自回归语言模型,它的学习目标,是根据上文预测下一个词,因此也往往更适合自然语言生成任务。
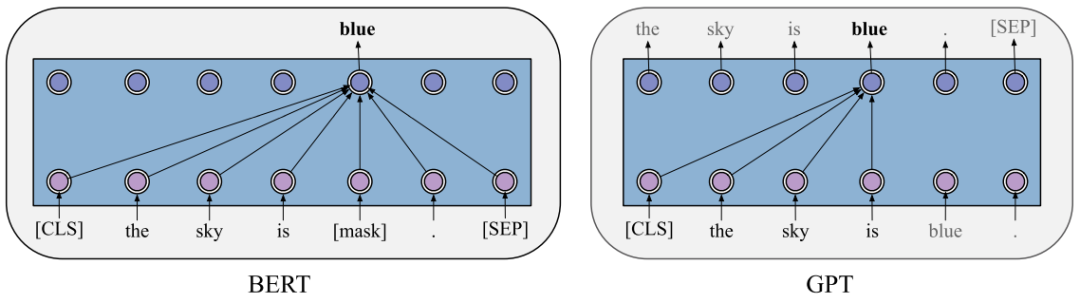
图4 BERT与GPT的区别[5]
2.3 BERT
BERT是基于双向 Transformer 结构构建,仅使用了Transformer的encoder结构。这里的双向主要是通过它的预训练目标实现的,BERT设计了一个 masked language modeling (MLM) 预训练任务,根据上下文来预测masked词汇。“双向”即体现在,在进行注意力计算时,BERT会同时考虑被遮蔽词左右的词对其的影响。BERT是一种自编码语言模型,更适合自然语言理解任务。
2.4 后起之秀
在GPT和BERT之后,出现了很多基于它们的变体,图5中罗列了目前预训练模型家族的主要成员。一部分工作致力于改进模型架构并探索新的预训练任务;一部分工作致力于探索数据的丰富性,比如多语言和多模态PTMs;还有一部分工作致力于探索更多参数的模型以及PTM计算效率的优化。
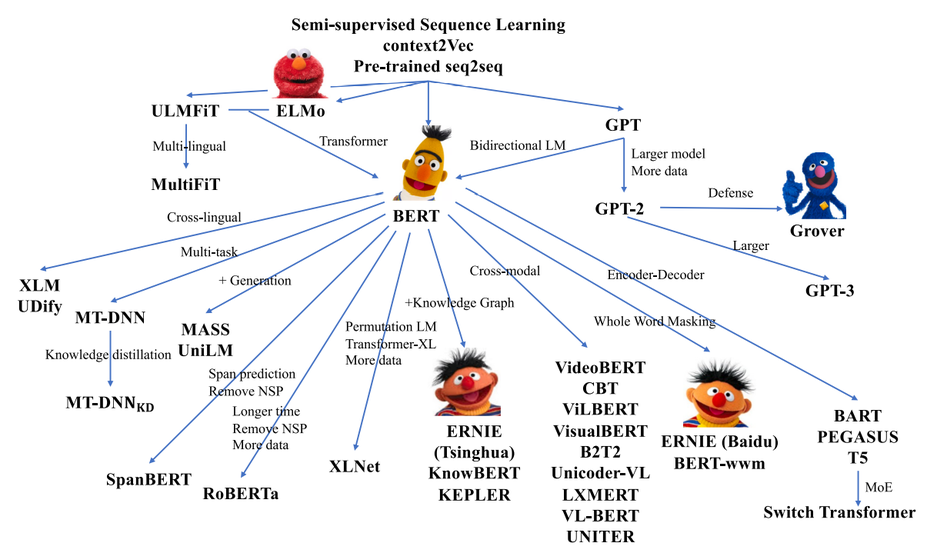
图5 预训练模型家族[5]
3. 预训练任务
预训练模型的主要目标是如何利用未标注语料来获取通用知识,以便快速迁移到各种下游任务中。预训练任务即学习目标的设计至关重要。前文也提到了GPT和BERT的预训练任务Autoregressive language modeling和masked language modeling,它们也分别是自回归语言模型和自编码语言模型无法替代的预训练任务,后续的一些PTMs中探索的新的预训练任务均是在此基础上追加的。下表中总结了目前一些常见的预训练任务。对于单资源数据输入(单语言纯文本),往往从挖掘文本间词汇、句子、篇章的内在联系设计新的预训练任务;对于多资源数据输入,比如多语言和多模态的预训练模型,往往会从如何构建不同语言和不同模态的统一的特征表示来考虑设计新的预训练任务。
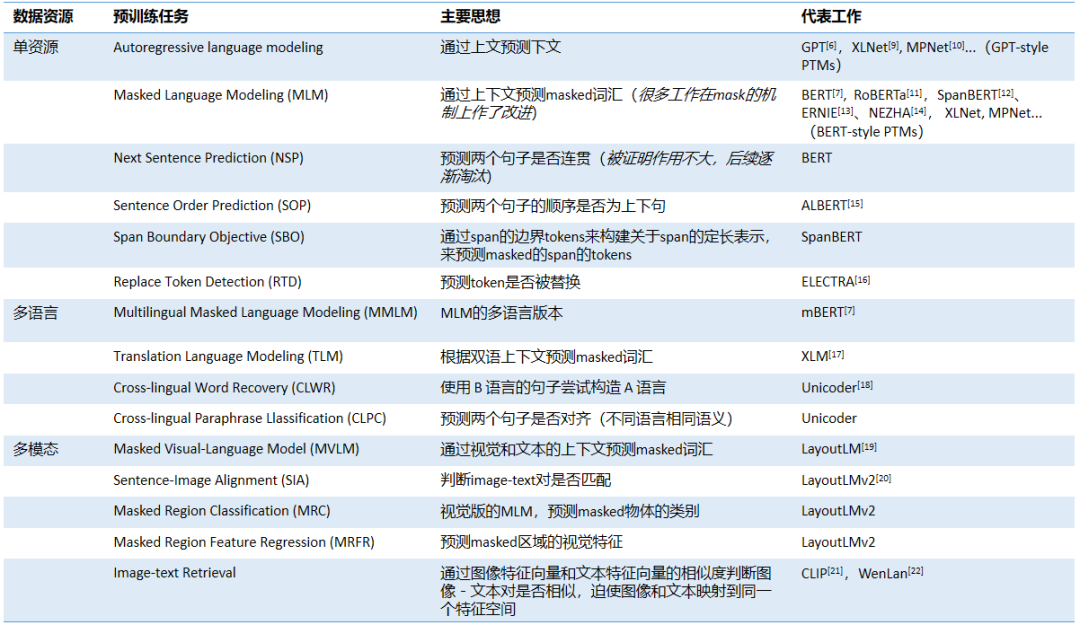
4. 总结
本文整体介绍了预训练模型起源与发展,文章大部分内容来自于论文[5],在此基础上做了一些总结和梳理,感兴趣的可以去阅读原文。预训练模型的发展无疑推进了AI的落地。近年来,随着神经网络结构设计技术逐渐成熟并趋于收敛,以及数据和模型参数规模的不断增大,行业内也掀起了“炼大模型”的热潮,致力于打造AI领域的基石模型。而对于预训练模型的应用,除了“pretrain+finetune”,逐渐盛行了一种新的范式“pretrain+prompt+predict",致力于重构不同的下游任务,打造大一统的多任务模型。归根结底,大家其实都是在解决同一个问题:”如何快速有效地进行AI模型开发“,这也是AI领域一直以来研究的重要课题。
5. 参考文献
[1] Deng J, Dong W, Socher R, et al. Imagenet: A large-scale hierarchical image database[C]//2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009: 248-255.
[2] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013.
[3] Pennington J, Socher R, Manning C D. Glove: Global vectors for word representation[C]//Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014: 1532-1543.
[4] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[5] Han, Xu, et al. "Pre-trained models: Past, present and future." AI Open 2 (2021): 225-250.
[6] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018.
[7] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[8] https://jalammar.github.io/illustrated-transformer/
[9] Yang Z, Dai Z, Yang Y, et al. Xlnet: Generalized autoregressive pretraining for language understanding[J]. Advances in neural information processing systems, 2019, 32.
[10] Song K, Tan X, Qin T, et al. Mpnet: Masked and permuted pre-training for language understanding[J]. Advances in Neural Information Processing Systems, 2020, 33: 16857-16867.
[11] Liu Y, Ott M, Goyal N, et al. Roberta: A robustly optimized bert pretraining approach[J]. arXiv preprint arXiv:1907.11692, 2019.
[12] Joshi M, Chen D, Liu Y, et al. Spanbert: Improving pre-training by representing and predicting spans[J]. Transactions of the Association for Computational Linguistics, 2020, 8: 64-77.
[13] Sun Y, Wang S, Li Y, et al. Ernie: Enhanced representation through knowledge integration[J]. arXiv preprint arXiv:1904.09223, 2019.
[14] Wei J, Ren X, Li X, et al. Nezha: Neural contextualized representation for chinese language understanding[J]. arXiv preprint arXiv:1909.00204, 2019.
[15] Lan Z, Chen M, Goodman S, et al. Albert: A lite bert for self-supervised learning of language representations[J]. arXiv preprint arXiv:1909.11942, 2019.
[16] Clark K, Luong M T, Le Q V, et al. Electra: Pre-training text encoders as discriminators rather than generators[J]. arXiv preprint arXiv:2003.10555, 2020.
[17] Lample G, Conneau A. Cross-lingual language model pretraining[J]. arXiv preprint arXiv:1901.07291, 2019.
[18] Huang H, Liang Y, Duan N, et al. Unicoder: A universal language encoder by pre-training with multiple cross-lingual tasks[J]. arXiv preprint arXiv:1909.00964, 2019.
[19] Xu Y, Li M, Cui L, et al. Layoutlm: Pre-training of text and layout for document image understanding[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 1192-1200.
[20] Xu Y, Xu Y, Lv T, et al. LayoutLMv2: Multi-modal pre-training for visually-rich document understanding[J]. arXiv preprint arXiv:2012.14740, 2020.
[21] Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision[C]//International Conference on Machine Learning. PMLR, 2021: 8748-8763.
[22] Huo Y, Zhang M, Liu G, et al. WenLan: Bridging vision and language by large-scale multi-modal pre-training[J]. arXiv preprint arXiv:2103.06561, 2021.
往期
精彩
回顾
适合初学者入门人工智能的路线及资料下载
(图文+视频)机器学习入门系列下载
机器学习及深度学习笔记等资料打印
《统计学习方法》的代码复现专辑
机器学习交流qq群955171419,加入微信群请
扫码