
全面综述:基于3D骨架的深度学习行为识别方法

极市导读
本文对首篇基于3D骨架数据的深度学习行为识别方法的综述论文进行了论文翻译和要点总结,对基于RNN、CNN和GCN的主流行为识别技术进行了全面的介绍,同时介绍了最大的3D骨架数据集及相关算法。>>>极市七夕粉丝福利活动:炼丹师们,七夕这道算法题,你会解吗?
本文是对论文《A Survey on 3D Skeleton-Based Action Recognition Using Learning Method》学习时所做的记录和总结。
论文链接:https://arxiv.org/pdf/2002.05907.pdf
发布时间:2020.2.14
作者团队:北大&腾讯研究院
分类:计算机视觉-行为识别-基于3D骨架的行为识别-综述
本文目录:
一、论文翻译
二、论文总结
一、论文翻译
Abstract
由于关键点(骨架)检测的潜在优势,基于3D骨架的行为识别已经成为计算机视觉中的活跃主题,因此多年来学者们提出了许多优秀的方法,这些方法有的使用传统手工特征,有的使用学习到的特征。
然而,之前的行为识别综述大多数集中于调研以视频或者RGB数据为输入的方法,关于骨架数据为输入的方法调研的很少,一般都是直接说一下骨架数据的表示或某些经典技术在特定数据集上的表现;此外,尽管深度学习方法已经在这个领域应用多年,但是仍然没有相关的研究来从深度学习结构的角度对其进行介绍或总结。
为了打破这些限制,本综述首先强调了行为识别的必要性和3D骨架数据的重要性;然后以数据驱动的方式对基于RNN、CNN和GCN的主流行为识别技术进行了全面的介绍;最后,我们简要介绍了一下最大的3D骨架数据集NTU-RGB+D及其最新版本NTU-RGB+D 120,并展示了这两个数据集中包含的几种现有的顶级算法。
据我们所知,本文是首次全面讨论基于3D骨架数据的深度学习行为识别方法的综述。
1、Introduction
行为识别(Action Recognition)是计算机视觉中极其重要也非常活跃的研究方向,它已经被研究了数十年。因为人们可以用动作(行为)来处理事情、表达感情,因此行为识别有非常广泛但又未被充分解决的应用领域,例如智能监控系统、人机交互、虚拟现实、机器人[1-5]等。以往的方法中都使用RGB图像序列[6-8],深度图像序列[9,10],视频或者这些模态的特定融合(例如RGB+光流)[11-15],也取得了超出预期的结果。然而,和骨架数据(人体关节和骨头的一种拓扑表示)相比,前述模态会产生更多的计算消耗,且在面对复杂背景以及人体尺度变化、视角变化和运动速度变化[16]时鲁棒性不足。此外,像Microsoft Kinect这样的传感器[17]和一些先进的人体姿态估计算法[18-20]都可以让我们更轻松地获得准确的3D骨架(关键点)数据[21]。图1展示了人体骨架数据的可视化效果。
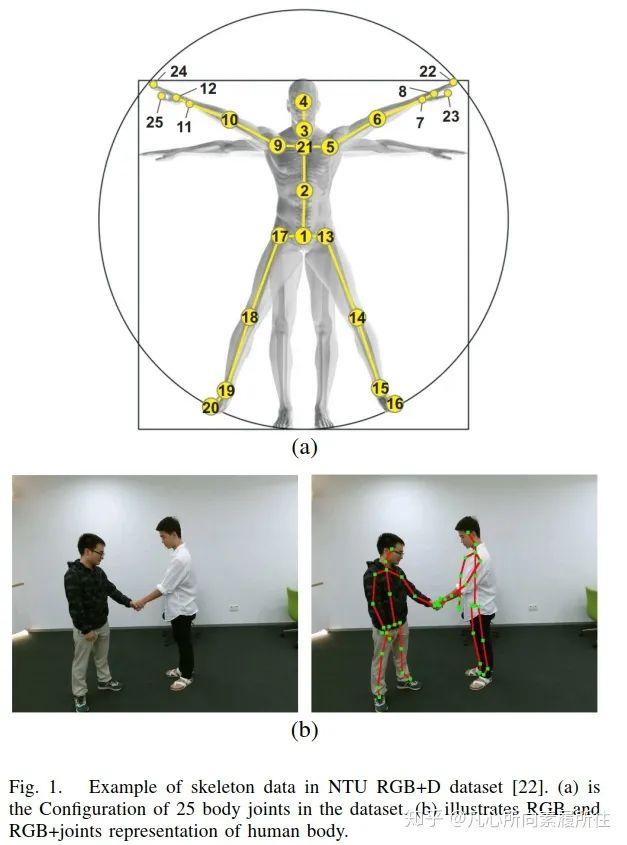
图1. NTU RGB+D数据集[22]的一个示例.(a)数据集中的25个身体关节(b)人体RGB和RGB+关节展示
除了与其他模态数据相比具有的优势,骨架序列还有如下三个主要的特点:
i)空间信息Spatial information,相邻关节之间存在很强的相关性,因此帧内(intra-frame)可以获取丰富的人体结构信息。
ii)时域信息Temporal information,帧间inter-frame可以利用时域相关信息。
iii)时空域贡献关系Co-occurrence relationship,当考虑关节和骨骼的时候。
因此,许多研究人员使用骨架数据来做人体行为识别或检测,且一定会有越来越多的研究会使用骨架数据。
基于骨架序列的行为上和别主要是一个时序问题temporal problem,因此传统的基于骨架的方法通常都是从特定的骨架序列中提取运动模式,这引出了许多手工特征的研究,这些手工特征经常会利用不同关节间的相对3D旋转和平移。然而,文献[27]认为这些手工特征只在一些特定数据集上表现良好,这进一步说明了从一个数据集上提取的手工特征可能无法迁移到其他数据集上,这使得行为识别算法难以推广或应用到更广泛的应用领域。
随着深度学习方法在其他在其他计算机视觉任务上的发展和先进表现,使用骨架数据的RNN[29],CNN[30]和GCN[31]也开始出现。图2展示了基于3D骨架的深度学习行为识别方法的通用pipeline(从原始的RGB序列或者视频到最后的行为类别)。
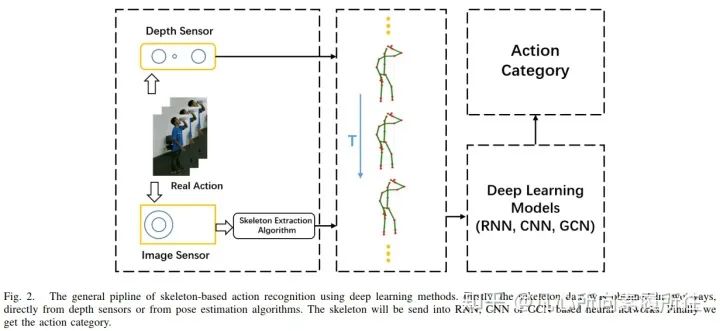
图2. 基于骨架的深度学习行为识别方法的通用pipeline.首先,直接从深度传感器或者姿态估计算法获取骨架数据;然后将骨架数据输入到RNN,CNN,GCN等神经网络;最后得到行为类别。
在基于RNN的方法中,骨架序列是关节坐标的自然时间序列,这可以被视为序列向量,而RNN本身就适合于处理时间序列数据。此外,为了进一步改善学习到的关节序列的时序上下文信息,一些别的RNN(LSTM,GRU)方法也被用到骨架行为识别中。
当使用CNN来处理这一基于骨架的任务的时候,可以将其视为基于RNN方法的补充,因为CNN结构能更好地捕获输入数据的空间cues,而基于RNN的方法正缺乏空间信息的构建。
最后,相对新的方法图卷积神经网络GCN也有用于骨架数据处理中,因为骨架数据本身就是一个自然的拓扑图数据结构(关节点和骨头可以被视为图的节点和边),而不是图像或序列那样的格式。
上述三种基于深度学习的方法都获得了空前的表现,但是大多数review文献只是专注于传统方法或者是基于RGB-(D)数据的深度学习方法(作者的意思就是说别的综述在总结深度学习行为识别方法的时候都是专注于以RGB或者RGBD数据为输入的那些方法,而本文是专注于将骨架数据作为输入的那些深度学习行为识别方法)。
Ronald Poppe[32]首先解决了该领域的基本挑战,然后详细介绍了关于直接分类和时间状态空间模型的基本行为分类方法;Daniel和Remi[33]展示了行为表示在空间和时间域上的整体概况;这两篇文章为输入数据的预处理提供了一些启发,但是既没有考虑骨架序列数据也没有考虑深度学习策略。
最近,[34,35]总结了基于深度学习的视频分类和看图说话任务,并在文中介绍了CNN和RNN的基本结构,其中[35]对常见的用于行为识别的深度结构和定量分析进行了分析。据我们所知,[36]是最近的第一篇深入研究3D骨架行为识别的文献,它总结了行为表示和分类方法,同时提供了一些常用的数据集,例如UCF,MHAD,MSR daily activity 3D[37-39]等,但是它没有涵盖到最新兴起的基于GCN的方法。
最后,文献[27]基于Kinect数据集写了个行为识别算法综述,该综述对那些使用了该数据集的算法进行了全面的比较,数据的类型包括RGB,Depth,RGB-D和skeleton sequences。
然而,上述所有工作都忽略了CNN-Based、RNN-Based、GCN-Based方法之间的区别和动机,尤其是将3D骨架序列考虑在内的时候。
为了解决这些问题,我们基于骨架数据,使用三种基本的深度学习结构(RNN,CNN,GCN),对行为识别进行了全面总结,并进一步地阐释了这些模型的动机和未来研究方向。
总的来说,我们的研究包含4个主要贡献:
i)以详细且简明的方式全面介绍了3D骨架序列数据的优越性和三种深度学习模型的特点,并举例说明了使用3D骨架数据的基于深度学习方法的行为识别pipeline。
ii)对每种深度模型,从数据驱动的角度介绍了基于骨架数据的最新算法,例如时空建模、骨架数据表示、共现特征学习等方面,这些部分也是现存的待解决的经典问题。
iii)首先讨论最新的具有挑战的数据集NTU-RGB+D 120及其附带的几种top-rank方法,然后讨论未来的研究方向。
iv)我们是首个 “在基于3D骨架数据的行为识别研究中考虑了各种深度模型(RNN CNN GCN)”的综述。
2、3D Skeleton-Based Action Recognition with Deep Learning
现有的surveys已经从基于RGB或基于骨架的角度对现有的行为识别技术进行了定量和定性比较,但是没有从神经网络的角度来比较。为此,我们分别对基于RNN的,基于CNN的,基于GCN方法进行详尽的讨论和比较。对于每个部分,将基于某些缺陷(例如这三种模型之一的缺陷或者经典的时空建模问题的缺陷)来引入一些最新的相关工作作为案例。
(1)RNN based Methods
RNN[40]通过将上一时刻的输出作为当前时刻的输入来形成其结构内部的递归连接,这被证明是一种处理序列数据的有效方法。为了弥补标准RNN的不足(例如梯度消失问题和长时建模问题),LSTM和GRU分别在RNN内部引入了门和线性记忆单元,改进了模型性能。
第一方面,时空建模算是行为识别任务的首要原则,由于RNN结构缺乏空间建模能力,相关的方法通常也无法取得竞争性的结果[41-43]。最近,Hong和Liang[44]提出了一个新颖的双流RNN结构来为骨架数据建模时域和空域特征,其中骨架轴的交换作为数据预处理来更好地学习空间域特征,该工作的框架如下图3所示。
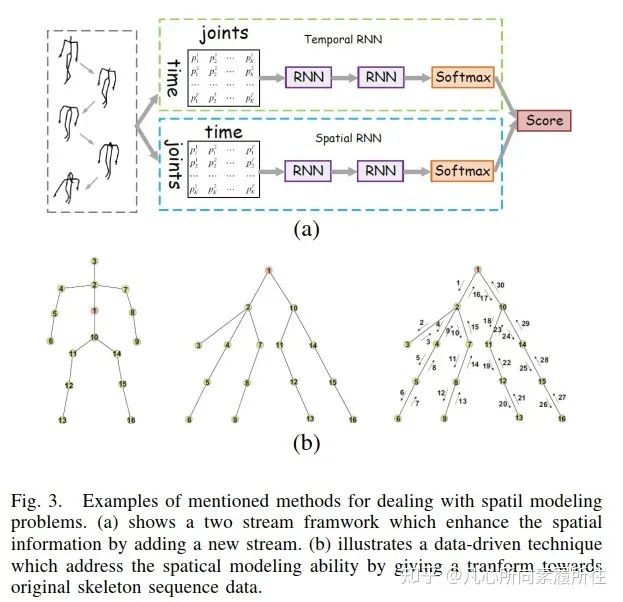
图3. RNN-based Methods中提出的解决空间建模问题的示例[44].(a)在RNN的基础上增加了一个新的stream来增强空间信息.(b)一种数据驱动的技术(对原始骨架序列数据进行转换)来解决空间建模能力问题
和[44]不同的是,Jun和Amir[45]对骨架序列的遍历方法进行了研究,以此来获取时空域的隐藏关系。一般的方法将将关节排列成简单的链,这忽略了相邻关节的运动依赖关系,而[45]提出了基于树结构的关节遍历方法,该方法在人体关节的联系不够牢固时也不会添加虚假连接。然后使用带有信任门trust gate的LSTM来区分输入,即如果树状输入单元是可靠的,则将使用输入的潜在空间信息来更新记忆单元。
受CNN适合建模空间信息这一特性的启发,Chunyu和Baochang[46]使用注意力RNN和CNN模型来改善复杂的时空建模。首先在残差学习模块中使用时域注意力子模型,来重新校准骨架序列中的时域注意力,然后后接时空卷积子模型(将上一子模型输出的校准后的关节序列视为图像)。
此外,[47]使用一个注意力循环关系LSTM网络来学习骨架序列中的时空特征,其中循环关系网络recurrent relation network学习空间特征、多层LSTM学习时域特征。
第二方面,网络结构也算是RNN的固有缺点。尽管RNN的性质决定了其适合处理序列数据, 但众所周知的是梯度爆炸和消失问题不可避免。LSTM和GRU可以在一定程度上缓解这一问题,但tanh和sigmoid激活函数可能还是会导致层间的梯度衰减。为了解决这一缺陷,一些新型的RNN结构被提出[48-50],Shuai和Wanqing[50]提出了一个独立的循环神经网络,该网络可以解决梯度爆炸和消失问题,这使得构建一个更长更深的RNN网络来学习鲁棒性更好的高级语义特征成为可能。这一改进的RNN不仅可以用于骨架行为识别,也可用用于其他领域例如语言模型。在这种结构中,一层内的神经元彼此独立,因此可以用于处理更长的序列。
最后一个方面,即第三个方面,数据驱动方面。考虑到并不是所有的关节对行为分析有用,[51]在LSTM网络中添加了全局意识关注global contex-aware attention来选择性地关注骨架序列中信息丰富的关节。图4(a)展示了该方法的可视化效果,从中我们可以发现信息量更大的关节用红色圆圈表示,表示这些关节对该特定的行为更重要。
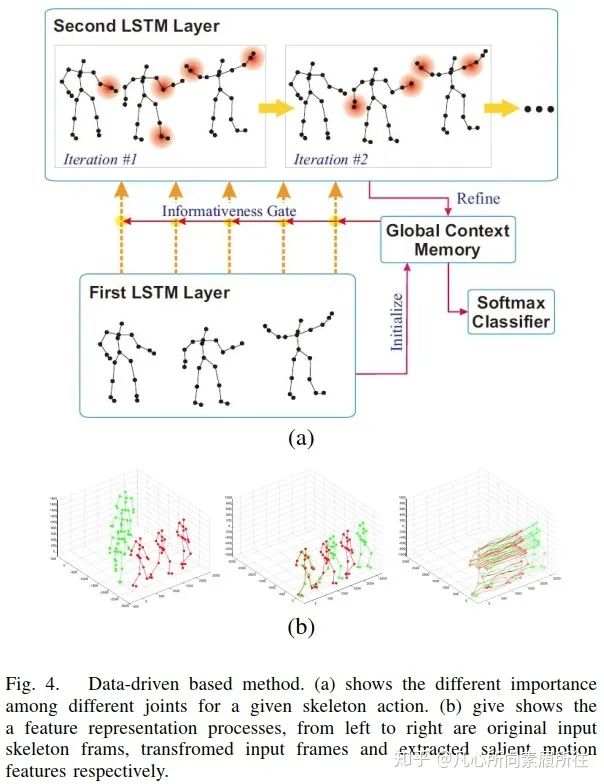
图4. 基于数据驱动的方法.(a)对于给定的骨架动作,不同关节的重要性不同[51];(b)特征表示过程,从左至右分别是原始输入的骨架帧、转换后的输入帧和提取到的显著运动特征[52]
另外,由于数据集或深度传感器所提供的骨架并不是完美的,这可能会影响行为识别任务的结果,所以[52]将骨架转换为另一种坐标系统来提升尺度变化、旋转、平移的鲁棒性,然后从转换后的数据中提取显著运动特征,而不是直接将原始骨架数据输入到LSTM中,图4(b)展示了这一特征表示过程。
除了上述这些,还有很多有价值的使用RNN的方法着眼于大视角变化、单个骨架中各关节的关系等问题。然而,我们必须承认在特定的建模方面RNN-based的方法确实比CNN based方法弱,接下来讨论另一个有趣的问题:CNN-based方法如果进行时域信息建模以及如何找到时空信息的相对平衡点。
(2)CNN based Methods
卷积神经网络也被用于基于骨架的行为识别。和RNN不同的是,CNN凭借其自然、出色的高级信息提取能力可以有效且轻松地学习高级语义cues。不过CNN通常专注于image-based任务,而基于骨架序列的行为识别任务毫无疑问是一个强时间依赖的问题。所以在基于CNN的架构中,如何平衡且更充分地利用空间信息和时域信息就非常有挑战了。
为了满足CNN输入的需要,3D骨架序列数据通常要从向量序列转换为伪图像,然而,要同时具有时空信息的相关表示pertinent representation并不容易,因此许多研究者将骨架关节编码为多个2D伪图像,然后将其输入到CNN中来学习有用的特征[53,54]。
Wang[55]提出了关联轨迹图(Joint Trajectory Maps, JTM),它通过颜色编码将关节轨迹的空间配置和动态信息spatial configuration and dynamics of joint trajectories表示为三个纹理图像。然而,这种方法有点复杂,且在映射过程中丢失了重要信息。为了克服这一缺陷,Bo和Mingyi[56]使用平移不变的图像映射策略,先根据人体物体结构把每帧图像的人体骨架关节分为五个主要部分,然后把这些部分映射为2D形式。这种方法是的骨架图像同时包含了时域信息和空间信息。然而,虽然性能得到改善,但是将人体骨架关节作为孤立的点是不合理的,因为在真是世界中整个身体的各个部分都会存在紧密的联系。例如当我们挥手的时候,不仅仅要考虑和手直接相关的关节,还要考虑其他部分的情况,例如肩膀和腿也需要被考虑。
Yanshan和Rongjie[57]从几何代数中提出了形状运动表示法shape-motion representaion,解决了关节和骨骼的重要性,充分利用了骨架序列所提供的信息,如图5(a)所示。
类似的,[2]也使用了增强的骨架可视化来表示骨架数据,Carlos和Jessica[58]基于运动信息提出新的表示方法(命名为SkeleMotion),该方法通过显式计算关节运动的幅度和方向值来编码时间动态信息,如图5(b)所示。
此外,和SkeleMotion类似,[59]使用SkeleMotion的框架但是基于树结构和参考关节来表示骨架图像。
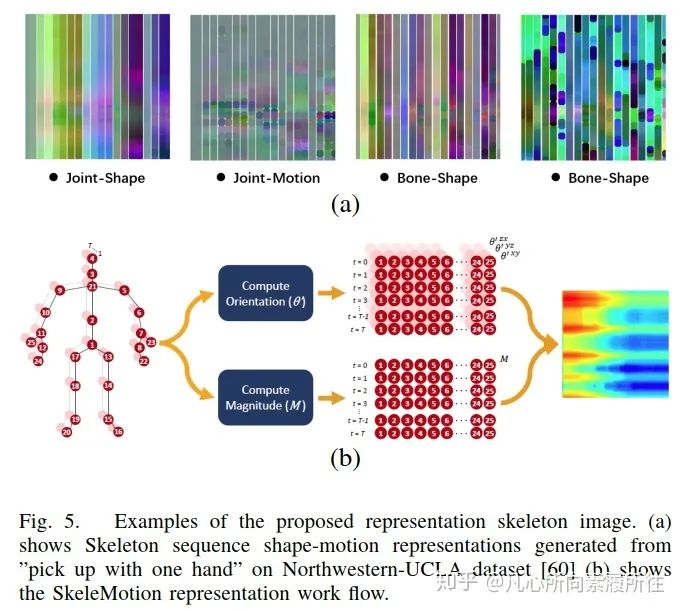
图5. 骨架图像表示方法展示.(a)Northwestern-UCLA数据集[60]上“单手俯卧撑”动作的shape-motion表示[57];(b)SkeleMotion表示的工作流程[58].
这些CNN-based方法通常把时域动态和关节简单地编码为行和列,来将骨架序列表示为图像,因此卷积的时候仅考虑了卷积核内的相邻关节来学习共现特征,也就是说,对每个关节来说,一些潜在相关的关节会被忽略,因此CNN不能学习到相应的有用的特征。Chao和Qiaoyong[61]使用一个端到端的框架通过分层方法来学习共现特征,在该框架中逐步汇总不同层级的上下文信息。首先对点级point-level信息进行独立编码,然后在时域和空域将它们组合成语义表示。
在CNN-Based的技术中,除了3D骨架序列表示之外也有一些别的问题,例如模型的大小和速度[3],CNN的架构(双流或者单流[62]),遮挡,视角变化等等[2,3]。所以使用CNN来解决基于骨架的行为识别任务仍是一个开放的问题,需要研究人员进行深入研究。
(3)GCN based Methods
人类3D骨架数据是自然的拓扑图,而不是一系列向量(RNN-based方法中的思路)或是伪图像(CNN-based方法中的思路),因此GCN(能够有效表示图形结构数据)最近被频繁地用到骨架行为识别任务中。目前现存的两种与图相关的神经网络有图循环神经网络GNN和图卷积神经网络GCN,本综述主要关注GCN,同时我们也会展示一些相关的先进结果。而且仅从骨架的角度来看的话,把骨架序列简单地编码为序列向量或2D网格并不能完全表达相关关节的依赖关系。图卷积神经网络Graph convolutional neural networks作为CNN的一种泛化形式,可以应用于骨架图在内的任意结构。在基于GCN的骨架行为识别技术中,最重要的问题是如何把原始数据组织称特定的图结构(还是和骨架数据的表达相关)。
Sijie和Yuanjun[31]首次提出了一种基于骨架动作识别的新模型--时空图卷积网络ST-GCN,该网络首先将人的关节作为时空图的顶点vertexs,将人体连通性和时间作为图的边edges;然后使用标准Softmax分类器来讲ST-GCN上获取的高级特征图划分为对应的类别。这项工作让更多人关注到使用GCN进行骨架行为识别的优越性,因此最近出现了许多相关工作。
最常见的研究集中于对骨架数据的有效使用[68,78],Maose和Siheng[68]提出的运动结构图卷积网络(Action Structural Graph Convolutional Network, AS-GCN)不仅能够识别人的动作,还可以使用多任务学习策略来输出目标下一个可能的姿态pose。这项工作中构造的图结构可以通过两个子模块Actional Links和Structual Links来捕获关节间更丰富的依赖性。图6展示了AS-GCN的特征学习过程和其广义骨架图结构,该模型中使用的多任务学习策略可能是一个很不错的方向,因为行为识别任务可能会从其他补充任务中得到提升。
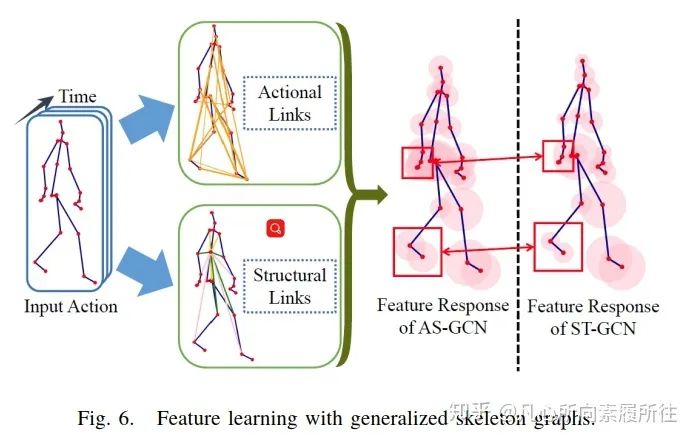
图6.广义骨架图的特征学习
根据上述介绍和讨论,最受关注的地方仍然是数据驱动的,我们要做的就是获取3D骨架序列数据背后的潜在信息,而GCN-based行为识别主要围绕着“如何获取”这一问题展开,这仍然是一个开放的具有挑战的问题。尤其骨架数据本身就是时空耦合的,此外将骨架数据转换为图时,关节和骨骼之间的连接也是时空耦合的。
3、Latest Datasets and Performance
骨架序列数据集主要有MSRAAction3D[79],3D Action Pairs[80],MSR Daily Activity3D[39]等,这些数据都在许多综述中有过分析[27,35,36],所以我们这里主要分析如下两个数据集NTU-RGB+D[22]和NTU-RGB+D 120[81]。
NTU-RGB+D数据集在2016年提出,包含56880个视频samples,这些样本都是从一个大规模骨架行为识别数据集Microsoft Kinect v2上收集的,NTU-RGB+D像图1(a)那样提供了每个人、每个动作的25个关节的3D空间坐标。在该数据集上,建议使用两种协议对提出的方法进行评估:跨子类Cross-Subject和跨视角Cross-View。其中Cross-Subject包含40320个训练样本和16560个验证样本,划分规则是根据40个subjects进行的;其中Cross-View将camera2和3作为训练集(37920个样本),将camera1作为验证集(18960个样本)。
近来,提出了NTU-RGB+D的扩展版本NTU-RGB+D 120,包含120个动作类别和114480个骨架序列,视角点是155个。我们将在表I中展示最近相关的骨架行为识别性能,其中CS表示Cross-Subject,CV在NTU-RGB+D表示Cross-View,在NTU-RGB+D 120表示Cross-Setting。
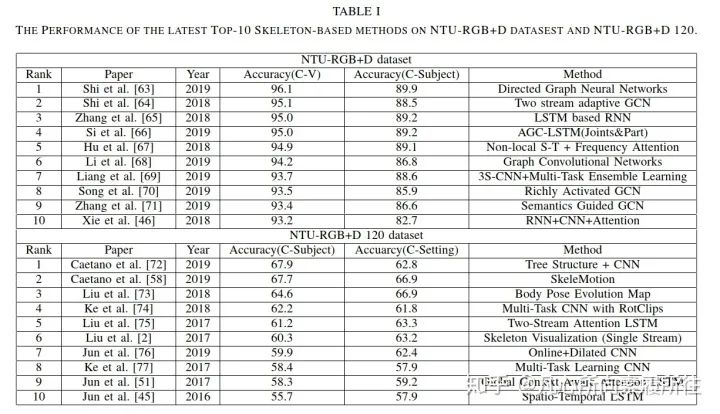
表1. 最新Top10骨架行为识别算法在NTU-RGB+D和NTU-RGB+D 120数据集上的性能
从表中可以看到现存的算法已经在NTU-RGB+D数据集上取得了极好的性能,在NTU-RGB+D 120数据集上仍然还有很大进步空间。
4、Conclusions and Discussion
本文分别基于三种主要的神经网络结构介绍了3D骨架序列数据上的行为识别问题,在介绍中我们强调了行为识别的含义、骨架数据的优越性和不同深度框架的特性。
与之前的综述数不同,我们的研究以数据驱动的方式深入了解了基于深度学习的行为识别方法,涵盖了基于CNN、RNN、GCN的最新行为识别算法。其中RNN-Based和CNN-Based方法通过骨架数据表示和详细的网络结构设计来解决时空特征问题,在GCN-based方法中,最重要的事情是如何充分利用关节和骨骼的信息和联系。据此,我们得出结论:在三种不同的学习结构中最常见的仍然是从3D骨架中获取有效信息,而拓扑图是人类骨架关节最自然的表示,这一点从各算法在NTU-RGB+D上的性能表现也可以看出来。然而, 这并不意味着CNN-based和RNN-based方法就不适合骨架行为识别任务,相反的,当在这些模型上应用一些策略(例如多任务学习)时,CV和CS性能都会得到提升。然而,在NTU-RGB+D上的精度已经很高了,很难去进一步提升,所以注意力应该放到更难的数据集上,例如NTU-RGB+D 120。
至于未来方向,长期行为识别、更有效的3D骨架序列表示、实时识别等都是待解决的问题,此外无监督和弱监督策略以及zero-show学习也可能会得到发展。
Peferences
二.论文总结
综述文章,也没什么好总结的,就用自己的话简单总结一下这篇文章到底在review什么。
1.首先这篇综述的主题是 3D Skeleton + Deeplearning + ActionRecognition
(1)深度学习不用说了,一般来说肯定比手工方法优越
(2)至于3D Skeleton, 作者就开篇先论证了一下3D Skeleton 数据的优越性(相比RGB RGB-D)
(3)作者给了个这个主题的基本pipeline
作者的意思就是说:我写这个主题算是新颖的、有意义的。
2.以数据驱动的方式对RNN-Based、CNN-Based、GCN-Based骨架行为识别方法进行了总结
(1)所谓数据驱动方式:讨论的核心都是这三种结构都是如何从3D骨架序列数据中构建、获取时空信息的。
(2)在总结这三类方法时都是以网络结构本身的缺陷为着手点,引出各种相关方法的。最后就想说,RNN-Based和CNN-Based方法各有优缺点,但明显GCN更能自然地描述3D骨架数据。
3.列举了一下以前综述中讨论过的3D骨架行为识别数据集,然后着重描述了一下NTU-RGB+D和其扩展版NTU-RGB+D 120两个数据集,给出最近top10算法在这两个数据集上的表现。
本篇综述的翻译和总结至此结束,欢迎讨论~
推荐阅读
two/one-stage,anchor-based/free目标检测发展及总结:一文了解目标检测:https://zhuanlan.zhihu.com/p/100823629
人体关键点检测(姿态估计)简介+分类汇总:https://zhuanlan.zhihu.com/p/102457223
一文了解通用行为识别ActionRecognition:了解及分类:https://zhuanlan.zhihu.com/p/103566134
