
基于改进级联R-CNN的面料疵点检测方法
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
文章编号 | 1009-265X(2022)02-0048-09
来源 | 《现代纺织技术》2022年第30卷,第2期,
作者 | 许胜宝1a,郑飂默2,3,袁德成1b
( 1.沈阳化工大学, a.计算机科学与技术学院; b.信息工程学院,沈阳 ;2.中国科学院沈阳计算技术研究所,沈阳 ;3.沈阳中科数控技术股份有限公司,沈阳 )
作者简介 | 许胜宝(1993-),男,辽宁丹东人,硕士研究生,主要从事计算机视觉方面的研究。
摘要 由于布匹疵点种类分布不均,部分疵点具有极端的宽高比,而且小目标较多,导致检测难度大,因此提出一种改进级联R-CNN的布匹疵点检测方法。针对小目标问题,在R-CNN部分采用在线难例挖掘,加强对小目标的训练;针对布匹疵点极端的长宽比,在特征提取网络中采用了可变形卷积v2来代替传统的正方形卷积,并结合布匹特征重新设计边界框比例。最后采用完全交并比损失作为边界框回归损失,获取更精确的目标边界框。结果表明:对比改进前的模型,改进后的模型预测边界框更加精确,对小目标的疵点检测效果更好,在准确率上提升了3.57%,平均精确度均值提升了6.45%,可以更好地满足面料疵点的检测需求。
关键词 级联R-CNN;面料疵点;检测;可变形卷积v2;在线难例挖掘;完全交并比损失
改进Cascade R-CNN的面料疵点检测方法

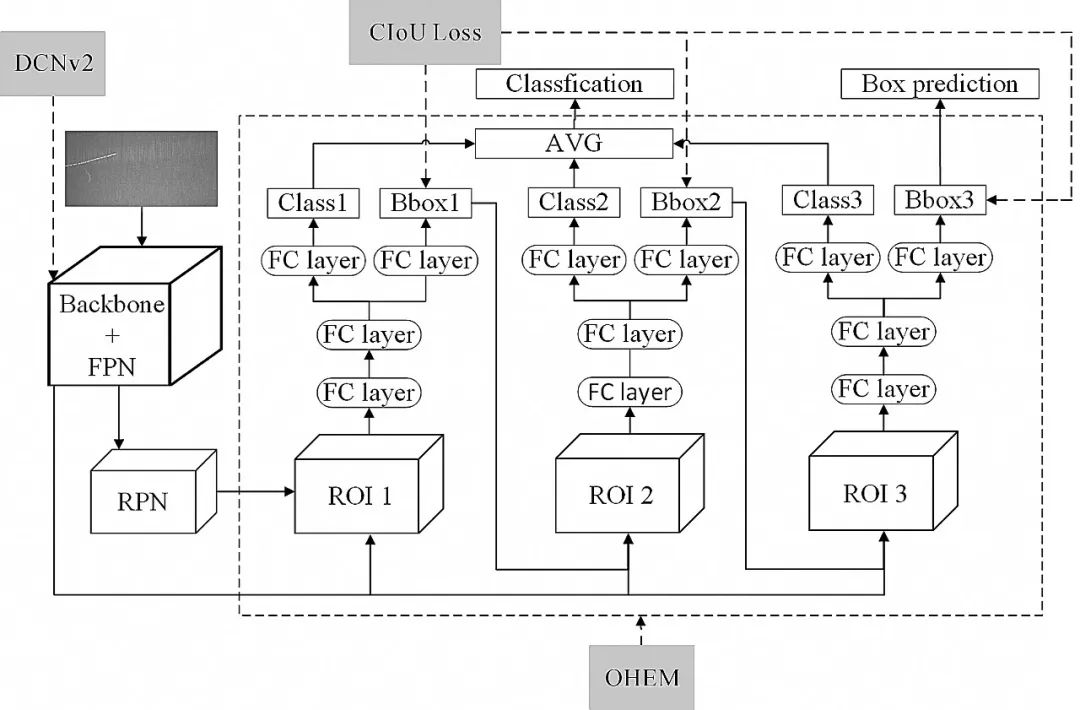
图1 Cascade R-CNN网络结构
Fig.1 Architecture of the Cascade R-CNN network
1.1 在线难例挖掘采样
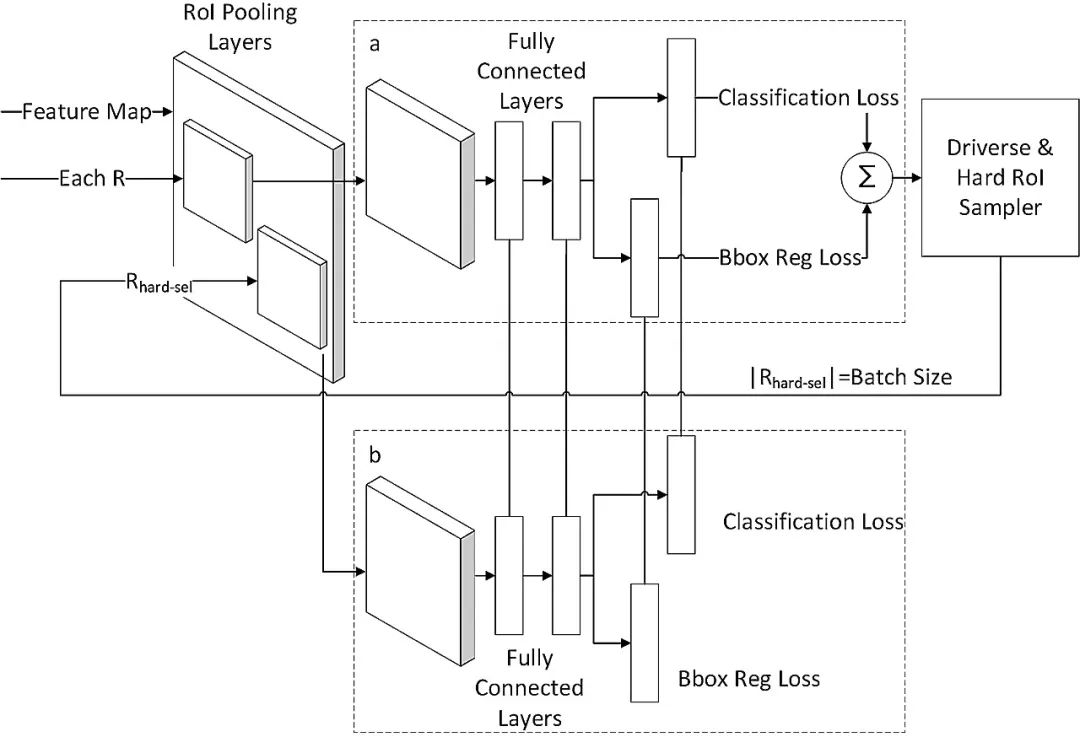
图2 在线难例挖掘结构
Fig.2 Architecture of online hard example mining
1.2 可变形卷积v2
R={(-1,-1),(-1,0)...,(0,1),(1,1)}
(1)
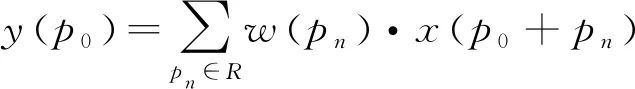
(2)
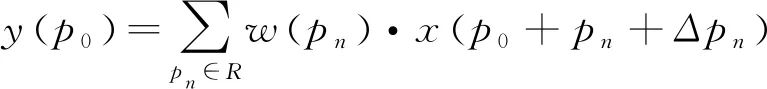
(3)
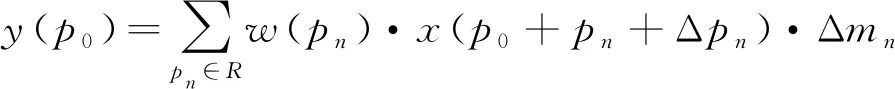
(4)
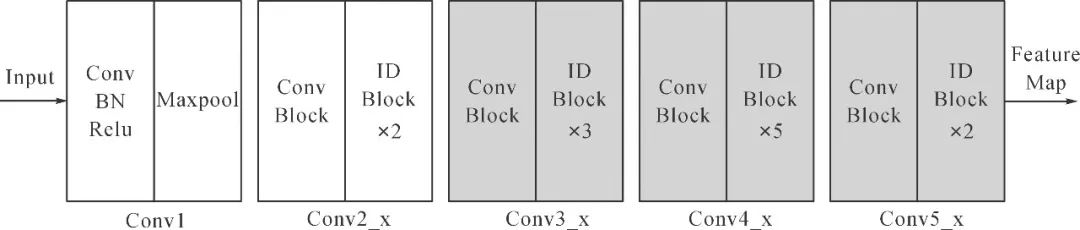
图3 Resnet骨干网络结构
Fig.3 Architecture of Resnet backbone network
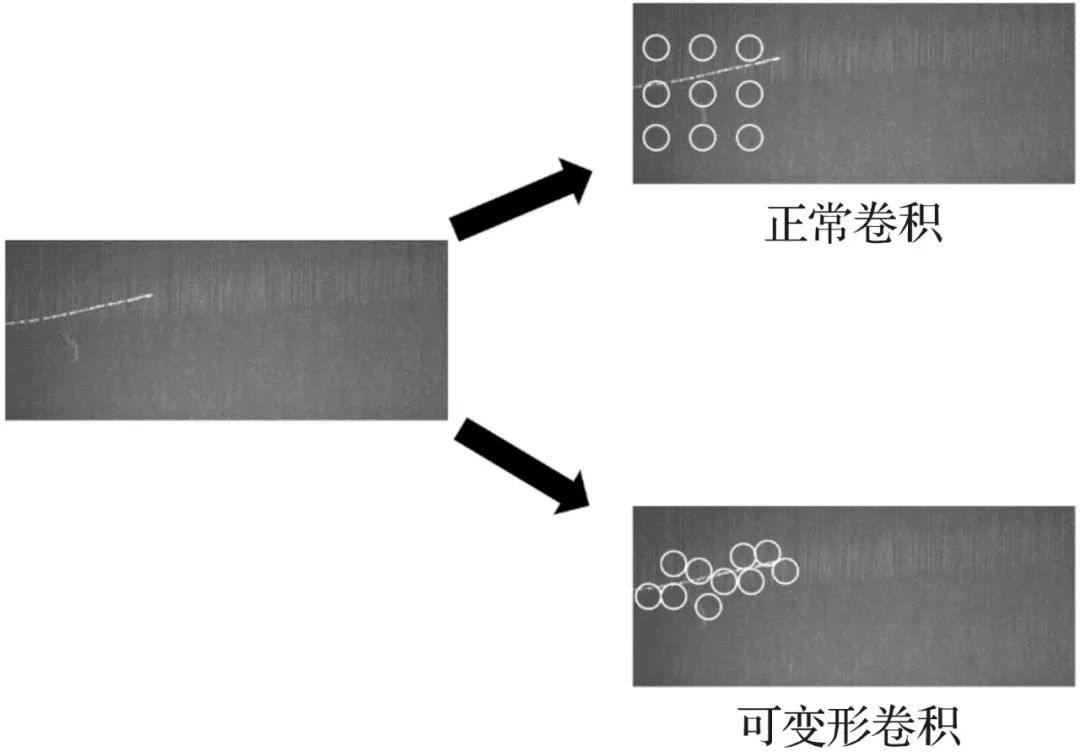
图4 可变形卷积示意
Fig.4 Diagram of deformable convolution
1.3 完全交并比损失函数
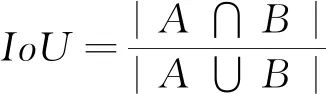
(5)
IoU Loss=-ln(IoU)
(6)
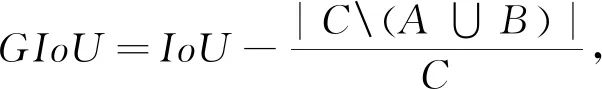
(7)
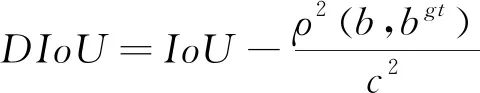
(8)
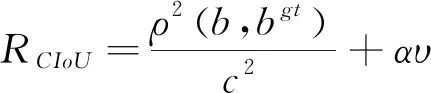
(9)
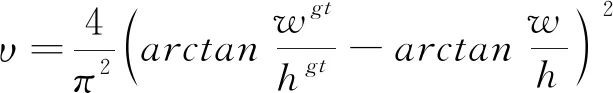
(10)
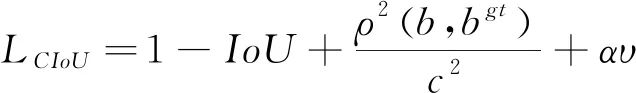
(11)
实验结果与对比分析
2.1 实验数据集
表1 布匹瑕疵的分类与数量
Tab.1 Classification and quantity of fabric defects
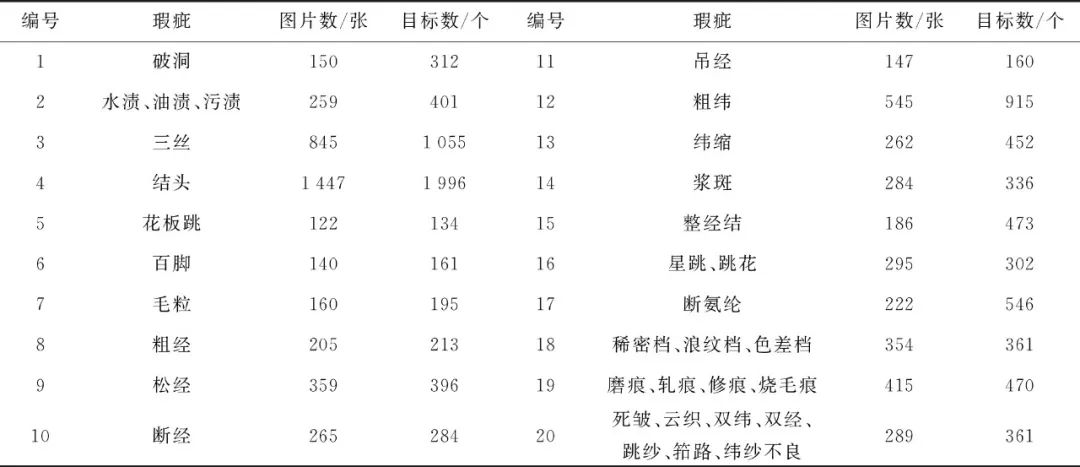
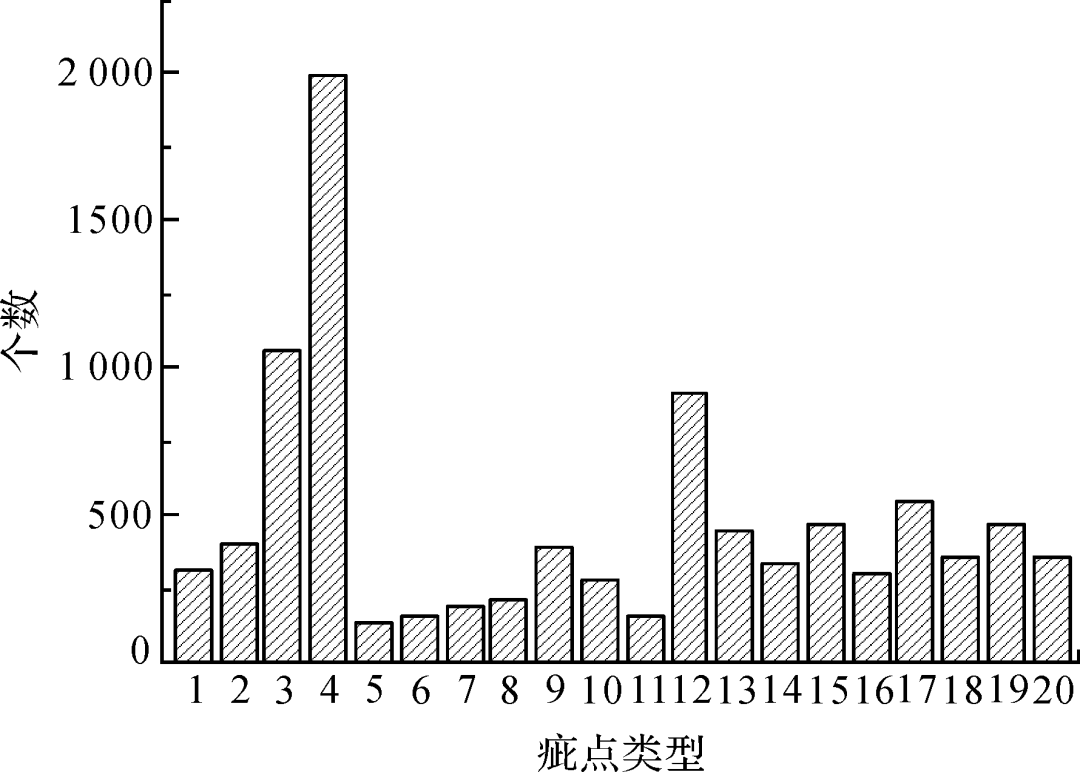
图5 不同类别目标数统计
Fig.5 Statistics of target number of different categories
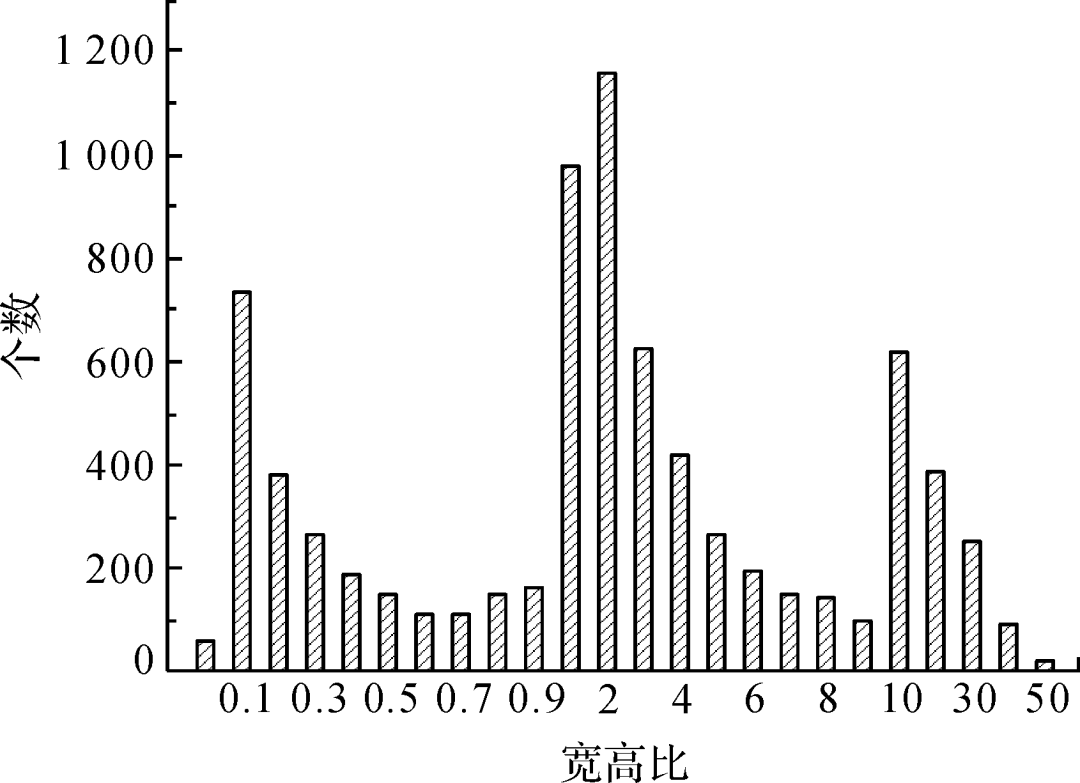
图6 目标宽高比统计
Fig.6 Statistics of target aspect ratio

图7 典型疵点
Fig.7 Typical defects
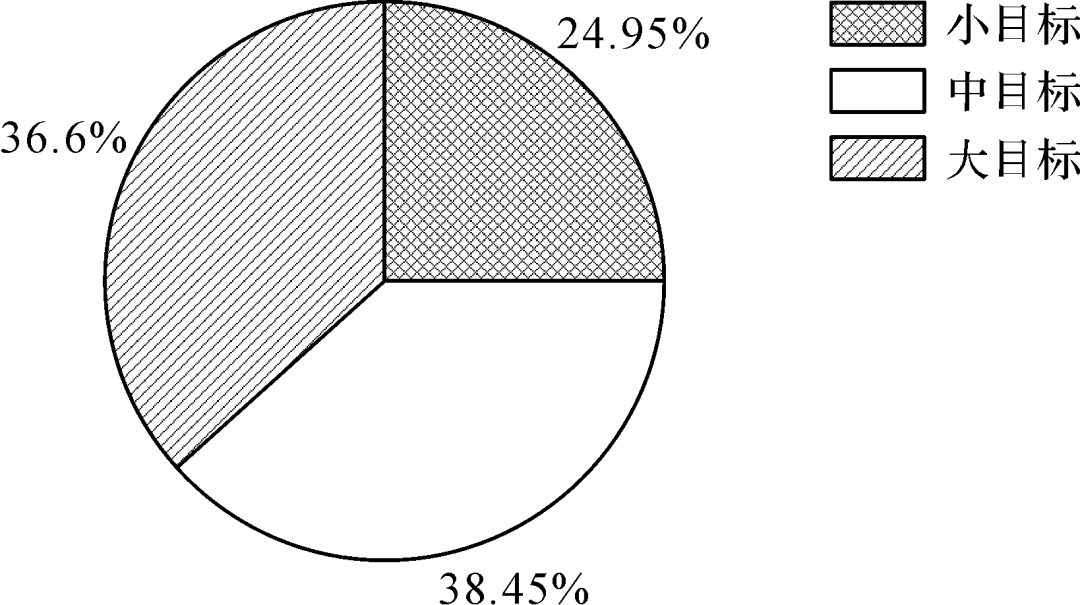
图8 目标面积统计
Fig.8 Statistics of target area
2.2 实验环境及配置
2.3 实验结果对比

图9 模型改进前后的检测效果对比
Fig.9 The Comparison of detection effect before and after model improvement
表2 模型改进前后的评价参数
Tab.2 Evaluation parameter before and after model improvement %
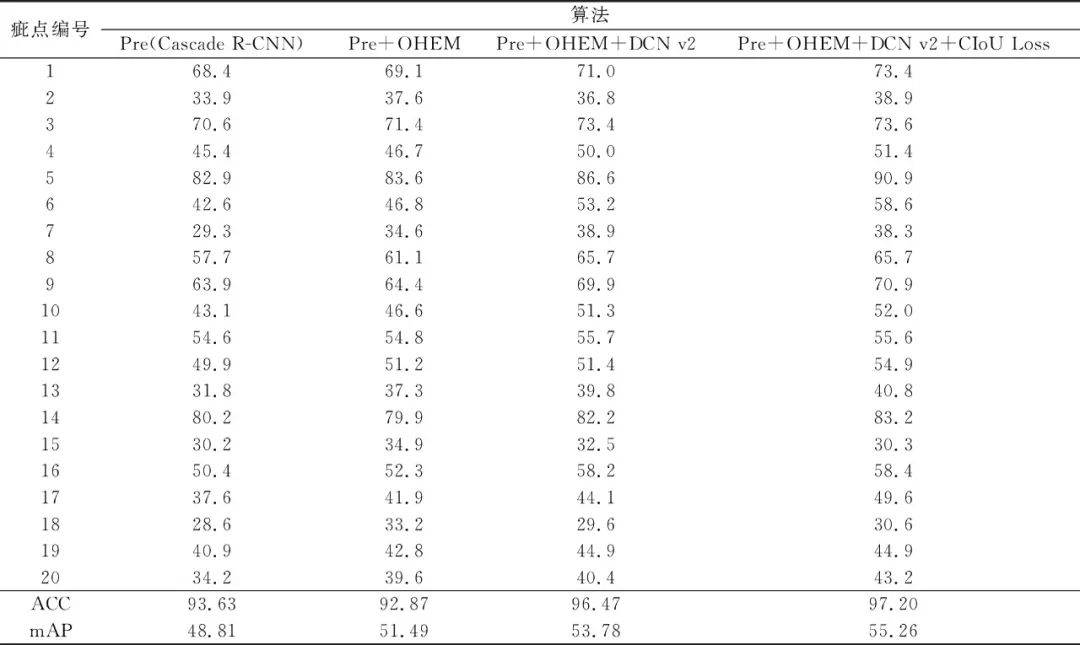
表3 不同光照强度下测试集的对比
Tab.3 The comparison of the proposed algorithm under different light intensities on test sets
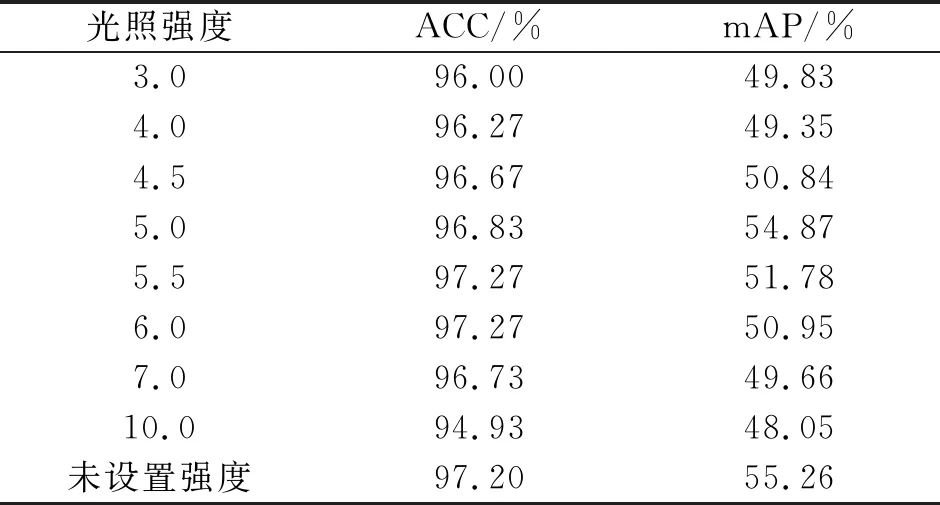
表4 引入OHEM前后的对比
Tab.4 The comparison before and after the introduction of OHEM

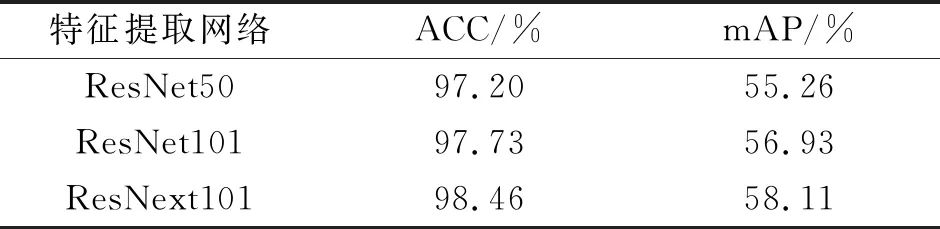
表5 算法在不同特征提取网络上的对比
Tab.5 The comparison of algorithms on different feature extraction networks
结 论
(点击阅读原文,阅读电子期刊)
参考文献
[1] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in context [C]// European Conference on Computer Vision, Cham: Pringer International Pubcishing, 2014:740-755.
[2] HU X, XU X, XIAO Y, et al. SINet: A scale-insensitive convolutional neural network for fast vehicle detection[J]. IEEE Transactions on Intelligent Transportation Systems,2019,20(3): 1010-1019.
[3] LI J, LIANG X, WEI Y, et al. Perceptual generative adversarial networks for small object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA. IEEE, 2017: 1222-1230.
[4] 陈康,朱威,任振峰,等.基于深度残差网络的布匹疵点检测方法[J]. 小型微型计算机系统,2020,41(4):800-806.
CHEN Kang, ZHU Wei, REN Zhenfeng, et al. Fabric defect detection method based on deep residual network[J]. Journal of Chinese Mini-Micro Computer Systems. 2020, 41(4): 800-806.
[5] 孟志青,邱健数.基于级联卷积神经网络的复杂花色布匹瑕疵检测算法[J]. 模式识别与人工智能,2020,33(12): 1135-1144.
MENG Zhiqing, QIU Jianshu. Defect detection algorithm of complex pattern fabric based on cascaded convolution neural network[J]. Pattern Recognition and Artificial Intelligence, 2020, 33(12): 1135-1144.
[6] CHAWLA N V, BOWYER K W, HALL L O, et al. Synthetic minority over-sampling technique[J]. Journal of artificial intelligence research,2002,16: 321-357.
[7] YANG Y Z, XU Z. Rethinking the value of labels for improving class-imbalanced learning[EB/OL]. 2020: arXiv: 2006.07529[cs.LG]. https://arxiv.org/abs/2006.07529.
[8] CAI Z W, VASCONCELOS N. Cascade R-CNN: Delving into high quality object detection[C]//Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA. IEEE, 2018: 6154-6162.
[9] ZHU X Z, HU H, LIN S, et al. Deformable ConvNets V2: More deformable, better results[C]//Conference on Computer Vision and Pattern Recognition. Long Beach, CA, USA. IEEE, 2019: 9300-9308.
[10] SHRIVASTAVA A, GUPTA A, GIRSHICK R. Training region-based object detectors with online hard example mining[C]// Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA. IEEE, 2016: 761-769.
[11] ZHENG Z H, WANG P, LIU W, et al. Distance-IoU loss: Faster and better learning for bounding box regression[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 12993-13000.
[12] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[13] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA. IEEE, 2016: 770-778.
[14] LIN T Y, DOLLwidth=9,height=12,dpi=110R P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA. IEEE, 2017: 936-944.
[15] DAI J F, QI H Z, XIONG Y W, et al. Deformable convolutional networks[C]//International Conference on Computer Vision. Venice, Italy. IEEE, 2017: 764-773.
[16] YU J H, JIANG Y N, WANG Z Y, et al. UnitBox: An advanced object detection network[C]//Proceedings of the 24th ACM International Conference on Multimedia. Amsterdam The Netherlands. New York, NY, USA: ACM, 2016: 516-520.
[17] REZATOFIGHI H, TSOI N, GWAK J, et al. Generalized intersection over union: A metric and a loss for bounding box regression[C]// Conference on Computer Vision and Pattern Recognition. Long Beach, CA, USA. IEEE, 2019: 658-666.
[18] BODLA N, SINGH B, CHELLAPPA R, et al. Soft-NMS: Improving object detection with one line of code[C]// International Conference on Computer Vision. Venice, Italy. IEEE, 2017: 5562-5570.
[19] NEUBECK A, VAN GOOL L. Efficient non-maximum suppression[C]// 18th International Conference on Pattern Recognition. Hong Kong, China. IEEE,2006: 850-855.
[20] 安萌,郑飂默,王诗宇,等.一种改进Faster R-CNN的面料疵点检测方法[J]. 小型微型计算机系统,2021,42(5):1029-1033.
AN Meng, ZHENG Liaomo, WANG Shiyu, et al. A fabric defect detection method based on improved faster R-CNN[J]. Journal of Chinese Computer Systems, 2021,42(5):1029-1033.
[21] 张泽苗,霍欢,赵逢禹. 深层卷积神经网络的目标检测算法综述[J]. 小型微型计算机系统,2019,40(9):1825-1831.
ZHANG Zemiao, HUO Huan, ZHAO Fengyu. Survey of object detection algorithm based on deep convolutional neural networks[J]. Journal of Chinese Computer Systems, 2019, 40(9): 1825-1831.
[22] PADILLA R, PASSOS W L, DIAS T L B, et al. A comparative analysis of object detection metrics with a companion open-source toolkit[J]. Electronics,2021,10(3): 279.
[23] 陈科圻,朱志亮,邓小明,等.多尺度目标检测的深度学习研究综述[J]. 软件学报,2021,32(4):1201-1227.
CHEN Keqi, ZHU Zhiliang, DENG Xiaoming, et al. Deep learning for multi-scale object detection: asurvey[J]. Journal of Software. 2021,32(4):1201-1227.
发布 | 浙江理工大学杂志社 新媒体中心
编辑 | 徐 航
本文仅做学术分享,如有侵权,请联系删文。