
基于点检测的物体检测方法(一):CornerNet
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
方法来自于文章:
代码:

文章思路和实现比较新奇,摒弃了常用的检测方法中通过检测物体bounding box进行目标检测的方法,通过检测点的方式进行目标检测。具体的,检测物体bounding box的左上角和右下角两个点,根据这两个点直接得到物体的bounding box。作者这个方法也是从人体pose estimation方法中的bottom-to-up的方法中得到的启发,如果做过pose estimation会更加容易理解作者意图和实现。
在看到上述描述,自然而然的就会想到以下几个问题:
1、怎么检测这个两个点?
2、怎么知道这两个点所组成的框包含物体的类别?
3、当图像中有多个物体时,怎么知道哪些点可以组成框?(哪些左上角的点和哪些右下角的点能够组成有效的框)
4、Loss是什么形式?
5、网络结构是怎么样的?
6、有没有什么比较新奇的东西?
带着上述的这些问题,我们先来看看整个算法的pipeline:
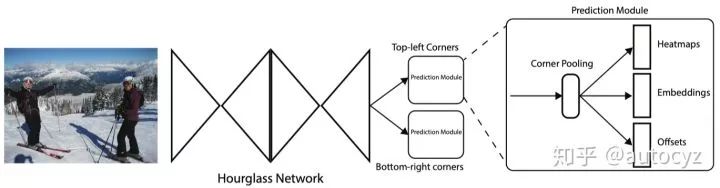
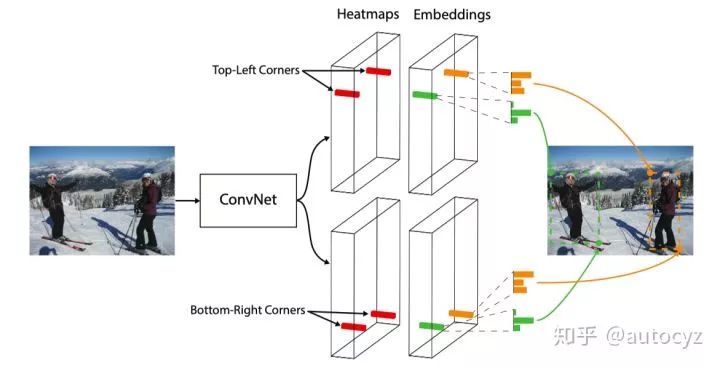
上面两幅图分别是算法的网络结构图和算法inference阶段的示意图。根据上面两幅图,可以大致梳理出算法的pipeline:
1、输入一张图像,经过backbone网络(Hourglass network)后,得到feature map。
2、将feature map同时输入到两个branch,分别用于预测Top-Left Corners和Bottom-right Corners。
3、两个branch都会先经过一个叫Corner Pooling的网络,最后输出三个结果,分别是Heatmaps、Embeddings、Offsets。
4、根据Heatmaps能够得到物体的左上角点和右下角点,根据Offsets对左上角和右下角点位置进行更加精细的微调,根据Embeddings可以将同一个物体的左上角和右下角点进行匹配。得到到最终的目标框。
下面就看看具体的实现细节:
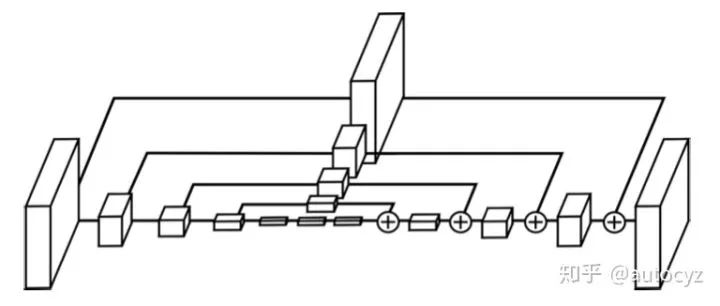
Hourglass是人体pose estimation领域非常经典常用的一个网络结构,其网络结构首先将feature的resolution逐步降低,再逐步的升高。在降低和升高的中间,通过shortcut进行连接。这样提取出的特征不仅能够包含有high-level的语义信息,也能够尽可能的保留空间信息。对于关键点回归的这类任务,对空间信息和高分辨率的feature map都有比较高的需求。
本文作者使用的Hourglass相对于最原始的Hourglass做了细微的改变,例如改变了使用Hourglass阶数、用stride=2的卷积代替max pooling等等。具体的改变可以看代码实现。
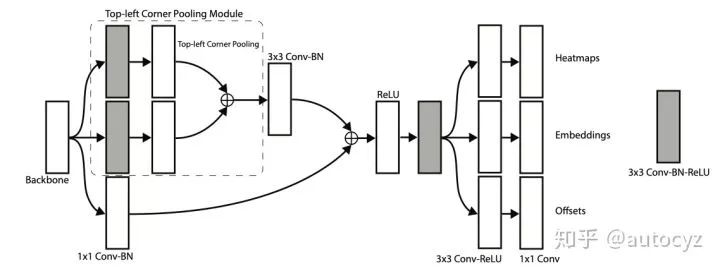
本文的算法模型,在backbone之后接上了两个prediction module branch,分别用于得到物体的左上角点和右下角点。
上图是左上角点的prediction module。主要有两部分组成,一部分是Corner Pooling,这部分后面会介绍,另一部分就是网络最后的输出部分了。网络输出三种feature map,heatmaps、embeddings、offsets。这些都会在后文进行详细介绍
在网络的输出部分,一共生成了2个heatmaps set,一个是用于左上角的检测,另一个是用于右下角的检测。每个heatmaps集合的形式都是  ,其中
,其中  代表的是检测目标的类别数,
代表的是检测目标的类别数,  和
和  则代表heatmap的分辨率。
则代表heatmap的分辨率。
简而言之,我们可以根据这个heatmap set最大的响应值,得到当前Corner点的位置和所属类别。例如,在左上角的heatmap set中,响应值最高的值出现在第c个channel的第(w,h)的位置,那么我们可以认为这个左上角点的位置就在(w,h),且这个Corner的类别就是第c个channel所对应的类别。
知道了heatmap set,就开始构造其Loss形式,作者使用了Focal loss,并对Focal loss做了一定的改变,具体形式如下:
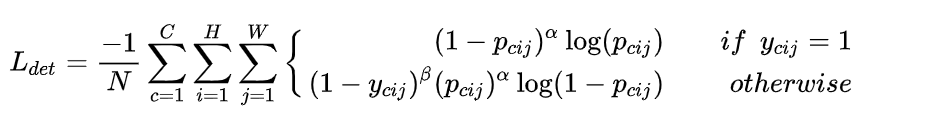
其中,  是图像中物体的数量,
是图像中物体的数量,  和
和  是一组超参(作者的设定
是一组超参(作者的设定  ,
,  ),用来控制图像中每个点对loss的贡献程度。另外,标签
),用来控制图像中每个点对loss的贡献程度。另外,标签  是一个由高斯函数生成的值:
是一个由高斯函数生成的值:  ,
,  和
和  表示的是以(
表示的是以(  ,
,  )为坐标原点,其他位置的相对坐标。此标签可以这么理解,真值位置的标签为1,真值附近一定范围内的标签不为0,是一个随着到真值位置距离的增大,而逐渐衰减的值。
)为坐标原点,其他位置的相对坐标。此标签可以这么理解,真值位置的标签为1,真值附近一定范围内的标签不为0,是一个随着到真值位置距离的增大,而逐渐衰减的值。
在Hourglass模型之前,为了减少计算量,往往会将特征的分辨率缩小一定倍数。例如,输入图像为368*368,而输出的feature map 只有46*46,原图像的坐标( , )映射到feature map上坐标就变成了(  ,
,  ),这样就产生了一定的误差:
),这样就产生了一定的误差:

为了减少这种误差对于最终预测结果的影响,作者加入了一个offset map,map上的值就当前Corner点的偏移量。其loss计算采用了Smooth1 Loss:

在一幅图中会出现多个物体,因此也会出现多个左上角点和右下角点。在这些检测出的点中,我们需要对其进行配对,即判断哪些点可以组成一对角点,能够检测出目标。作者这里使用的group方法也是效仿pose estimation(引文2)中的方法。其中主要思想是,在生成角点heatmap时,同时生成一个embedding vector,如果一个左上角角点和右下角角点属于同一个物体,那么他们的embeddng vector之间的距离就应该非常小。我们可以根据这些距离来对Corner点进行匹配。
但是这里又会有一个问题,embeding该怎么打标签呢?图像中的Corner数量不一定,我该怎么给他们,对于每个位置的Corner我该赋什么样的值呢?赋值有应该遵循什么样的规则赋呢?这些都是棘手的问题。
这里作者采用了非常巧妙的loss计算方法,避免了对embeding进行打标的过程。我们不需要管embeding中对应Corner位置的值具体是多少,我们关心的是应该配对的那两个角点的embedding向量的距离是不是很小,理想情况下成对的角点的embedding向距离应该为0 ,而不成对距离应该非常的大。
这里就可以引申出这个loss应该具有两部分,一部分可以pull成对的Corner点,让成对的Corner点的embedding向量差别较小,另一部分可以push不成对的Corner,让他们的embedding向量差异较大。


其中  和
和  图像中第k个目标的top-left点和bottom-right点的embedding向量,
图像中第k个目标的top-left点和bottom-right点的embedding向量,  表示两个embedding向量的均值。
表示两个embedding向量的均值。
上面讲的detecting corner 和grouping corner其实没有什么创新的地方,作者只不过是把他们从pose estimation领域引入到了object detection领域。作者自己本身提出的比较有创新的地方就是Corner Pooling。
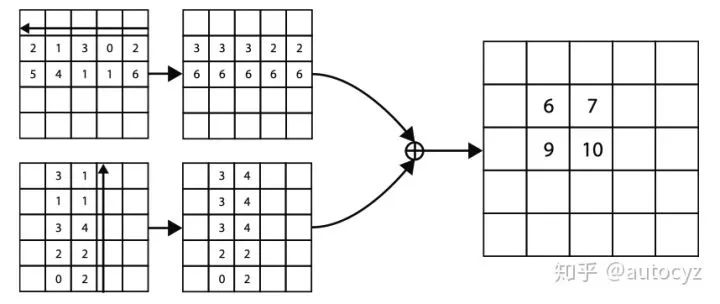
上图是top-left corner的 Corner Pooling过程。在水平方向,从最右端开始往最左端遍历,每个位置的值都变成从最右到当前位置为止,出现的最大的值。同理,bottom-right corner的Corner Pooling则是最左端开始往最右端遍历。同样的,在垂直方向上,也是这样同样的Pooling的方式。
Insight:以左上角点为例,当我们决定此点是否个corner点的时候,往往会沿着水平的方向向右看,看看是否与物体有相切,还会沿着垂直方向向下看,看看是否与物体相切。简而言之,其实corner点是物体上边缘点和坐边缘点的集合,因此在pooling的时候通过Corner Pooling的方式能够一定程度上体现出当前点出发的射线是否与物体向交。
在训练阶段,网络的输入分辨率为511*511, 输出的分辨率为128*128
训练阶段总的loss:
 ,且
,且  ,
, 
inference阶段的时间:244ms/per image,速度比较慢,这里我理解输出慢的原因有两个:1)网络比较大,尤其是输出的feature map比较多,因为输出的feature map的channel数是与物体类别数相关的。2)后处理阶段,需要对所有可能的Corner组合都进行一次embedding向量的距离计算。
现在再回头看文章一开头提的那几个问题,都可以一一解答了:
1、怎么检测这个两个点?
生成keypoint的heatmap,heatmap中响应值最大的位置就是点的位置。
2、怎么知道这两个点所组成的框包含物体的类别?
Corner响应值最大所在的channel即对应了物体的类别。
3、当图像中有多个物体时,怎么知道哪些点可以组成框?(哪些左上角的点和哪些右下角的点能够组成有效的框)
生成embedding向量,用向量的距离衡量两个Corner是否可以组成对。
4、Loss是什么形式?
loss总共分了三个部分,一部分是用于定位keypoint点的detecting loss,一个是用于精确定位的offset loss,一个是用于对Corner点进行配对的grouping loss
5、网络结构是怎么样的?
使用Hourglass作为backbone,使用Corner Pooling构造了prediction module,用来得到最终的结果。
6、有没有什么比较新奇的东西?
提出的Corner Pooling。
第一次使用检测点的方法检测物体。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~