
基于立体R-CNN的3D对象检测
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

双目立体视觉是机器视觉的一种重要形式,其原理是基于视差图像形成设备,使用从两个不同位置获取的物体图像,通过计算图像之间的对应点的位置偏差来获得三个对象的三维几何信息。
YOLO最初是由约瑟夫·雷德蒙(Joseph Redmon)创作的,用于检测物体。物体检测是一种计算机视觉技术,它通过在对象周围绘制边框并标识给定框也属于的类标签来对对象进行定位和标记。与大型NLP不同,YOLO设计得很小,可以为设备上的部署提供实时推理速度。
文献[1]提出了一种在立体图像方法中充分利用稀疏,密集,语义和几何信息的三维物体检测方法,称为立体R-CNN,用于自动驾驶。
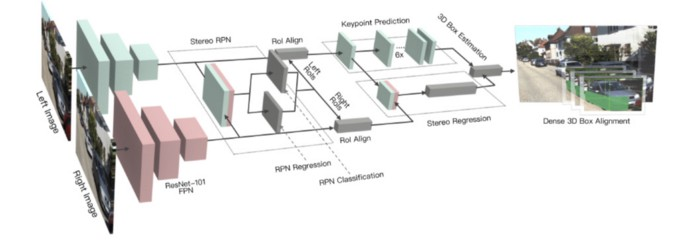
Stereo R-CNN的网络体系结构将输出立体框,关键点,尺寸和视点角,然后输出3D框估计和密集3D框对齐模块。
Faster R-CNN扩展为立体信号输入,以同时检测和关联左右图像中的对象。稀疏的关键点,视点和对象尺寸是通过在三维区域提议网络之后添加其他分支来预测的,该分支网络与2D左右框组合以计算3D粗略对象边界框。然后,通过使用左RoI和右RoI的基于区域的光度对齐来恢复准确的3D边界框。
该方法不需要输入深度和3D位置,但是效果比所有现有的基于完全监督的图像方法都要好。在具有挑战性的KITTI数据集上进行的实验表明,该方法在3D检测和3D定位任务上的性能要比最先进的基于立体的方法好30%左右。
网络架构
立体RPN
该模型基于传统的RPN网络,首先从左右图像中提取对位特征,然后将不同比例的特征连接在一起。特征提取后,利用3×3卷积层减少通道,然后是两个同级完全连接的图层,用于对每个输入位置的对象性和回归框偏移进行分类,并使用预定义的多尺度框进行锚定。对于客观性分类,真值框定义为左右图像的联合GT框。
当与真值框的交集大于0.7时,锚点被标记为正样本;如果小于0.3,则将锚点标记为正样本。分类任务的候选帧包含左右真实值帧区域的信息。

RPN分类和回归的不同目标分配。来源[1]
对于立体框回归,他们计算重新定位到目标获取联合GT框中包含的左GT框和右GT框的正锚的偏移,然后分别为左回归和右回归指定偏移。
要返回的参数定义为[u,w,u',w',v,h],它们是左对象的水平位置和宽度,右对象的水平位置和宽度以及垂直位置和高度。因为输入是校正后的左右图像,所以可以认为左右对象在垂直方向上对齐。
每个左、右目的建议都是通过相同的锚生成的,并且自然而然地,左、右目的建议是相关的。通过NMS之后,保留左,右眼仍然存在的提案关联对,进行前2000个培训,并使用前300个进行测试。
立体R-CNN
在立体声RPN之后,将ROI对齐操作应用于左右特征图。对应于concat的左右ROI功能输入到两个连续的完全连接的层中。
使用四个分支分别预测:
对象类
与立体声rpn一致的立体声包围盒,左右对象的高度已对齐;
尺寸,首先计算平均尺寸,然后预测相对数量;
视点角
这里的回归部分与立体RPN一致,重点在于视点角度。
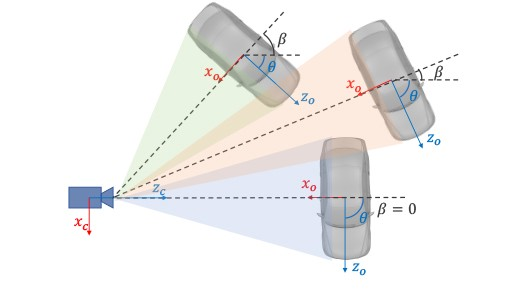
假设物体的方向为θ,并且汽车中心与相机中心之间的方位角为β,则视点的角度为α=θ+β。来源[1]
使用θ表示图像每一帧中车辆的运动方向。β表示目标相对于相机中心的方位角。图片中的三辆汽车具有不同的方向,但它们在ROI图像上的投影完全相同。
定义回归的视角α=θ+β以避免中断,将训练目标设置为[sinα,cosα]而不是角度值。
除了立体框和视点角之外,他们还注意到投影到边界框的3D边界框的角可以提供更严格的约束。
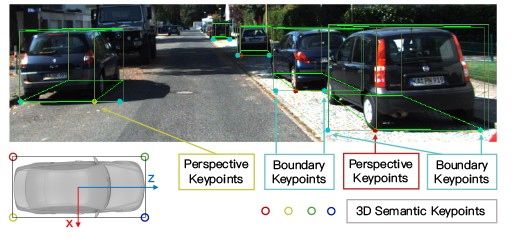
3D语义关键点,2D透视关键点和边界关键点的说明。来源[1]
与Mask RCN N 类似的结构用于预测关键点。定义了四个3D语义关键点,即,车辆底部的3D角点。同时,将这四个点投影到图像上以获得四个透视关键点。这一点在3D bbox回归中起作用,我们将在下一部分中介绍它。在关键点检测任务中,使用Roi Align获得的14 x 14特征图。卷积和解卷积后,最终获得6 x 28 x 28的特征图。
为了简化计算,它们将高度通道求和并将6×28×28转换为6×28,其中前4个通道代表将4个关键点投影到相应的u坐标的概率,后两个通道代表概率左右边界上的关键点的集合。
3D Box估计
使用稀疏关键点信息和2D边界框信息,可以估算出粗糙的3D边界框。
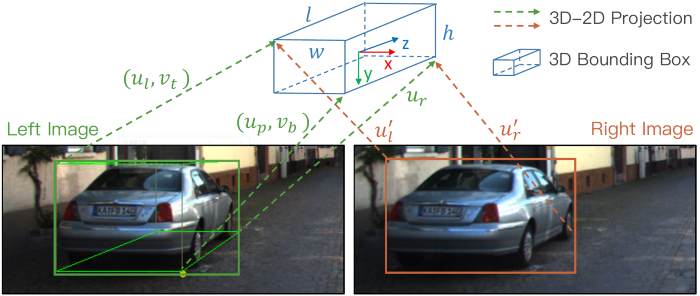
3D包围盒的状态被定义为x = {x,y,z,θ},其分别表示3D中心的点坐标和水平方向上的偏转角。
给定左右2D边界框,透视关键点和回归尺寸,可以通过最小化二维反投影的误差来获得3D边界框。
从立体边界框和透视关键点中提取了七个测量参数:
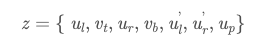
它们表示左2D边界框的左,上,右和下边界,右2D边界框的左和右半径以及透视关键点坐标u。每个参数都需要通过相机内部参数进行归一化。给定透视关键点,可以推断出3D边界框的角和2D边界框的边缘之间的对应关系。
密集3D框对齐
对于左图像中有效ROI区域的每个归一化像素坐标值,图像误差定义为:
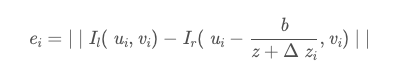
I l,Ir代表左右图像透视图的三通道RGB矢量。和,
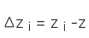
是像素i和3D边界框中心的深度偏差值,b是基线的长度,只有z是我们需要求解Objective变量的值。
他们使用双线性插值来获取正确图像中的子像素值。当前的匹配成本定义为覆盖有效ROI区域中所有像素的平方差之和:
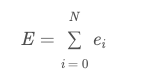
中心点深度值z可以通过最小化当前匹配成本E来计算。我们可以通过枚举深度值来加快最小化成本的过程。我们枚举初始值周围每0.5米总共有50个深度值,以得到一个粗略的深度值,然后枚举每0.05米周围就总共有20个深度值,以得到一个精确的深度值。
该方法避免了在全局深度估计过程中由一些无效像素引起的中断问题,并且整个方法更加健壮。
参考文献
Li, Peiliang, Xiaozhi Chen, and Shaojie Shen. “Stereo R-CNN based 3D Object Detection for Autonomous Driving.” arXiv preprint arXiv:1902.09738 (2019).
Chabot, M. Chaouch, J. Rabarisoa, C. Teuli`ere, and T. Chateau. Deep manta: A coarse-to-fine many-task net-work for joint 2d and 3d vehicle analysis from monocularimage. InProc. IEEE Conf. Comput. Vis. Pattern Recog-nit.(CVPR), pages 2040–2049, 2017.
J.-R. Chang and Y.-S. Chen. Pyramid stereo matching net-work. InProceedings of the IEEE Conference on ComputerVision and Pattern Recognition, pages 5410–5418, 2018.
X. Chen, K. Kundu, Z. Zhang, H. Ma, S. Fidler, and R. Urta-sun. Monocular 3d object detection for autonomous driving.InEuropean Conference on Computer Vision, pages 2147–2156, 2016.
X. Chen, K. Kundu, Y. Zhu, H. Ma, S. Fidler, and R. Urtasun.3d object proposals using stereo imagery for accurate objectclass detection. InTPAMI, 2017.
X. Chen, H. Ma, J. Wan, B. Li, and T. Xia. Multi-view 3dobject detection network for autonomous driving. InIEEECVPR, volume 1, page 3, 2017.
M. Engelcke, D. Rao, D. Z. Wang, C. H. Tong, and I. Posner.Vote3deep: Fast object detection in 3d point clouds usingefficient convolutional neural networks. InRobotics and Au-tomation (ICRA), 2017 IEEE International Conference on,pages 1355–1361. IEEE, 2017.
A. Geiger, P. Lenz, and R. Urtasun. Are we ready for au-tonomous driving? the kitti vision benchmark suite. InCom-puter Vision and Pattern Recognition (CVPR), 2012 IEEEConference on, pages 3354–3361. IEEE, 2012
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~