
重磅开源!屠榜各大CV任务的微软Swin Transformer有多强?
Swin Transformer 可以理解为一个通用的视觉骨干网络,Swin Transformer 设计出了一种分层表示形式,首先由小的 PATCHES 开始,而后逐渐将相邻的各 Patches 融合至一个更深的 Transformer 层当中。通过这种分层结构,Swin Transformer 模型能够使用 FPN 及 UNET 等高密度预测器实现技术升级,通过限制非重叠窗口中的部分计算量降低计算强度。各窗口中的 PATCHES 数量是固定的,因此随着图像尺寸的增加,复杂性也将不断增长。相比于 ViT,Swin Transfomer 计算复杂度大幅度降低,随着输入图像大小线性计算复杂度。
Swin Transformer 的核心设计是将 Self-Attention 层划分为 SHIFT,SHIFTED Window 接入上一层窗口,二者之间保持连接,由此显著增强建模能力。这种策略还有助于有效降低延迟:所有 Query Patches 窗口共享同一 KEY 集,由此节约硬件内存;以往的 Transformer 方法由于使用不同的 Query 像素,因此在实际硬件中往往具有较高延迟;论文实验证明,SHIFTED Window 方法带来的延迟较传统滑动方法更低,且二者的建模能力基本相同。
基于此,Swin Transformer 在各类回归任务、图像分类、目标检测、语义分割等方面具有极强性能,其性能优于 VIT/DEIT 与 RESNE (X) T。

GitHub 地址:https://github.com/microsoft/Swin-Transformer
原作者团队曹越在知乎上的回答:https://www.zhihu.com/question/437495132/answer/1800881612
论文地址:https://arxiv.org/pdf/2103.14030.pdf
Swin Transformer 的架构如下图所示。首先,它与 VIT 一样将输入的图片划分为多个 Patches,作者使用 4 x 4 的 patch 大小;之后是嵌入层,最后则是作者设计的 Swin Transformer BLOCK。
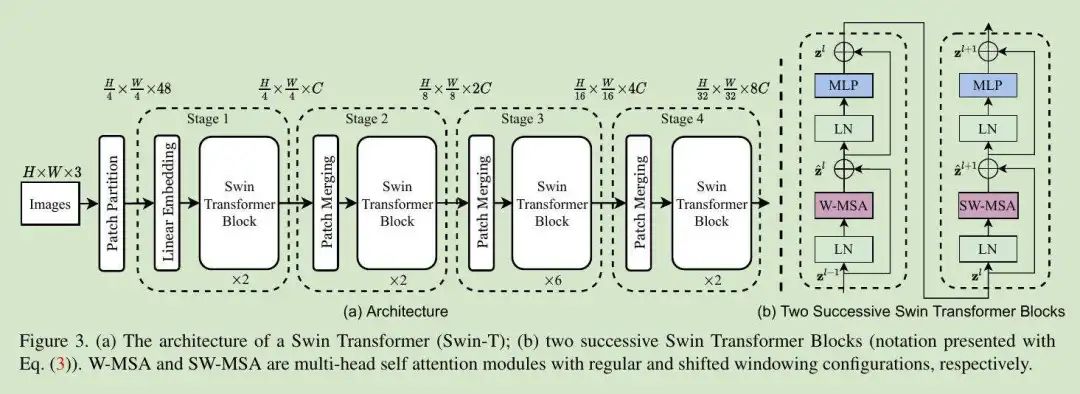
Swin Transformer Block:此模块是 Transformer 中使用 Shifted Window 的多 ATTENTION 模块,具有一致性;Swin Transformer 模块中包含一个 MSA(多头 Attention)模块 SHIFTED WINDOW,之后是 2 层 MLP,接着将 Layernorm 层添加至各 MSA 模块与各 MLP 层内,而后是剩余连接。
标准 Transformer 使用全局 self-attention 以创建各令牌之间的关系,但这会令图像大小增加 2 倍、导致复杂性随之提升,因此不适用于处理高强度任务。为了提升建模效率,作者提出由“部分窗口计算 Self-Attention”,即假设各个窗口均包含 MXM Patches、全局 MSA 模块与基于窗口的 MSA 模块,并在 HXW Patches 的图像之上进行复杂度计算:
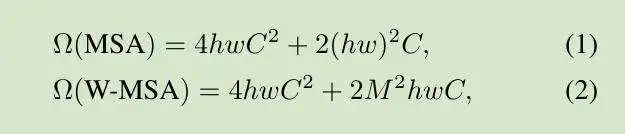
(1)的复杂度为 PATCH 数量 HW 的次生增长;(2)则为线性增长,其中 m 为固定值,但全局 self-attention 为大 HW,因此基于窗口的 Self-Attention 计算量不会很高。
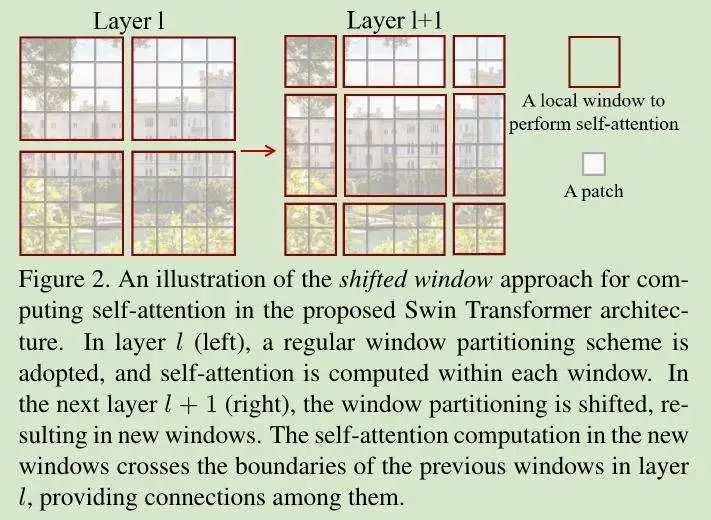
基于 Windows 的 Self-Attention 虽然拥有线性增长的复杂度,但其缺少在各窗口之间的连接,因此限制了模型的建模能力。
为了在容器上引入连接以实现模型维护,作者提出了 SHIFTED Window 分割的概念。第一个模块使用中性窗口分割,并根据窗口大小的 M=4 放大得出一个 8 x 8 的特征图。我们将此窗口划分为 2 x 2 的形式,而后通过 Shifted Window 设置下一模块,将其移动 M/2 个像素。
使用 SHIFTED 结构,Swin Transformer Blocks 的计算如下所示:

W-MSA 与 SW-MSA 分别表示使用整齐分割与 SHIFTED SELF-ATTENTION。
Shifted Window 可以跨越多个窗口向模型添加连接,并保持模型的良好运行效率。
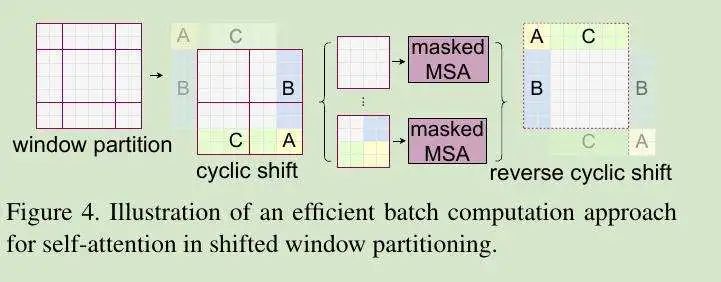
SHIFTED WINDOW 也有自己的问题,即导致窗口数量增加——由原本的 (h / m xw / m) 个增加到 ((h / m + 1) x (W / m + 1)) 个,而且其中某些窗口要小于 MXM。这种方法会将较小的窗口填充为 MXM,并计算 attention 值以掩蔽填充操作;当窗口数量较少、但大于 2 x 2 时,由此带来的额外计算量将相当可观(由 2 x 2 到 3 x 3,计算量增加达 2.25 倍)。
因此,作者提出了一种更为高效的 BATCH 计算方法,即沿左上角执行 Cyclic Shift。在完成这项位移之后,Batch WINDOW 将拥有一张由非相邻子窗口组成的特征图,这相当于是使用 Cyclic-Shift、Batch-Windows 与整齐窗口分割限制子窗口内的 Self-Attention 数量,从而极大提高了计算效率。
相对位置偏移:
作者介绍了 Self-Attention 中各头的相对位置。偏移 B:
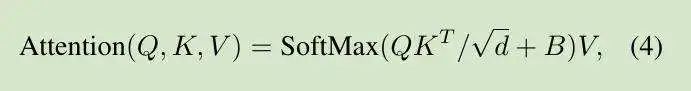
其中:
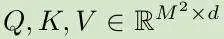
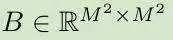
这将显著提高性能表现。
作者根据大小与计算复杂度建立起一套基本模型,名为 SWIN-B;同时引入了 SWIN-T、SWIN-S 与 SWIN-L,其模型大小与复杂度分别为 0.25 倍、0.5 倍与 2 倍。
当我们将窗口大小 M 设定为 7 时,各头部查询 D 为 32,各扩展层的 mlp α为 4。

其中 C 为初始阶段隐藏层的通道数量。
表 1A,从零开始在 ImgeNet-1K 上进行训练:
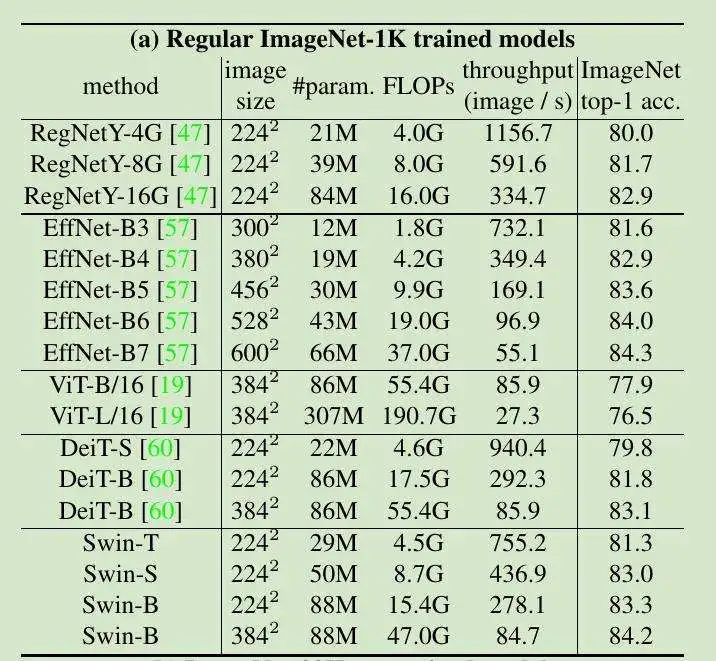
表 1B,在 ImageNet-22k 上进行首轮训练,之后迁移至 ImageNet-1K:
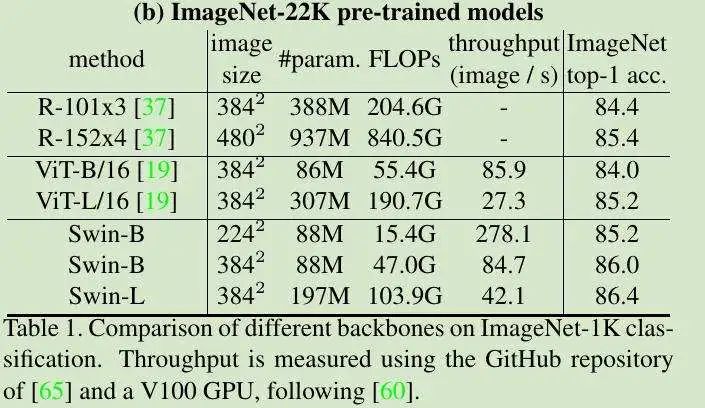
表 2A,在不同模型帧上使用 Swin Transformer 替代 BackBone:
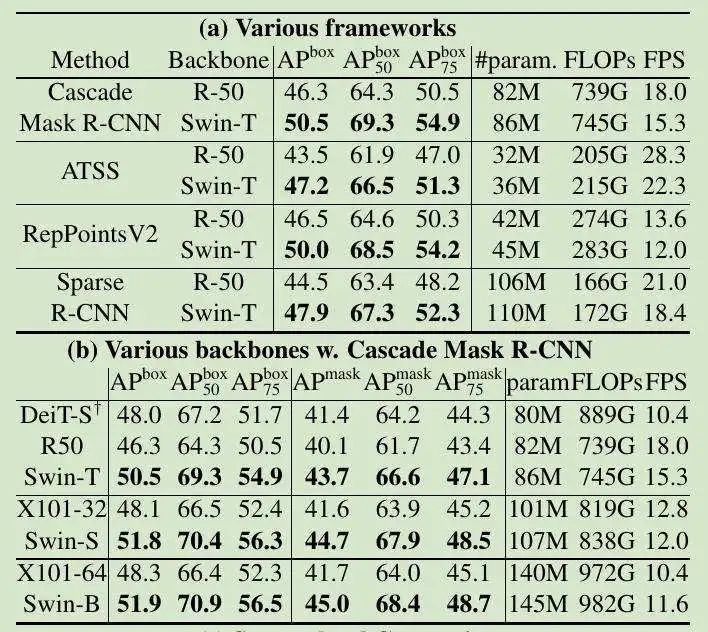
表 2C,与 SOTA 的比较结果:
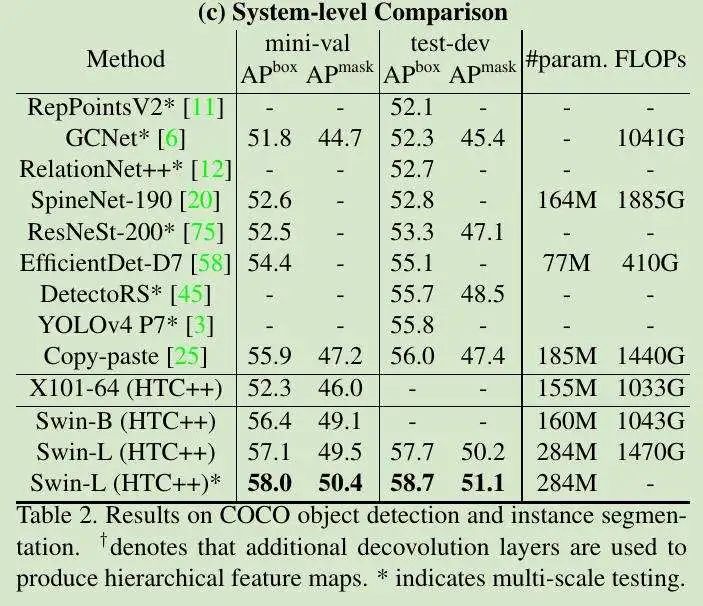
表 3,对于较小模型,可提供比先前 SOTA SETR 更高的 MIOU:
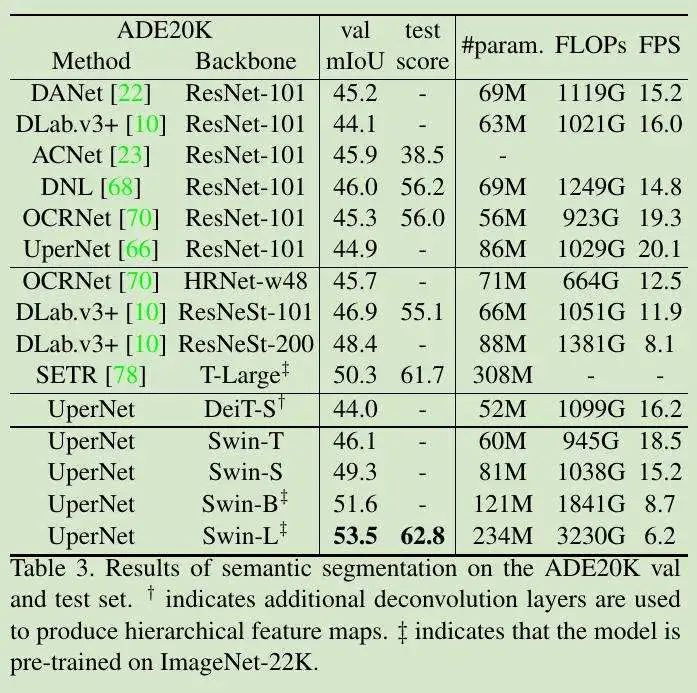
表 4,Shifted Window 在相对位置偏移中的性能改进:
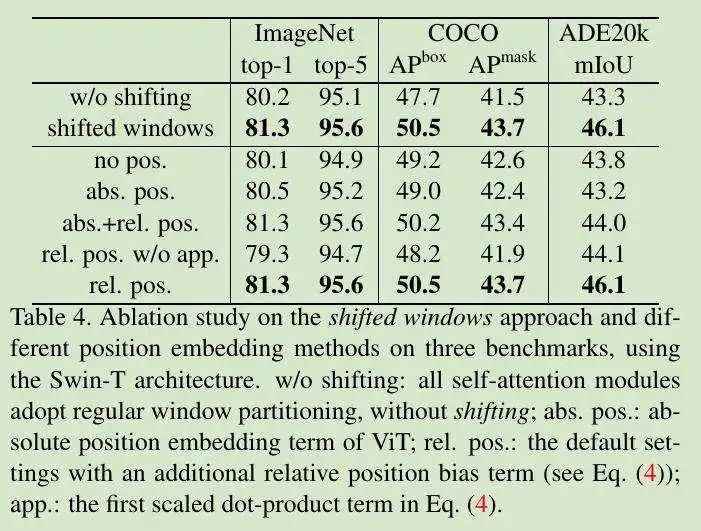
表 5,SHIFTED WINDOW 与 CYCLIC 高效执行:
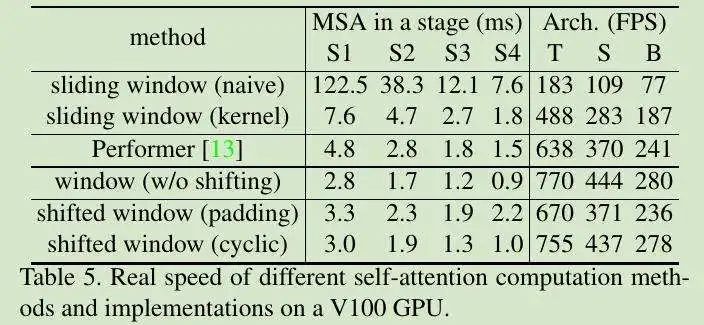
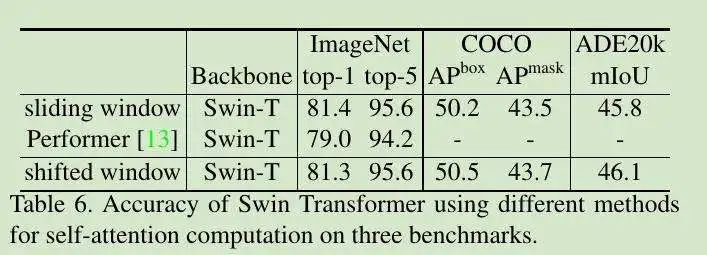
表 6,不同 Self-Attentions 的比较:
ViT 的出现扩大了 Transformer 的使用范围,这也让 AI 领域的从业者开始关注 Transformer 与 CNN 的关系。在知乎上,一位用户提问称:
目前已经有基于 Transformer 在三大图像问题上的应用:分类(ViT),检测(DETR)和分割(SETR),并且都取得了不错的效果。那么未来,Transformer 有可能替换 CNN 吗,Transformer 会不会如同在 NLP 领域的应用一样革新 CV 领域?后面的研究思路可能会有哪些呢?
关于这个问题,很多知乎答主已经给出了自己的答案,包括浙江大学控制科学与工程博士、复旦大学微电子学院硕士、阿里巴巴高级算法专家等,大体总结为未来是否会形成完全替代尚不好预测, 但对 CNN 的降维打击已经形成。
感兴趣的用户可以到知乎阅读各位答友的完整回答:https://www.zhihu.com/question/437495132/answer/1800881612
参考链接:https://www.programmersought.com/article/61847904617/
往期精彩:
求个在看