
重磅开源!屠榜各大CV任务!最强骨干网络:Swin Transformer来了
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
Swin Transformer 代码于2021年4月13日凌晨刚刚开源!
Swin Transformer Official Code已经release啦:
Image Classification:
https://github.com/microsoft/Swin-Transformer
Object Detection:
https://github.com/SwinTransformer/Swin-Transformer-Object-Detection
Semantic Segmentation:
https://github.com/SwinTransformer/Swin-Transformer-Semantic-Segmentation
来源:https://www.zhihu.com/question/451860144/answer/1832191113
Transformer 在CV上的应用前景
在Attention is all you need那篇文章出来之后,就一直在思考一个问题:从建模的基本单元来看,self-attention module到底在vision领域能做什么?从现在回头看,主要尝试的就是两个方向:
1. 作为convolution的补充。绝大多数工作基本上都是从这个角度出发的,比如relation networks、non-local networks、DETR,以及后来的一大批改进和应用。其中一部分是从long-range dependency引入,某种程度上是在弥补convolution is too local;另一部分是从关系建模引入,例如建模物体之间或物体与像素之间的关系,也是在做一些conv做不了的事。
2. 替代convolution。在这个方向上尝试不多,早期有LocalRelationNet、Stand-alone Self-attention Net。如果仅看结果,这些工作基本上已经可以做到替换掉3x3 conv不掉点,但有一个通病就是速度慢,即使是写kernel依然抵不过对conv的强大优化,导致这一类方法在当时并没有成为主流。
到这个时候(2020年左右),我自己其实有一种到了瓶颈期的感觉,作为conv的补充好像做的差不多了,后续的工作也都大同小异,替代conv因为速度的问题难以解决而遥遥无期。
没想到的是,Vision Transformer(ViT)在2020年10月横空出世。
ViT的出现改变了很多固有认知,我的理解主要有两点:1. locality(局部性);2. translation invariance(平移不变性)。从模型本身的设计角度,ViT并不直接具有这两个性质,但是它依然可以work的很好,虽然是需要大数据集的。但DeiT通过尝试各种tricks使得ViT可以只需要ImageNet-1k就可以取得非常不错的性能,使得直接上手尝试变得没那么昂贵。
其实对ViT的accuracy我个人不是特别惊讶,一方面是因为之前在local relation那一系列已经证明了self-attention有替代conv的能力,另一方面是因为19年iclr有一篇paper叫BagNet,证明了直接切patch过网络,在网络中间patch之间没有交互,最后接一个pooling再做classification,结果也已经不错了,在这个的基础上加上self-attention效果更好是可以理解的。
我个人其实惊讶于ViT/DeiT的latency/acc curve,在local relation net里速度是最大的瓶颈,为什么ViT可以速度这么快?仔细对比ViT与local relation可以发现,这里一个很大的区别是,ViT中不同的query是share key set的,这会使得内存访问非常友好而大幅度提速。一旦解决了速度问题,self-attention module在替代conv的过程中就没有阻力了。
基于这些理解,我们组提出了一个通用的视觉骨干网络,Swin Transformer [paper] [code],在这里简单介绍一下。
https://arxiv.org/abs/2103.14030
https://github.com/microsoft/Swin-Transformer
1. 之前的ViT中,由于self-attention是全局计算的,所以在图像分辨率较大时不太经济。由于locality一直是视觉建模里非常有效的一种inductive bias,所以我们将图片切分为无重合的window,然后在local window内部进行self-attention计算。为了让window之间有信息交换,我们在相邻两层使用不同的window划分(shifted window)。
2. 图片中的物体大小不一,而ViT中使用固定的scale进行建模或许对下游任务例如目标检测而言不是最优的。在这里我们还是follow传统CNN构建了一个层次化的transformer模型,从4x逐渐降分辨率到32x,这样也可以在任意框架中无缝替代之前的CNN模型。
Swin Transformer的这些特性使其可直接用于多种视觉任务,包括图像分类(ImageNet-1K中取得86.4 top-1 acc)、目标检测(COCO test-dev 58.7 box AP和51.1 mask AP)和语义分割(ADE20K 53.5 val mIoU,并在其公开benchmark中排名第一),其中在COCO目标检测与ADE20K语义分割中均为state-of-the-art。
来源:https://www.zhihu.com/question/437495132/answer/1800881612
对比Swin Transformer的实验结果,或许能明白为啥如此受关注!
图像分类方面:
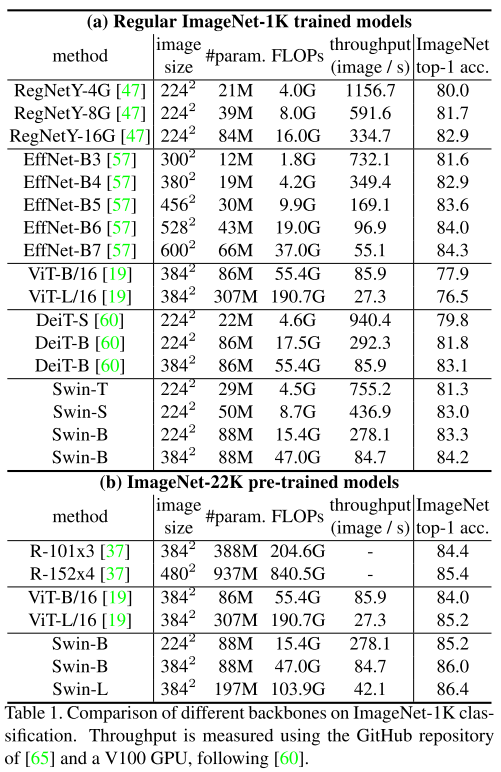
目标检测方面:
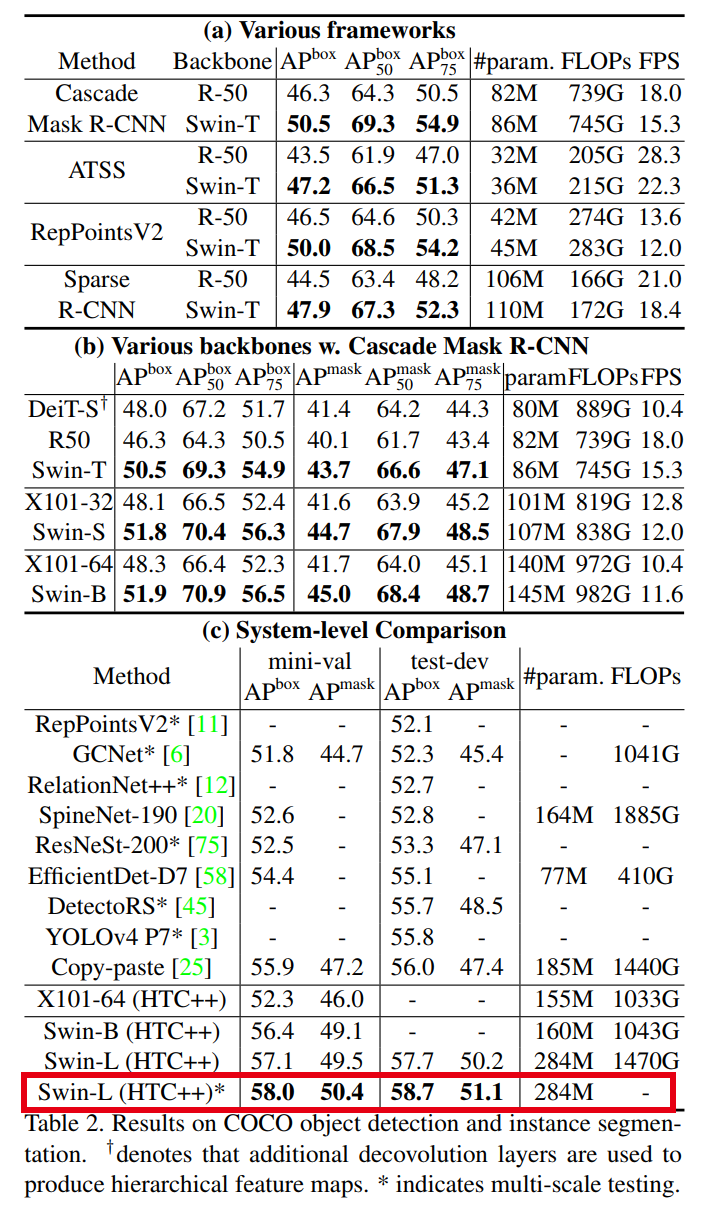
语义分割方面:
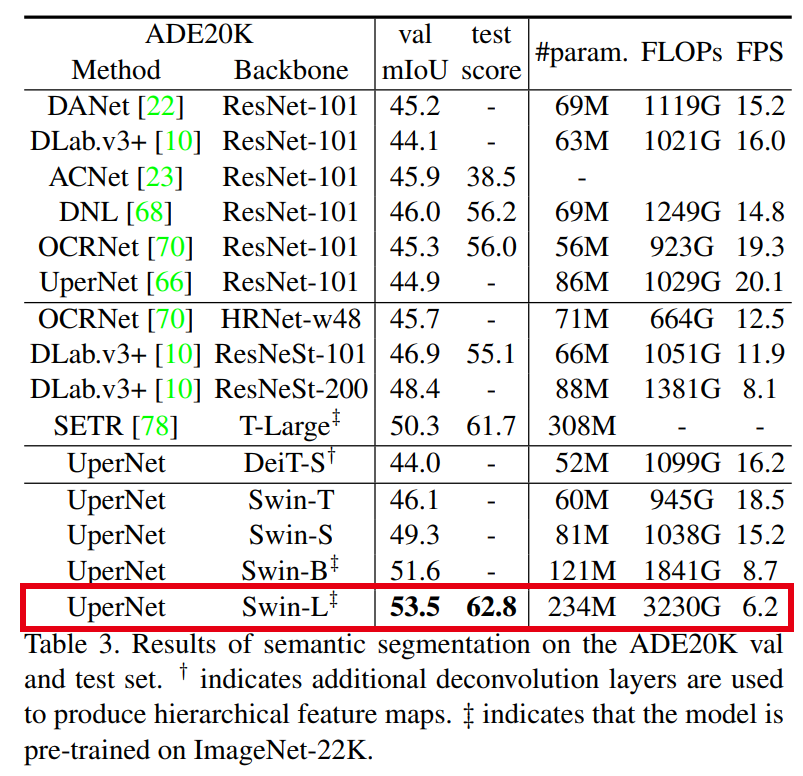
观察CVPR最新的论文有很多论文开始研究和尝试基于transformer去挖掘并提升现有工作的性能,因此,我们后续也会更加关注这方面的工作分享。如果对你有所帮助,欢迎分享给你身边的小伙伴。
CVPR2021 论文整理(附论文下载):
https://github.com/DWCTOD/CVPR2021-Papers-with-Code-Demo
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看