
使用动图深入解释微软的Swin Transformer
来源:Deephub Imba
Swin Transformer(Liu et al。,2021)是一个基于Transformer的深度学习模型,在视觉任务中取得了最先进的性能。与VIT不同Swin Transformer更加高效并且有更高的精度。由于Swin Transformer的一些特性,现在许多视觉的模型体系结构中,Swin Transformers还是被用作模型的骨干。本文旨在使用插图和动画为Swin Transformers提供全面的指南,以帮助您更好地理解这些概念。
Swin Transformer 一个改进的VIT
近年来,Transformer(Vaswani ,2017)在自然语言处理(NLP)任务中占据了深度学习体系结构。Transformer在NLP中的巨大成功激发了研究它用于其他任务的研究。
2020年,将纯粹的Transformer体系结构应用视觉任务的Vision Transformer(VIT)引起了AI社区的广泛关注。尽管有希望,但VIT并不完美,还是包含了几个缺点。这里面最严重的一个就是VIT和高分辨率图像的兼容性,因为其计算会产生与图像大小相关的二次复杂度。
VIT的一系列研究工作大多数是对标准Transformer体系结构进行了增强。2021年微软研究人员发表了Swin Transformer(Liu,2021),这可以说是原始VIT后最令人兴奋的研究之一。
Swin架构和关键概念
Swin Transformer引入了两个关键概念来解决原始ViT面临的问题——层次化特征映射和窗口注意力转换。事实上,Swin Transformer的名字来自于“Shifted window Transformer”。Swin Transformer的总体架构如下所示。
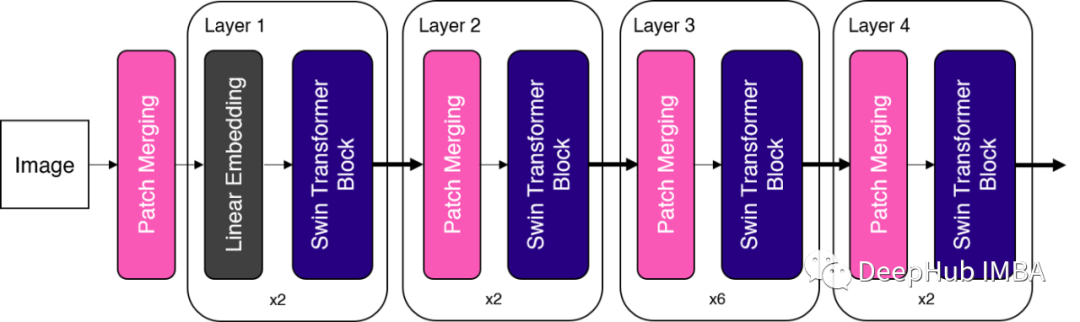
Swin Transformer总体架,' patch partition '被用作第一个块。为了简单起见,我使用“patch merging’”作为图中的第一个块,因为它们的操作类似。
正如我们所看到的,“patch merging”块和“Swin Transformer块”是Swin Transformer中的两个关键构建块。在下一节中,我们将详细介绍这两个块。
分层特征图
VIT的第一个重大区别是是Swin Transformer构建“分层特征图”。让我们将其分为两个部分
首先,“特征图”只是从每个连续层生成的中间张量。至于“分层”,在这里指的是特征映射从一层到另一层合并(下一节详细介绍),有效地降低了从一层到另一层的特征映射的空间维数(即向下采样)。
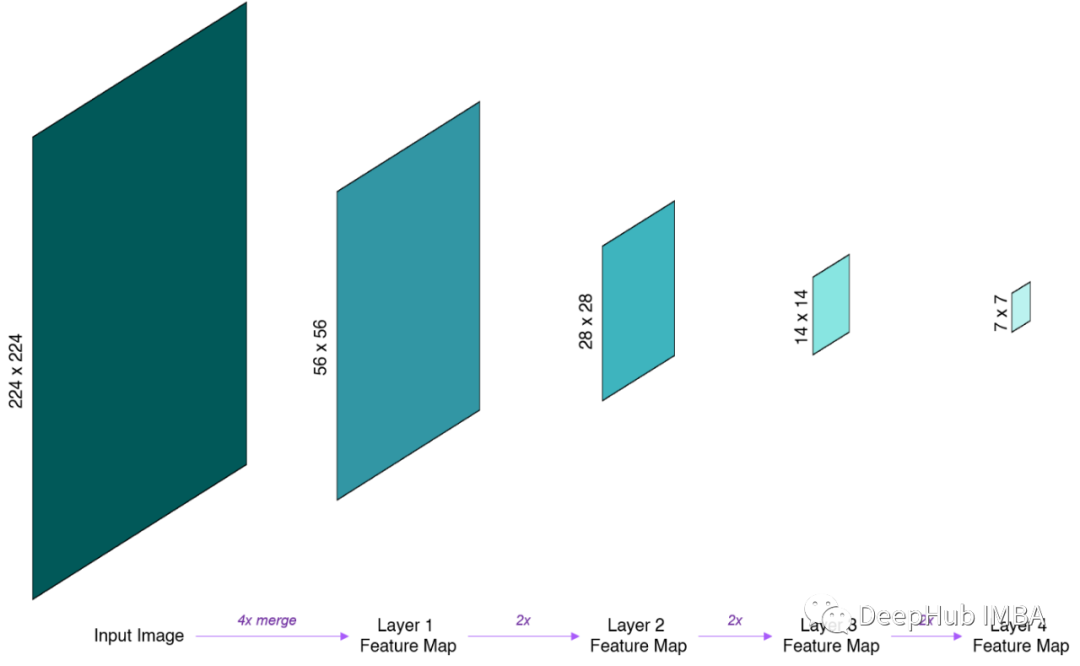
Swin Transformer中的分层特征映射。特征映射在每一层之后逐步合并和下采样,创建具有层次结构的特征映射。本图为了简单起见,省略了特性映射的深度。
可能会注意到,这些分层特征映射的空间分辨率与ResNet中的相同。因为这样做是有意的,这样Swin Transformer就可以方便地在现有的视觉任务方法中替换ResNet骨干网络。
更重要的是,这些分层的特性映射允许Swin Transformer应用于需要细粒度预测的领域,例如语义分割。而ViT在整个架构中使用单一的、低分辨率的特性图并不适应这类的任务。
Patch Merging
在前一节中,我们已经看到了如何通过逐步合并和降低特征图的空间分辨率来构建分层特征图。在ResNet等卷积神经网络中,特征映射的下采样是通过卷积操作完成的。那么在不使用卷积的情况下,我们如何对纯Transformer网络中的特征映射进行下采样呢?
Swin Transformer中使用的无卷积下采样技术被称为Patch Merging。在这种情况下,“Patch ”指的是特征图中的最小单位。换句话说,在一个14x14的feature map中,有14x14=196个Patch 。
为了对特征映射下采样n倍,patch merge将每一组n × n个相邻patch的特征连接起来。通过语言描述可能很难理解,所以我创建了一个动画来更好地说明这一点。

patch merge操作通过对nxn patch进行分组并按深度拼接,对输入的数据进行n倍的采样。
正如我们从上面的动画中看到的,补丁合并将每个nxn个相邻的patch分组,并将它们深度级联。这有效地对输入进行n倍的下采样,将输入从H x W x C的形状转换为(H/n) x (W/n) x (2nC),其中H、W和C分别表示高度、宽度和通道深度。
Swin transformer块
Swin transformer中使用的块用Window MSA (W-MSA)和shift Window MSA (SW-MSA)模块取代了ViT中使用的标准多头自注意力(MSA)模块。Swin Transformer模块如下图所示。
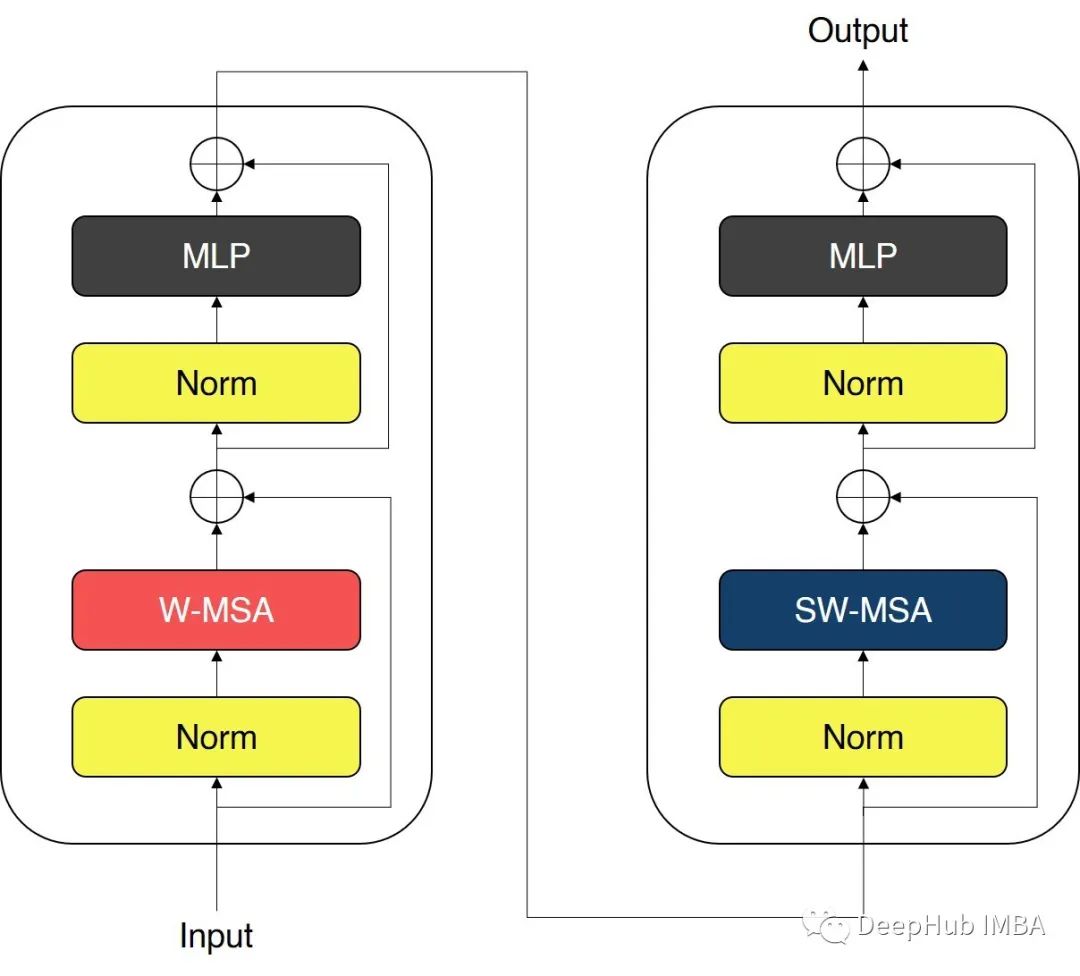
Swin transformer块有两个子单元。第一个单元使用W-MSA,第二个单元使用SW-MSA。每个子单元由一个规一化层、一个注意力模块、另一个规范化层和一个MLP层组成。第一个子单元使用Window MSA (W-MSA)模块,而第二个子单元使用移位Window MSA (SW-MSA)模块。
窗口级别的自注意力
ViT中使用的标准MSA执行全局自注意力,每个Patch之间的关系是根据所有其他Patch计算的。这会产生与Patch数量相关的二次复杂度,使它不适合高分辨率的图像。

ViT中使用的标准MSA计算
为了解决这个问题,Swin Transformer使用了基于窗口的MSA方法。窗口只是Patch的集合,注意力只在每个窗口内计算。例如下图使用的窗口大小为2 × 2 patch,基于窗口的MSA只计算每个窗口内的注意力。

Swin Transformer中使用的窗口MSA只在每个窗口内计算注意力。
由于窗口大小在整个网络中是固定的,因此基于窗口的MSA的复杂度相对于patch的数量(即图像的大小)是线性的,相对于标准MSA的二次复杂度有了很大的提高。
移动窗口Self-Attention
基于窗口的MSA的一个明显缺点是,将注意力限制在每个窗口,限制了网络的建模能力。为了解决这个问题,Swin Transformer在W-MSA模块之后使用了移位窗口MSA (SW-MSA)模块。

为了引入跨窗口连接,移位窗口MSA将窗口向右下角移动M/2,其中M是窗口大小(上面动画中的第1步)。
这种转变会导致不属于任何窗口的“孤立”patch,以及patch不完整的窗口。Swin Transformer应用了“循环移位”技术(上面动画中的第2步),它将“孤立的”patch移动到带有不完整patch的窗口中。在这次移位之后,一个窗口可能会由原始feature map中不相邻的patch组成,因此在计算过程中应用了一个mask,将自注意力限制在相邻的patch上。
这种移动窗口的方法引入了重要的窗口之间的交叉连接,可以提高网络的性能。

总结
Swin Transformer可能是继最初的Vision Transformer之后最令人兴奋的一项研究。Swin Transformer使用分层特征映射和移位窗口MSA解决了困扰原始ViT的问题。Swin Transformer在包括图像分类和目标检测在内的广泛视觉任务中通常被用作骨干架构。
作者:James Loy

喜欢就关注一下吧:
 点个 在看 你最好看!
点个 在看 你最好看!