
超越Swin,Transformer屠榜三大视觉任务!微软推出新作:Focal Self-Attention
↑ 点击蓝字 关注极市平台

作者丨小马
编辑丨极市平台
极市导读
本文提出了Focal Self-Attention,对当前token周围的区域进行细粒度的关注,对离当前token较远的区域进行粗粒度的关注,用这样的方式来更加有效的捕获局部和全局的注意力。基于FSA,作者提出了Focal Transformer,并在分类、检测、分割任务上都验证了结构的有效性。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
写在前面
VIsion Transformer(ViT)和它的一系列变种结构在CV任务中取得了不错的成绩,在其中,Self-Attention(SA)强大的建模能力起到了很大的作用。但是SA的计算复杂度是和输入数据的大小呈平方关系的,所以针对一些需要高分辨率的CV任务(e.g., 检测、分割),计算开销就会很大。目前的一些工作用了局部注意力去捕获细粒度的信息,用全局注意力去捕获粗粒度的信息,但这种操作对原始SA建模能力的影响,会导致sub-optimal的问题。因此,本文提出了Focal Self-Attention(FSA),以细粒度的方式关注离自己近的token,以粗粒度的方式关注离自己远的token,以此来更有效的捕获short-range和long-range的关系。基于FSA,作者提出了Focal Transformer,并在分类、检测、分割任务上都验证了结构的有效性。
1. 论文和代码地址
Focal Self-attention for Local-Global Interactions in Vision Transformers
论文地址:https://arxiv.org/abs/2107.00641
代码地址:未开源
核心代码:后期会复现在https://github.com/xmu-xiaoma666/External-Attention-pytorch
2. Motivation
目前,Transformer结构在CV和NLP领域都展现出了潜力。相比于CNN,Transformer结构最大的不同就是它的Self-Attention(SA)能够进行依赖内容的全局交互(global content-dependent interaction),使得Transformer能够捕获long-range和local-range的关系。
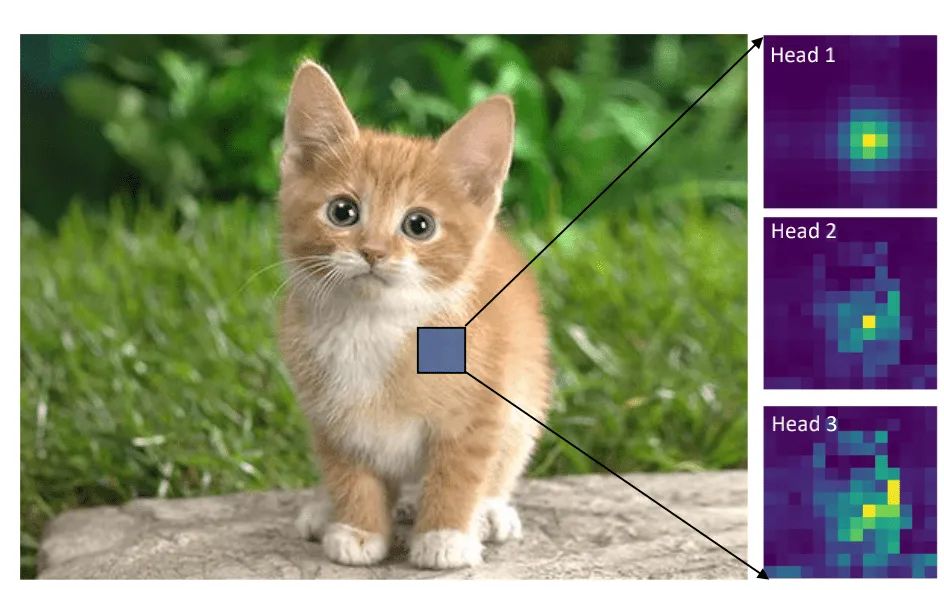
上图是DeiT-Tiny的attention可视化,可以看出,SA不仅能够像CNN那样关注局部区域,还能进行全局信息的感知。然而Transformer的计算量与输入数据的大小呈平方关系,因此对于检测、分割任务来说是非常不友好的。
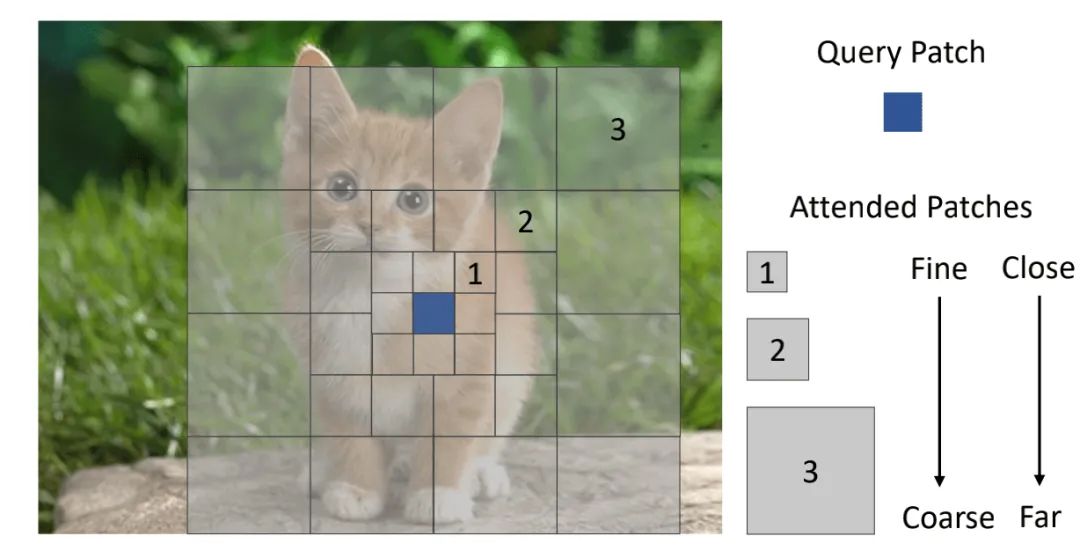
因此,本文提出了一个Focal Self-Attention(FSA),如上图所示,对当前token周围的区域进行细粒度的关注,对离当前token较远的区域进行粗粒度的关注,用这样的方式来更加有效的捕获局部和全局的注意力。基于FSA,本文提出了Focal Transformer,并在多个任务上进行了实验,取得了SOTA的性能。
3. 方法
3.1. 模型结构
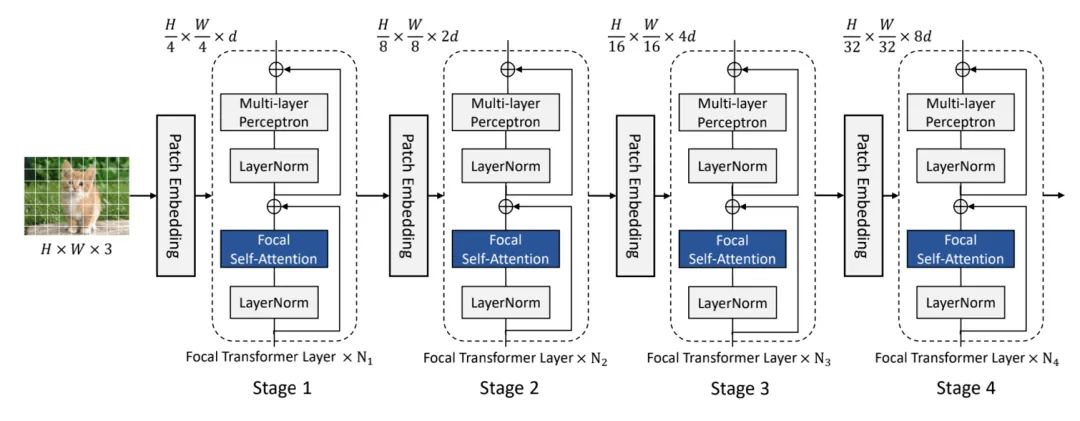
本文的模型结构如上图所示,首先将图片分成4x4的patch。然后进入Patch Embedding层,Patch Embedding层为卷积核和步长都为4的卷积。在进入N个Focal Transformer层,在每个stage中,特征的大小减半,通道维度变为原来的两倍。如果采用SA,由于这里指将图片缩小了四倍,因此第一层Transformer layer的SA计算复杂度为
,这一步是非常耗时、耗显存的。
那么,应该采用什么样的办法来减少计算量呢?原始的SA将query token和其他所有token都进行了相似度的计算,因为无差别的计算了所有token的相似度,导致这一步是非常耗时、耗显存的。但其实,对于图片的某一个点,与这个点的信息最相关的事这个点周围的信息,距离越远,这个关系应该就越小。所以作者就提出了,对于这个点周围的信息进行细粒度的关注,距离这个点越远,关注也就越粗粒度。(个人觉得这一点其实跟人眼观察的效应很像,当我们看一件物体的,我们最关注的是离这个物体更近的区域,对于远离这个物体的区域,关注程度就会更小甚至直接忽视)。
3.2. Focal Self-Attention(FSA)
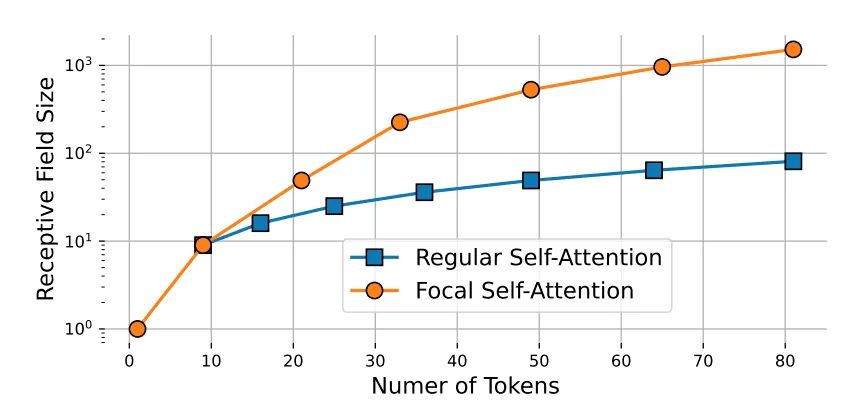
传统的SA由于对所有的token都进行细粒度的关注,因此是非常费时的;本文提出的FSA对靠近当前token的信息进行更加细粒度的关注,对远离当前token的信息进行粗粒度的关注。在论文中,粗粒度的关注指的是将多个token的信息进行聚合(也就是下面讲到的sub-window pooling),因此聚合的token越多,那么关注也就越粗粒度,在相同的代价下,FSA的感受野也就越大。下图展示了对这attended token数量的增加,SA和FSA感受野的变化:
3.3. Window-wise attention
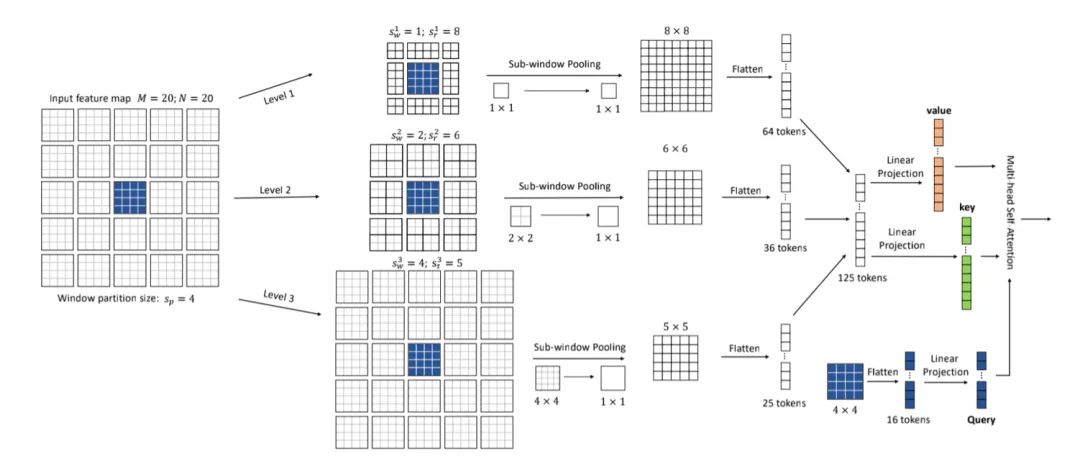
如上图所示
Focal Self-Attention的结构如上图所示,首先明确三个概念:
Focal levels
:可以表示FSA中对特征关注的细粒度程度。level L的下标越小,对特征关注也就越精细。
Focal window size
:作者将token划分成了多个sub-window,focal window size指的是每个sub-window的大小。
Focal region size
:focal region size是横向和纵向的sub-window数量。
3.3.1. Sub-window pooling
功能:
这一步的作用是用来聚合信息的,因为前面也说到了,Self-Attention是对所有的token信息都进行细粒度的关注,导致计算量非常大。所以作者就想到,能不能只对query token周围的信息进行细粒度关注,远离的query token的信息进行粗粒度的关注。那么,如何来表示这个粗粒度呢,作者就提出了sub-window pooling这个方法,将多个token的信息进行聚合,以此来减少计算量。那么,聚合的token数越多,后期attention计算需要的计算量也就越小,当然,关注的程度也就更加粗粒度。
计算流程:
每个focal level中,首先将token划分成多个
的sub-window,然后用一个线性层
进行pooling操作:
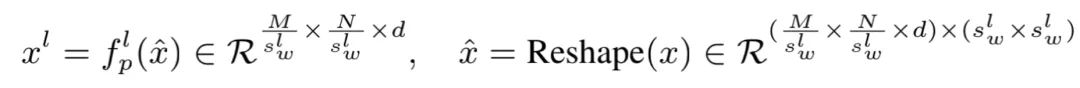
pooling后的特征提供了细粒度或者粗粒度的信息。比如,level 1的
,所以pooling并没有对特征进行降采样,所以处理之后的特征是细粒度的;同理level 2和level 3,特征分别缩小到了原来的1/2和1/4,因此越远离query token的特征,信息表示就越是粗粒度的。此外,由于
通常是比较小的,所以这一步的参数几乎是可以忽略不计的。
3.3.2. Attention computation
功能:
在上一步中,我们用sub-window pooling进行了信息聚合操作,以此来获得不同细粒度的特征。接下来,我们就需要对这些不同细粒度的信息进行attention的计算。具体的步骤其实和标准的Self-Attention很像,主要不同之处有两点1)引入了相对位置编码,来获取相对位置信息;2)每个query和所有细粒度的key和value都进行了attention的计算,因此本文方法的计算量其实还是不算小的。
计算流程:
经过sub-window pooling之后,就获得不同细粒度和感受野的特征表示。接下来这一步,我们需要对local和global的特征进行attention计算。首先,我们通过三个线性层计算当前level的Q和所有level的K、V:
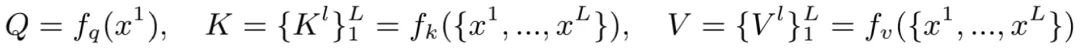
接着,我们将当前level的Q和所有level的K、V进行带相对位置编码的Self-Attention:
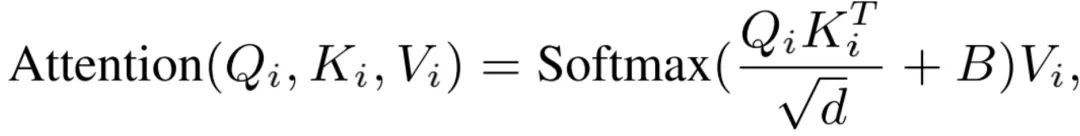
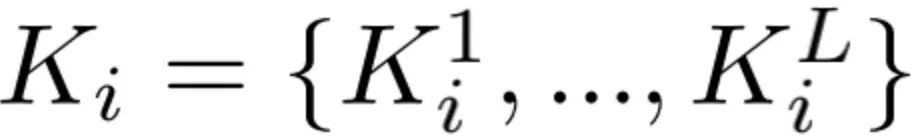
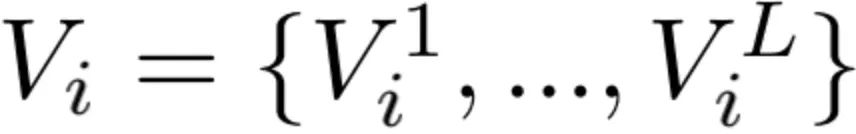
其中B是可学习的相对位置编码的参数。
3.4. Model Configuration
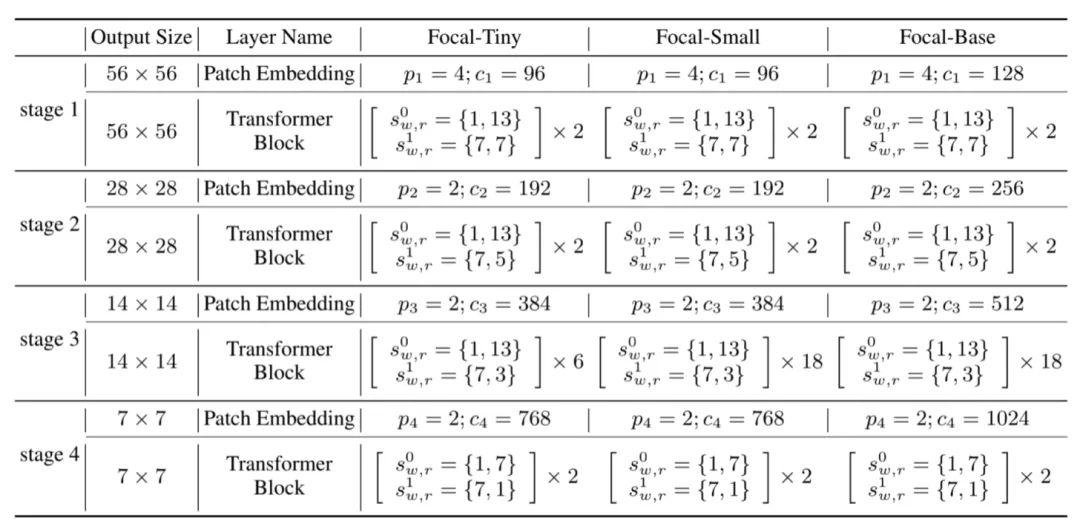
基于FSA,作者提出了三个不同大小的Focal Transformer实例,具体的参数设置如下所示。
4.实验
4.1. ImageNet上的结果
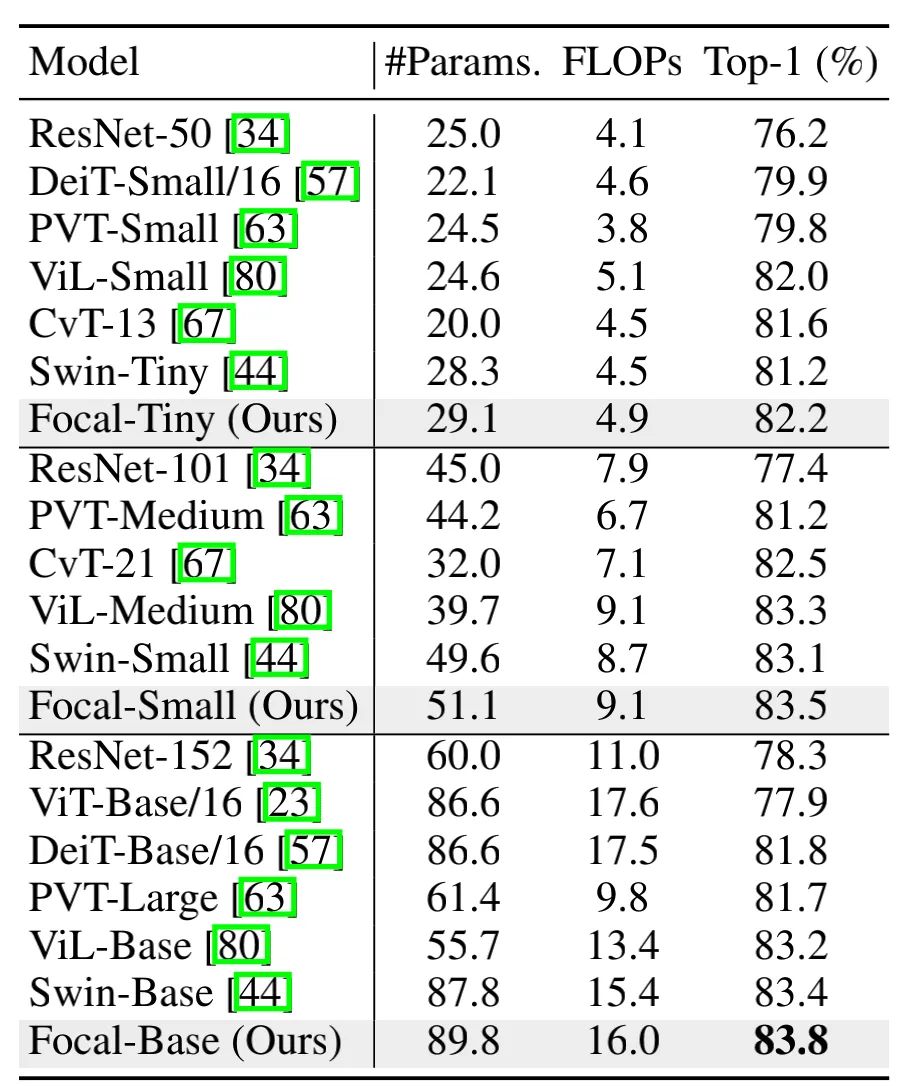
作者对比了三个Focal Transfermer实例和其他SOTA模型的对比,可以看出在参数量和计算量相当的情况下,本文的Focal Transformer确实能取得比较好的结果。
4.2. 目标检测和分割任务上的结果
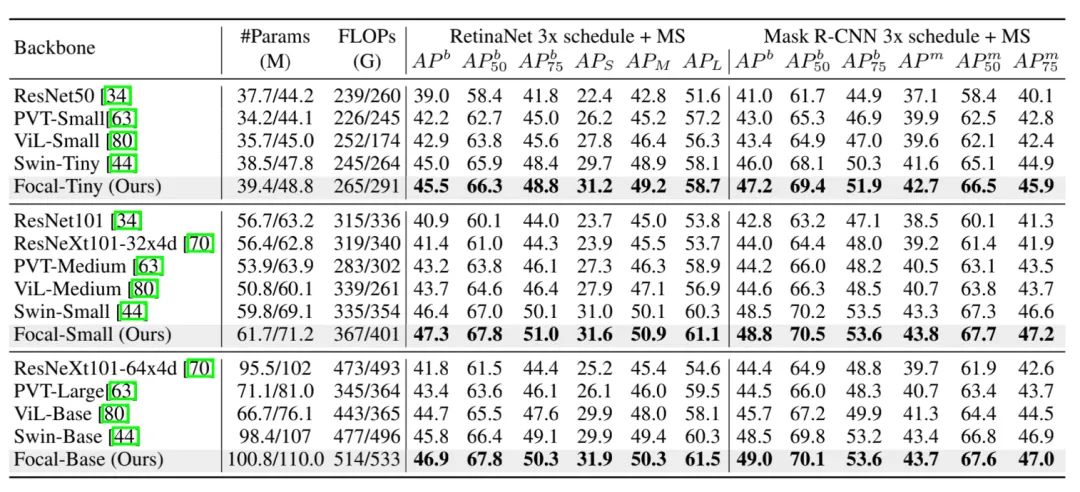
从上图中可以看出,在计算量相差不大情况下,Focal Transformer的各个指标都有明显的提升。
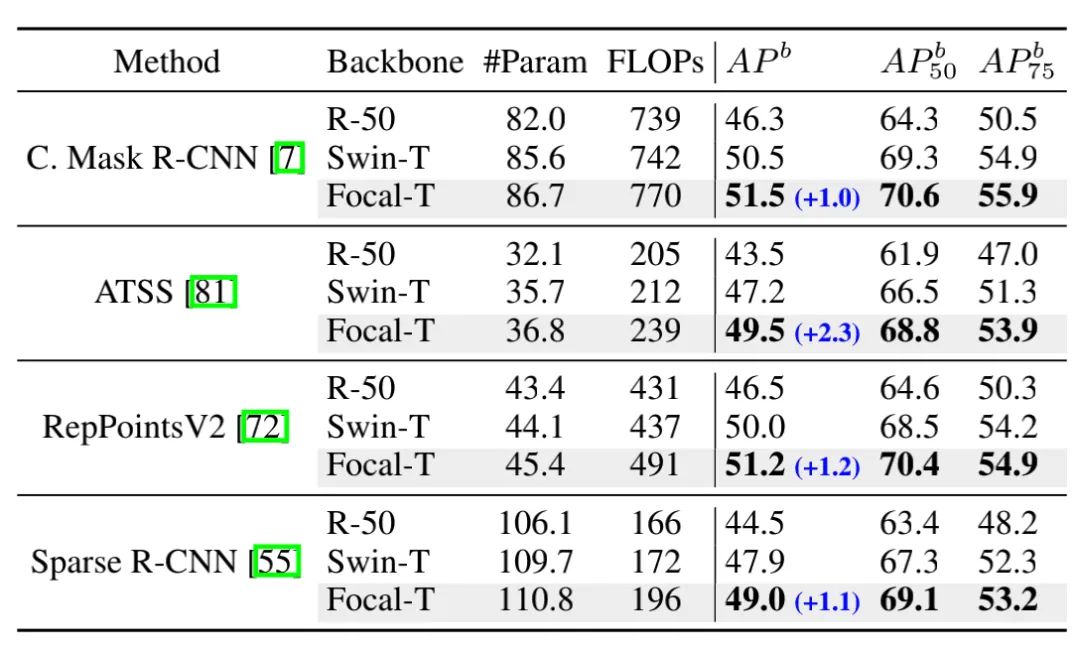
为了进行进一步的探究,作者还在不同的目标检测框架下对不同的backbone进行了实验,可以看出,focal Transformer相比于Resnet-50和Swin-Transformer都能有非常明显的性能提升。
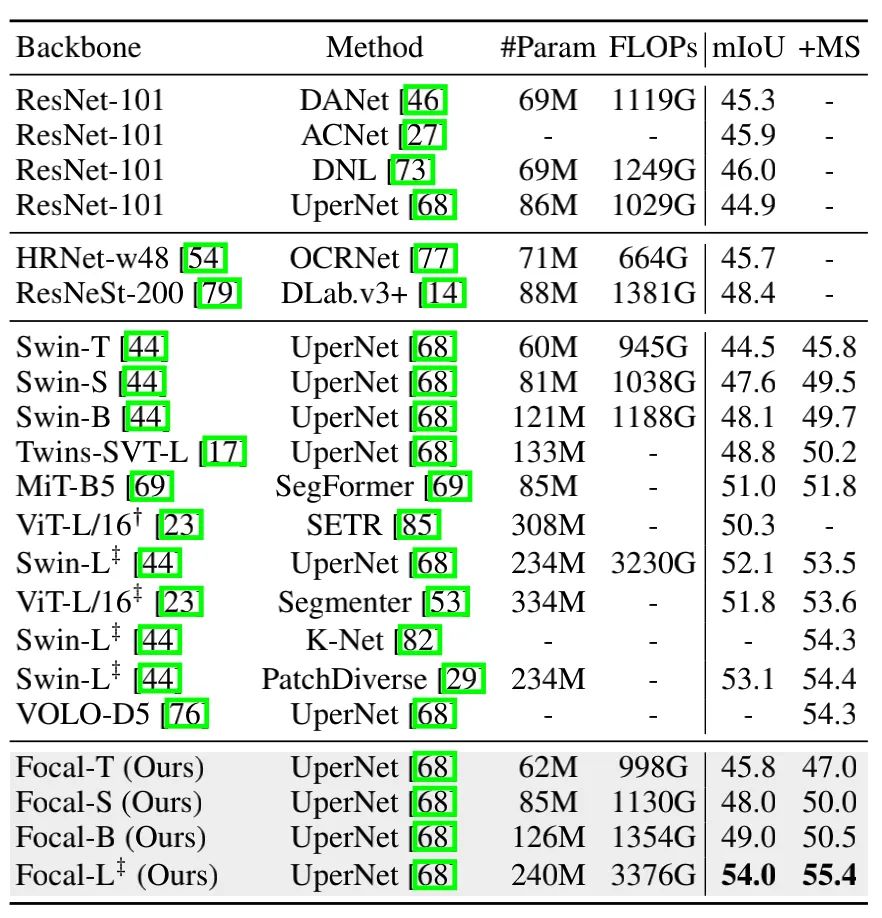
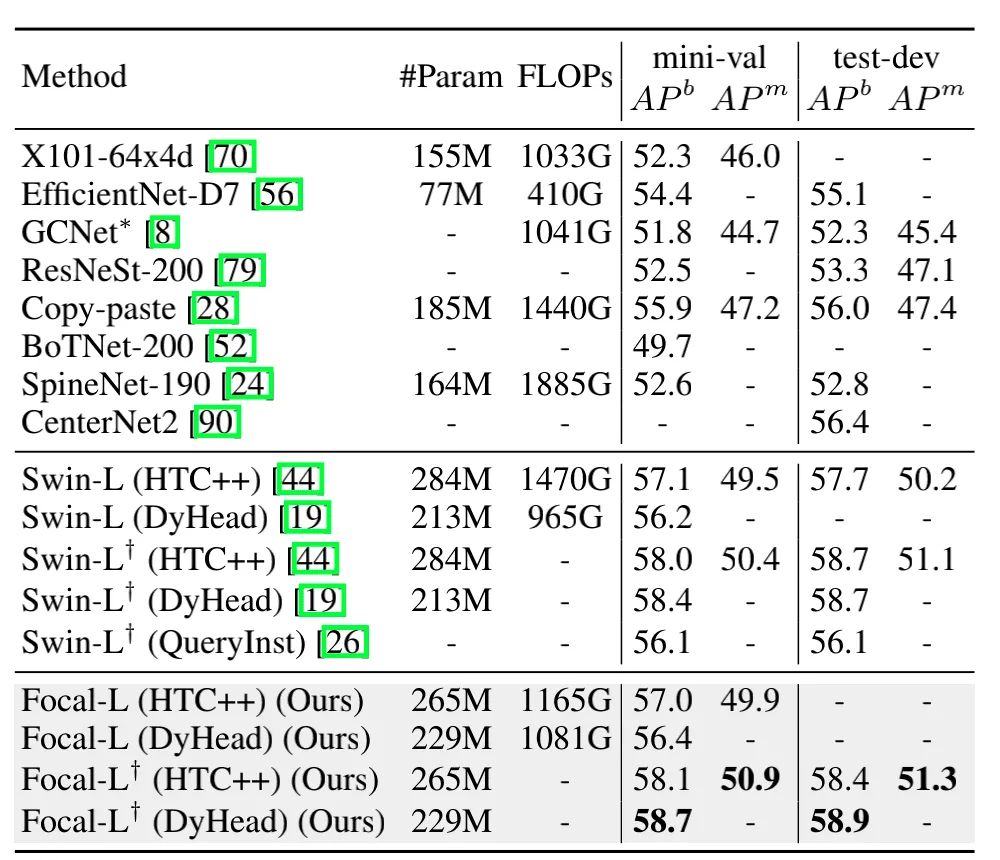
上面两张图分别展示了不同模型在ADE20K上语义分割和COCO上目标检测的结果,可以看出,本文的方法在性能上还是有很大的优越性。
4.3. 消融实验
4.3.1. 不同window size的影响
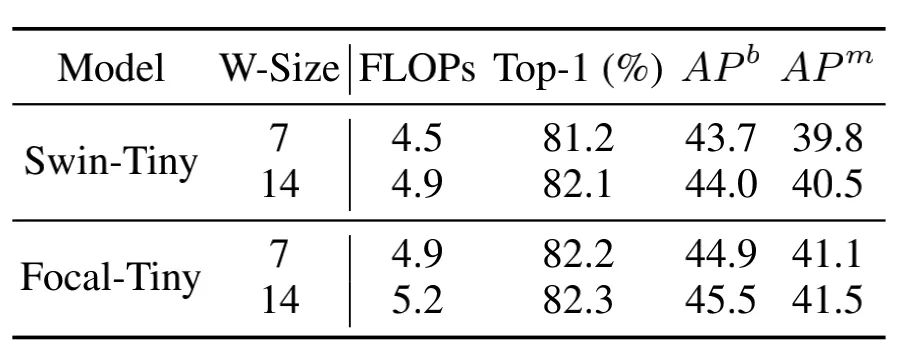
可以看出,更大的window size能够有更好的性能;在相同计算量或者window size下,Focal-Tiny的性能明显优于Swin-Tiny。
4.3.2. Window Shifting的影响
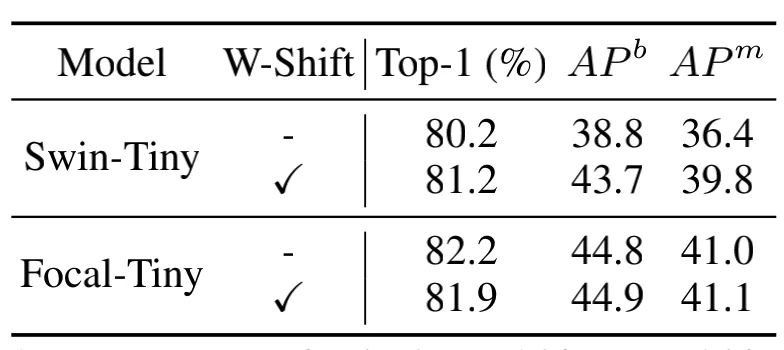
可以看出Window Shifting对于分类任务性能的提高是有反效果的;但是有利于检测、分割任务的性能提升。
4.3.3. Short-Range和Long-Range信息交互的影响
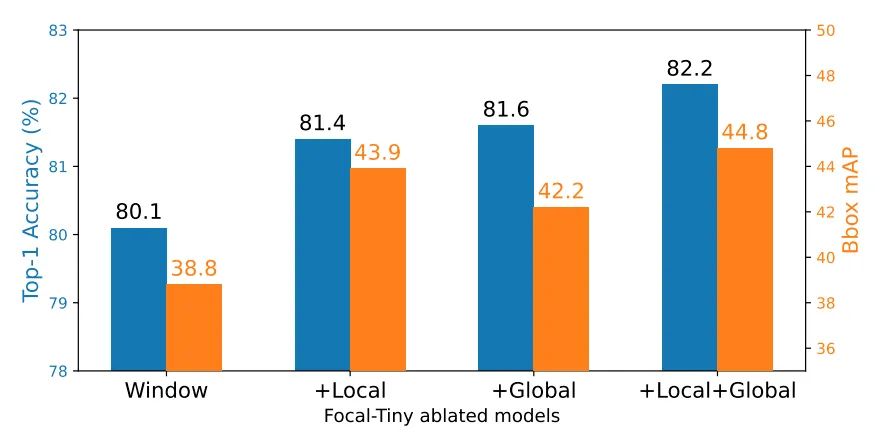
可以看出,在不同任务上,Local+Global的信息交互明显优于只有Local或者Global。
4.3.4. 模型深度的影响
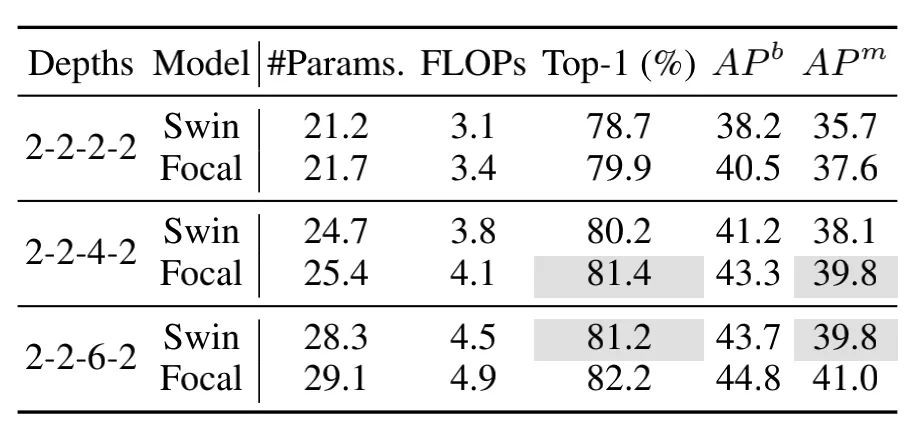
上面展示了stage3采用不同层数的实验结果,可以看出层数并不是越多越好,Focal Transformer深度为4的效果要由于深度为6。
5. 总结
本文提出了一个能够进行local-global信息交互的attention模块——Focal Self-Attention(FSA),FSA能够对相邻的特征进行细粒度的关注,对距离较远的特征进行粗粒度的关注,从而实现有效的local-global信息交互。但是FSA引入了额外的显存占用和计算量,因此虽然性能上得到了不错的提升,但是高分辨率图像的预测任务,依旧不是非常友好。
这是继VOLO、CoAtNet之后又一篇在局部信息建模上做出来的文章,这也说明了局部信息建模这个部分对于图像理解任务来说确实是非常重要的,“局部假设偏置+Transformer强大的全局建模能力”这一操作确实是非常有效的。相比于VOLO、CoAtNet,本文的方法是将局部和全局信息的建模放在一个结构中,而不是对局部和全局信息分别建模后,简单地再将局部和全局建模结构进行串联和并联。
如果觉得有用,就请分享到朋友圈吧!
△点击卡片关注极市平台,获取最新CV干货
公众号后台回复“目标跟踪”获取目标跟踪综述~
极市干货
YOLO教程:一文读懂YOLO V5 与 YOLO V4|大盘点|YOLO 系目标检测算法总览|全面解析YOLO V4网络结构
实操教程:PyTorch vs LibTorch:网络推理速度谁更快?|只用两行代码,我让Transformer推理加速了50倍|PyTorch AutoGrad C++层实现
算法技巧(trick):深度学习训练tricks总结(有实验支撑)|深度强化学习调参Tricks合集|长尾识别中的Tricks汇总(AAAI2021)
最新CV竞赛:2021 高通人工智能应用创新大赛|CVPR 2021 | Short-video Face Parsing Challenge|3D人体目标检测与行为分析竞赛开赛,奖池7万+,数据集达16671张!

# 极市原创作者激励计划 #
极市平台深耕CV开发者领域近5年,拥有一大批优质CV开发者受众,覆盖微信、知乎、B站、微博等多个渠道。通过极市平台,您的文章的观点和看法能分享至更多CV开发者,既能体现文章的价值,又能让文章在视觉圈内得到更大程度上的推广。
对于优质内容开发者,极市可推荐至国内优秀出版社合作出书,同时为开发者引荐行业大牛,组织个人分享交流会,推荐名企就业机会,打造个人品牌 IP。
投稿须知:
1.作者保证投稿作品为自己的原创作品。
2.极市平台尊重原作者署名权,并支付相应稿费。文章发布后,版权仍属于原作者。
3.原作者可以将文章发在其他平台的个人账号,但需要在文章顶部标明首发于极市平台
投稿方式:
添加小编微信Fengcall(微信号:fengcall19),备注:姓名-投稿
△长按添加极市平台小编
觉得有用麻烦给个在看啦~
