
ECCV2020 | CPNDet:Anchor-free+两阶段目标检测思想,先找关键点再分类
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

这篇文章收录于ECCV2020,是作者团队是:国科大、华为、华中科大、鹏城实验室。是一篇关于Anchor-free的两阶段目标检测网络,效果可达49.2%AP,在准确率和召回率等性能上优于CenterNet、FCOS等网络,并且模型的推理速度较快。整体的思路,可以说有一点点无聊,不过当作个水文看看还是可以的。
论文地址:https://arxiv.org/abs/2007.13816.pdf
代码地址:https://github.com/Duankaiwen/CPNDet
通常,目标检测算法的目标是确定图像中目标对象的类别和位置。本文提出了一种新颖的anchor-free两阶段框架,该框架首先通过查找可能的角点关键点组合来提取多个候选目标object proposals,然后通过独立的分类阶段为每个候选object分配一个类别标签。实验证明了这两个阶段分别是提高召回率和准确率的有效解决方案,同时这两个阶段可以集成到端到端网络中。本文的方法被称为“Corner Proposal Network (CPN)”,它具有检测各种scales尺度的目标的能力,并且还避免了被大量false-positive proposals所混淆。在MS-COCO数据集上,CPN的AP达到49.2%,在最新的目标检测方法中具有一定的竞争力。同样,CPN在AP达到41.6%/ 39.7%时有26.2 / 43.3FPS,推理速度性能同样出色。
简介
目标检测方法的两个关键点是找到具有不同几何形状的物体(即高召回率)以及为每个检测到的物体分配一个准确的标签(即高准确率)。现有的目标检测方法大致是按照如何定位物体和如何确定其类别来分类的。对于第一个问题,早期的研究工作大多是基于锚(anchor)的,即在图像平面上放置一些尺寸固定的边界框,而这种方法后来受到无锚(anchor-free)方法的挑战,该方法建议用一个或几个关键点和几何图形来描绘每个目标对象。通常,这些可能的目标对象被命名为proposals(候选目标),对于每一个目标对象,类别标签要么从之前的输出中继承,要么由为此训练的单个分类器进行验证。这就带来了所谓的两阶段和单阶段方法之间的争论,其中人们倾向于认为前者的工作速度较慢,但产生的检测精度更高。
本文为目标检测算法的设计提供了另一种观点。主要有两个论点:首先,检测方法的召回率由其定位不同几何形状的对象(特别是形状稀疏的对象)的能力决定,因此anchor-free方法(特别是对目标对象边界进行定位的方法)的召回率性能可能更好;第二,anchor-free方法经常会导致大量误报,于是可以在anchor-free方法中使用单个分类器来提高检测的准确性,见图1。因此,本文的方法继承了anchor-free和两阶段目标检测方法的优点。

图1.现有物体检测方法的典型错误。第一行:基于anchor锚的方法(如Faster R-CNN)可能难以找到具有特殊形状的物体(如尺寸非常大或长宽比极端的物体)。第二行:anchor-free方法(如CornerNet)可能会错误地将不相关的关键点归入一个物体。绿色、蓝色和红色边界框分别表示真阳性、假阳性和假阴性。
本文的方法被称为Corner Proposal Network(CPN)。它通过定位目标的左上角和右下角,然后为其分配类标签来检测目标对象。具体地,首先利用CornerNet的关键点检测方法,并进行改进,不是将关键点与关键点特征嵌入分组,而是将所有有效的Corner角点组合枚举为可能的proposals目标对象。这导致了大量的proposals,其中大多数是误报。然后,训练一个分类器,以根据相应的区域特征从不正确配对的关键点中区分出真实目标对象。分类有两个步骤,首先是一个二进制分类器,它过滤掉大部分proposals(即与目标对象不对应的proposals),然后,对筛选后的目标对象重新排序类别分数。
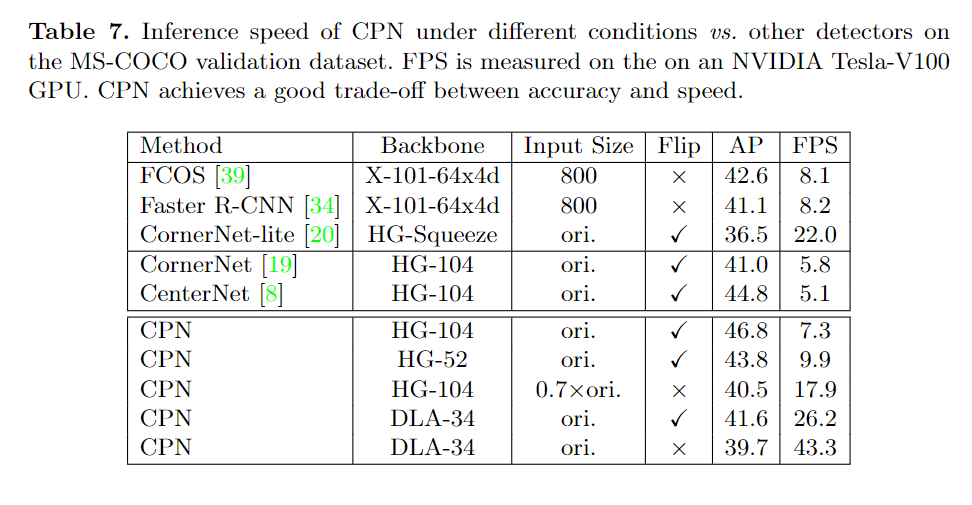
CPN的有效性已在MS-COCO数据集上得到验证,具体使用104层堆叠式Hourglass网络作为主干网络,CPN在COCO数据集上的AP为49.2%,比之前最好的anchor-free目标检测算法CenterNet 高2.2%。尤其,CPN在检测具有特殊形状(例如很大或很小的面积或极高长宽比)的物体时具有更高的精度增益,这证明了使用anchor-free方法进行proposals提取的优势。同时,CPN使用较轻的主干网络DLA-34 并在推理环节不使用图像翻转数据增强策略时,在26.2 FPS时可达到41.6% AP,在43.3FPS时达到39.7% AP,在相同的推理速度是,性能超过了大多数的目标检测算法。
本文方法:CPNDet
作者首先讨论了两个问题:使用基于anchor的方法还是不使用anchor的方法来提取候选目标proposals,以及是使用一阶段还是两阶段的方法来确定proposals的类别,并进行相关的对比实验。
1 Anchor-based or Anchor-free? One-stage or Two-stage?
首先研究anchor-based vs. anchor-free的方法。基于anchor的方法首先在图像上放置多个anchor作为候选区域,然后使用单独的分类器来判断每个候选的目标和类别。大多数情况下,每个anchor都与图像上的特定位置相关联,并且其大小是固定的,尽管bounding box的回归过程可以稍微改变其几何形状。anchor-free的方法不假定目标对象来自相对固定的几何形状的anchor,而是定位目标的一个或几个关键点,然后确定其几何形状和(或)类别。
本文的核心观点是,anchor-free方法对任意几何形状的物体的定位具有较好的灵活性,因此具有较高的召回率。这主要是由于anchor的设计大多是经验性的(例如,为了减少anchor的数量并提高效率,需要考虑常见的目标物体尺寸和形状),检测算法的灵活性较低,形状奇特的物体可能会被遗漏。典型例子如图1所示,定量研究见表1。
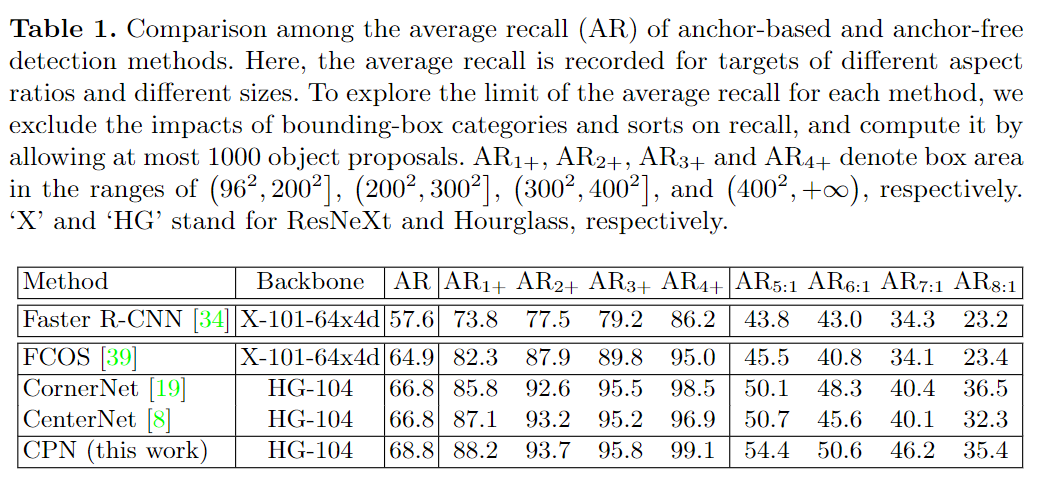
主要对四种object proposal提取方法进行了对比,并在MS-COCO验证数据集上进行了评估。结果显示,anchor-free方法通常具有更高的整体召回率,这主要是由于它们在两种情况下的优势:首先,当目标对象非常大,例如,大于4002像素时,基于anchor的方法Faster R-CNN将不会有更高的召回率。其次,当物体的长宽比变得特殊时,如5 : 1和8 : 1,Faster R-CNN的召回率非常低,在这种情况下,召回率明显低于CornerNet和CenterNet,因为没有预定义的anchor可以适应这些物体。在FCOS中也有类似的现象,FCOS是一种ancor-free的方法,它用一个关键点和到边界的距离来表示一个目标对象,但是当边界离中心很远时,FCOS通常很难预测一个准确的距离。而CornerNet和CenterNet方法将角点(和中心)关键点归为一个目标object,它们在某种程度上摆脱了这个麻烦。因此,本文的方法选择anchor方法,特别是点分组方法(CornerNet和CenterNet),以提高目标检测的召回率。同时,本文的CPN继承了CenterNet和CornerNet的优点,对物体的定位有更好的灵活性,尤其是形状奇特的物体。
然而,anchor-free方法摆脱了寻找object proposal的约束,但它遇到的一大难题是如何在关键点和目标对象之间建立紧密的关系,因为后者往往需要更丰富的语义信息。如图1所示,缺乏语义信息会导致大量的误报,从而损害检测的精度。
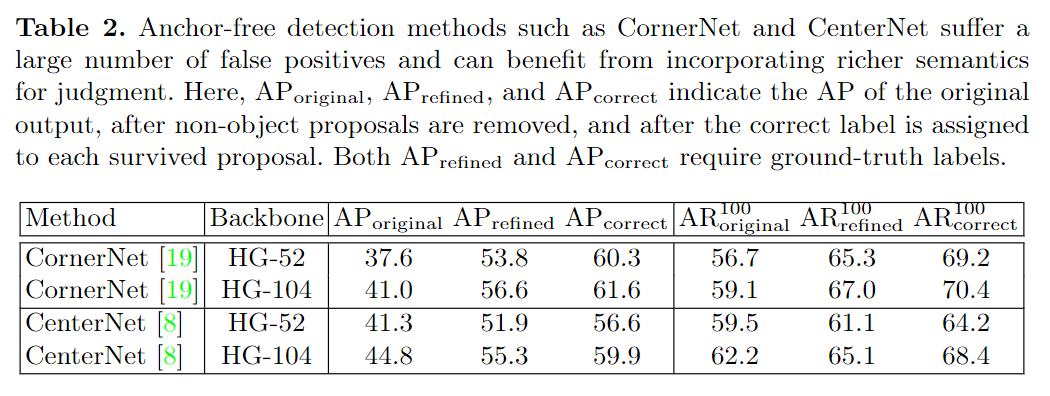
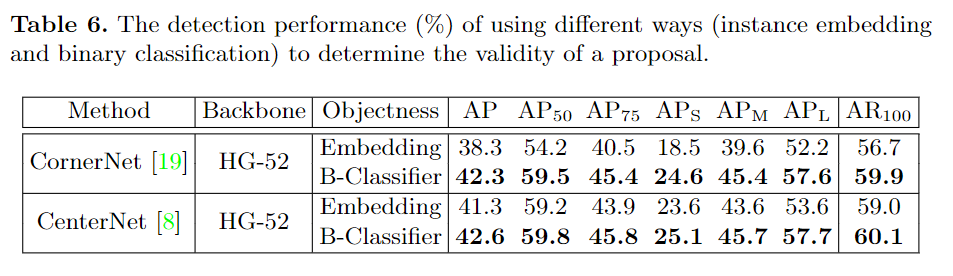
以具有高召回率的CornerNet和CenterNet为例。如表2所示,具有52层和104层Hourglass 网络的CornerNet在MS-COCO验证数据集上实现了37.6%和41.0%的AP,而很多检测到的 "目标 "都是假阳性false positives。无论是当删除object proposal,还是给每个预备的object proposal分配一个正确的标签,检测精度都会显著上升。这个结果在CenterNet上也是成立的,它增加了一个中心点来过滤掉假阳性样本,但显然没有把它们全部删除。为了进一步缓解这个问题,本文的方法需要继承两阶段方法的优点,即提取proposal内的特征,并训练一个分类器来过滤掉假阳性样本。
2 The Framework of Corner Proposal Network
基于以上分析,本文的方法旨在整合anchor-free方法的优势,并通过利用两阶段目标检测方法的区分机制来减轻其缺点。基于此,提出了一个名为Corner-Proposal-Network(CPN)的新框架。它使用anchor-free方法提取object proposal,然后进行有效的区域特征计算和分类以滤除误报。图2显示了包含两个阶段的总体流程,下面详细介绍了这两个阶段的细节。
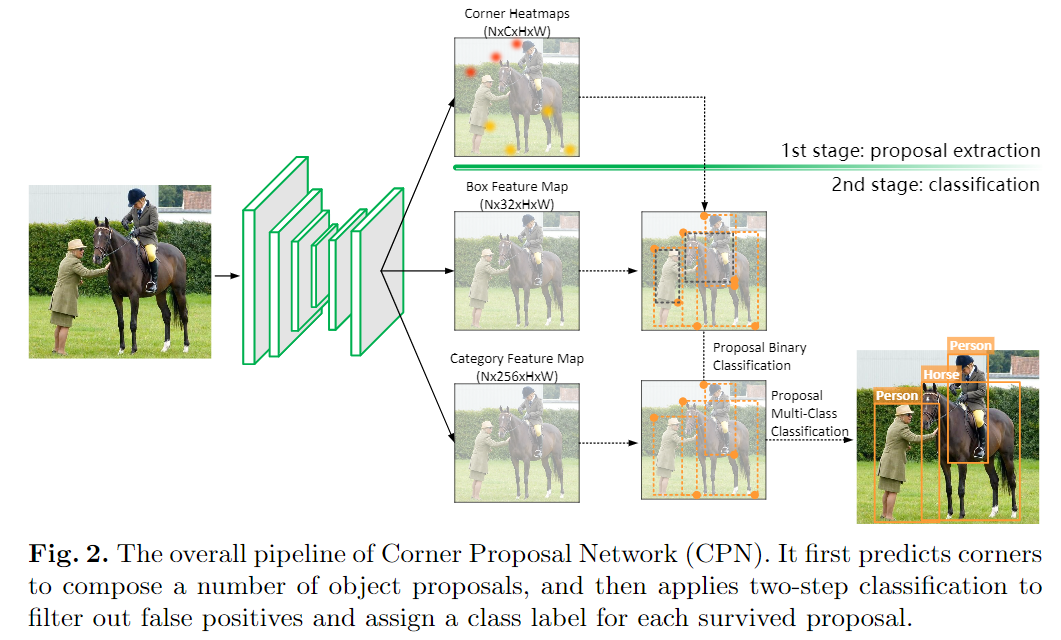
Stage 1: Anchor-free Proposals with Corner Keypoints
第一阶段是anchor-free proposals提取过程,我们假设每个目标对象由两个关键点决定其左上角和右下角的位置。具体地,采用CornerNet来定位一个目标对象,一对关键点分别位于其左上角和右下角。对于每个类,计算出两个热图heatmap(即左上角热图和右下角热图,热图上的每个值表示对应位置出现角关键点的概率),与原始图像相比,分辨率降低了4倍。heat map有两个损失项,即Focal损失用于定位热图上的关键点,以及偏移损失用于学习其与精确角位置的偏移。在计算完热图后,从所有热图中提取固定数量的关键点(K左上角和K右下角)。每个角关键点都有一个类标签。CornerNet具体解析可以参考本公众号文章:目标检测秘籍六:Anchor-free网络。
接下来,通过每个有效的关键点对来定义一个object proposal。在这里,有效的意思是指两个关键点属于同一类(即,从相同类的左上角热图和右下角热图中提取),并且左上角的x坐标小于右下角的x坐标。但,这会导致每个图像上出现大量误报(错误配对的角关键点),我们将区分和分类这些proposal的任务留给了第二阶段。
尽管本文的方法基于CornerNet来提取object proposal,但是确定目标对象及其类别等后续机制却大不相同。CornerNet通过将关键点投射到一维空间来生成目标对象,并将紧密嵌入的关键点分组到同一实例中。我们认为,embedding 过程虽然在不使用额外计算的假设下是必要的,但在配对关键点时可能会产生重大错误。特别是,不能保证embedding 函数(给每个目标对象分配一个数字)是可学习的,更重要的是,损失函数只在每个训练图像中起作用,以迫使不同目标对象的embedding number被分离,但这种机制往往不能通用于看不见的场景,例如,即使多个训练图像简单地连在一起,在单独的图像上工作良好的embedding 函数也会急剧失效。不同的是,本文的方法使用单独的分类器确定目标对象实例,从而充分利用内部特征来提高准确性。
Stage 2: Two-step Classification for Filtering Proposals
由于关键点热图的高分辨率和灵活的关键点分组机制,检测到的目标对象可以具有任意形状,并且召回率上限大大提高。但是,这种策略增加了proposal的数量,因此带来了两个问题:大量的误报以及过滤掉它们的计算成本。为解决此问题,第二阶段设计了一种有效的两步分类方法,该方法首先使用轻量级二进制分类器删除80%的proposal,然后应用细分类器确定每个幸存proposal的分类标签。
分类方法第一步:训练一个二进制分类器,以确定每个proposal是否是一个目标对象。为此,首先采用卷积核大小为7×7的RoIAlign 来提取每个proposal上的box特征(见图2)。然后使用一个32×7×7的卷积层以获得每个proposal的分类分数。基于此,构建了一个二进制分类器,损失函数为:
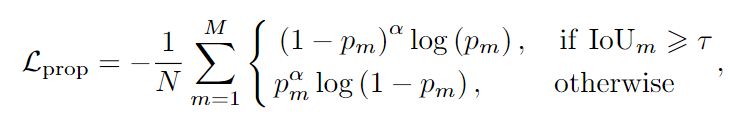
分类方法第二步:为每个存活的proposal分配一个类别标签,这一步非常重要,因为与角点关键点相关联的类标签并不总是可靠的,由于ROI区域信息的缺乏,各个角点之间的共识可能是不正确的,所以需要一个更强大的分类器,结合ROI特征来做出最终的决定。为此,在第二步提出了另一个分类器,这个分类器是建立在第一步提取的RoI Align特征的基础上,同时是从类别特征图中提取特征(见图2)以保存更多的信息,并通过256×7×7卷积层,得到一个表示类别的向量,为每一个存活的proposal建立单独的分类器。损失函数为:
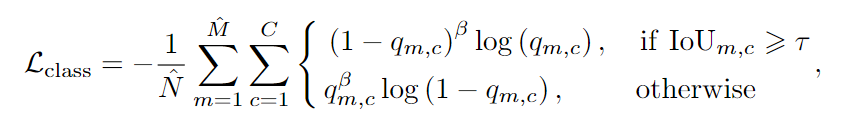
DeNet (《Denet: Scalable real-time object detection withdirected sparse sampling》)和本文的方法之间的差异,尽管它们在思想层面上是相似的。首先,本文为每个角点配备一个多类别标签而不是一个二进制标签,因此本文的方法可以依靠类别标签消除不必要的无效角点对,以节省整个框架的计算成本;其次,本文使用一种额外的轻量级二进制分类方法减少分类网络要处理的proposal数量,而DeNet仅依赖一个分类网络。最后,本文的方法为两个分类器设计了一种新的focal损失函数变体,它不同于DeNet中的最大似然函数,这主要是为了解决训练过程中正样本和负样本之间的不平衡问题。
数据集:MS-COCO dataset
评价指标:average precision (AP)、 ten IoU thresholds (i.e., 0.5 : 0.05 : 0.95)
Baseline:CornerNet and CenterNet
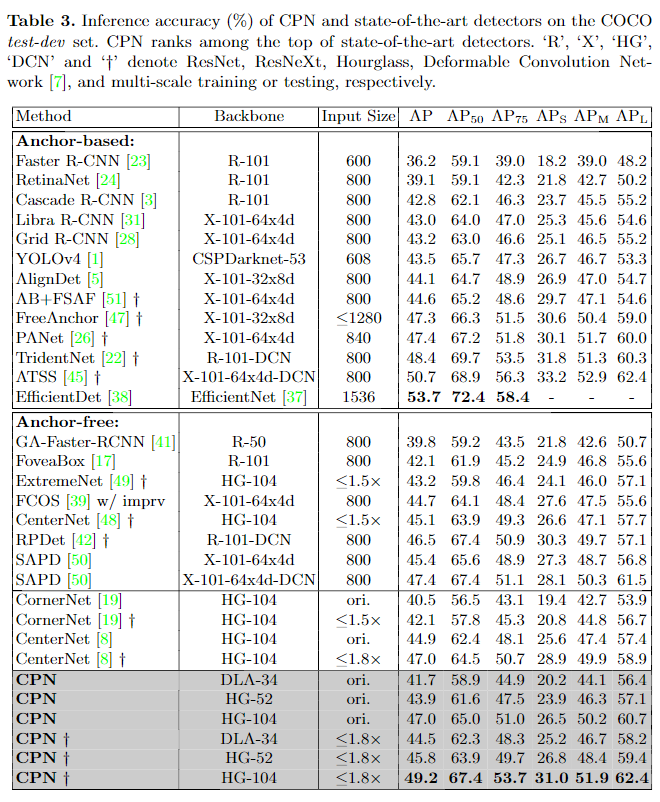
1、对比实验
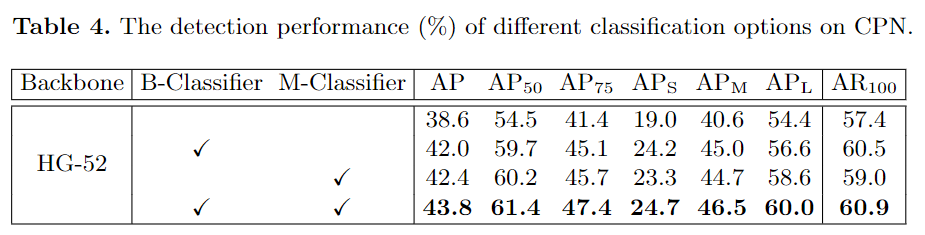
2、消融实验
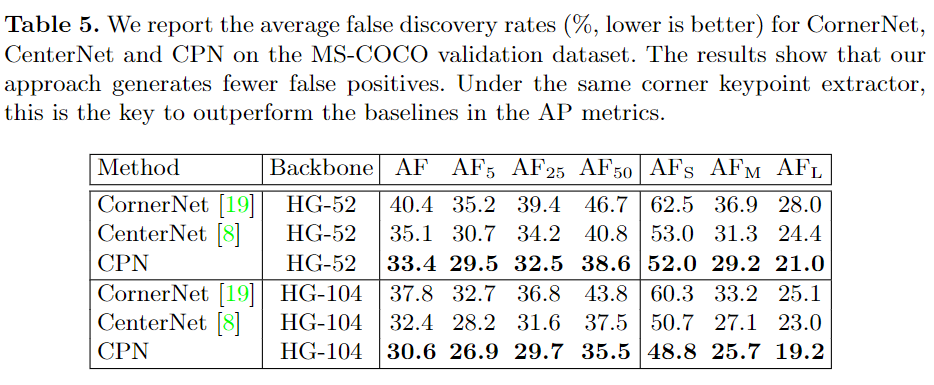
3、推理速度
4、可视化

更多细节可参考论文原文。
