
【深度学习】CornerNet: 将目标检测问题视作关键点检测与配对
前言:
CornerNet于2019年3月份提出,CW近期回顾了下这个在当时引起不少关注的目标检测模型,它的亮点在于提出了一套新的方法论——将目标检测转化为对物体成对关键点(角点)的检测。通过将目标物体视作成对的关键点,其不需要在图像上铺设先验锚框(anchor),可谓实实在在的anchor-free,这也减少了整体框架中人工设计(handcraft)的成分。

为了让自己的梳理工作更好地反馈到自身以实现内化,CW决定在此记录下自己对CornerNet的理解,同时也和大家进行分享,如果有幸能够帮助到你们,那我就更是happy了!
本文内容有些长,但是如果你打算认真回顾和思考有关CornerNet技术原理的细节,不妨耐心地看下去。CW也将本文的目录列出来了,大家也可根据自身需求节选部分内容来看。(见文末)
研究动机及背景
作者发现,目标检测中anchor-based方法存在以下问题:
1.为了给gt提供正样本,需要密集铺设多尺度的anchors,但这同时会造成正负样本不均衡;
2.anchor的存在就势必引入众多handcraft成分,如anchor数量、尺度、长宽比等,模型的训练效果极大地受到这些因素的影响,另外还会影响模型推断速度;
概述
● 通过预测得到的热图(heatmaps)来判别各位置是否属于角点;
● 基于预测的角点嵌入向量(embeddings)来对角点进行配对(属于同一物体的一对角点的embeddings之间的距离会比较小,属于不同物体的则比较大),从而判断哪些左上角点和右下角点是属于同一物体的;
● 使用预测的偏移量(offsets)对角点位置进行调整;
整体框架

最后,将池化特征分别输入到3个不同的卷积模块来预测heatmaps、embeddings以及offsets。
角点检测
检测包括分类+定位,这里主要是分类,即判断特征图上的各个(特征点)位置是否属于角点,不需要显式回归角点的位置,角点的位置基本由特征点的位置决定,然后通过预测的offsets进行调整。
● Heatmaps
分类基于两组heatmaps,分别用于左上角和右下角的判断。每组heatmap的shape是![]() ,是物体类别数(不含背景),
,是物体类别数(不含背景),![]() 是特征图的尺寸。这样,每个通道就对应特定类别物体的角点判断。理想状态下,它是一个二值mask,值为1就代表该位置属于角点,而通常模型预测出来每个位置上的值是0~1,代表该位置属于角点的置信度。
是特征图的尺寸。这样,每个通道就对应特定类别物体的角点判断。理想状态下,它是一个二值mask,值为1就代表该位置属于角点,而通常模型预测出来每个位置上的值是0~1,代表该位置属于角点的置信度。
● Penalty Reduction
由此可知,对于每个角点,只有1个正样本位置。那么训练时,1个gt在heatmap上的标签就只有在其对应的位置上值为1,其余均为0。不知你有没feel到,这样的话,很容易由于正样本过少而导致低召回率。在实际情况中,即使我们选择一对与gt角点有一定程度偏离的角点来形成预测框,那么它也有可能与gt box有较高的重叠度(IoU),这样的预测框作为检测结果也是不错的选择(如下图,红框是gt bboxes,绿框是距离gt角点较近的角点对形成的bboxes)。

于是,对于那些距离gt角点位置较近的负样本位置,我们可以“在心里暗暗地将它们也作为候选的正样本”,转化到数学形式上,就是在计算loss时减低对它们的惩罚度,惩罚度与它们距离gt角点的远近相关(gt角点 to 负样本:你离我越近,我对你越温柔~)。

以上x,y代表负样本位置与gt角点位置的横、纵坐标之差,i,j是特征点的位置,![]() 起到控制惩罚度严厉程度(变化快慢)的作用,值越大,惩罚越轻(可联想到高斯曲线越扁平)。你看看,这就是CornerNet对这批“候选正样本”的爱~
起到控制惩罚度严厉程度(变化快慢)的作用,值越大,惩罚越轻(可联想到高斯曲线越扁平)。你看看,这就是CornerNet对这批“候选正样本”的爱~
 代表模型预测的heatmap中位置
代表模型预测的heatmap中位置![]() 属于类别 C 物体角点的置信度,
属于类别 C 物体角点的置信度,![]() 。由上式可知,红色框部分就可以达到降低距离gt角点较近的那些负样本惩罚度的效果。而对于那些远离gt角点的负样本,它们对应的标签值依然是0,因此不受影响。
。由上式可知,红色框部分就可以达到降低距离gt角点较近的那些负样本惩罚度的效果。而对于那些远离gt角点的负样本,它们对应的标签值依然是0,因此不受影响。
CornerNet告诉我们,许多事情不是非正即负、非0即1,世界本就是混沌。做人也一样,不能太死板,对待他人要理解与包容,适当的宽容能够在生活中获取小确幸(说不定还有大确幸呢)。
● Radius Computation
以上只谈到对于距离gt角点在半径为的圆内的那些负样本“给予适当的宽容”,但并未说明半径如何计算,不急,因为要解方程式,可以先喝杯咖啡,休息下。

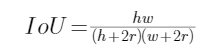
移项,整理得二元一次方程式:
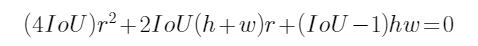
还记得根的判别式因子吗?其各项依次为:
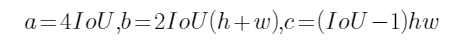
易知判别式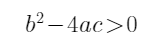 (因为
(因为![]() 所以),于是有解:
所以),于是有解:
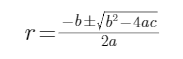
但是,我们需要的半径应该是正根,于是最终:
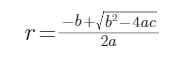

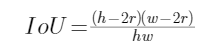
移项整理得:
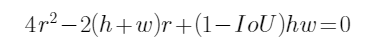
此时,根的判别式因子:
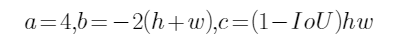
判别式:
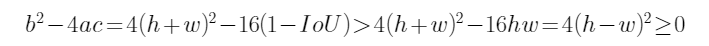
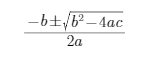 都是正根。为了兼容其它情况,我们需要取小的根,即
都是正根。为了兼容其它情况,我们需要取小的根,即 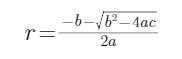

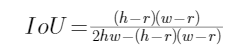
移项整理得:
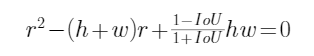
根的判别式因子:
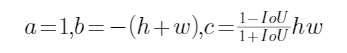
易证判别式![]() (请让CW偷下懒..),最终取较小的根:
(请让CW偷下懒..),最终取较小的根:
以上3种情况都是根据求根公式计算出对应的半径值![]() ,在实现时,将
,在实现时,将![]() 代入计算。为了兼容各种情况,最终r的取值需要是三个解中的最小值:
代入计算。为了兼容各种情况,最终r的取值需要是三个解中的最小值:
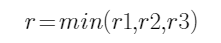
为了缓解这一现象,在训练时,计算gt角点位置映射到特征图位置时的量化误差,将其作为offsets的训练标签:

训练模型让其学会预测这个误差值,以便在最终检测时重新调整预测的角点位置。使用smooth-l1 loss对这部分进行学习:
训练完毕后,在测试时,就可以这样调整预测的角点位置(实际实现时并非这样,这里仅仅打个简单的比方):
假设在heatmap上位置![]() 被预测为角点,其对应预测的offsets为
被预测为角点,其对应预测的offsets为![]() ,那么其映射到原图上的位置就是:
,那么其映射到原图上的位置就是:
![]()
角点配对
在特征图的每个位置上,模型还会预测角点对应的嵌入向量(embeddings),用于将左上角点和右下角点进行配对。能否匹配成一对主要是由embeddings之间的距离来决定的(当然,其实还有其它条件,如预测的角点必须属于相同类别、右下角点的坐标必须大于左上角点的坐标)。理想状态下,同一物体的一对角点对应的embeddings之间的距离较小,而不同物体的则较大。那么,如何实现这一目标呢?
在训练时,CornerNet使用'pull loss'来拉近属于同一物体的角点的embeddings,同时使用'push loss'来远离属于不同物体的角点的embeddings:

其中![]() 分别为目标物体 K 的左上角和右下角对应的embeddings,则是两者的均值,delta=1,代表不同物体的角点对应的embeddings之间的margin下限(to
分别为目标物体 K 的左上角和右下角对应的embeddings,则是两者的均值,delta=1,代表不同物体的角点对应的embeddings之间的margin下限(to![]() :我们不熟,别靠太近,保持1米以外的文明距离)。 N 是目标物体的数量,也就是说,仅对gt角点位置对应的预测embeddings计算这些损失。
:我们不熟,别靠太近,保持1米以外的文明距离)。 N 是目标物体的数量,也就是说,仅对gt角点位置对应的预测embeddings计算这些损失。
Corner Pooling
由于实际生活中许多物体并没有角状,比如圆形的餐盘、条形的绳子等,因此并没有直观明显的视觉特征来表征角点。这也就是说,通过现有的视觉滤波器(卷积层、池化层等)去捕捉图像的局部特征来检测角点,效果并不会太好。比如以下这些情况,物体的左上角和右下角点处并不存在物体本身的部分,即这些角点的位置本身并不存在物体的特征。

基于这种思想,作者提出了Corner Pooling,分别对用于收集左上角点特征和右下角点特征。对于左上角点,其处理如下:

其中![]() 分别表示池化层的输入特征图,它们的目标是分别将竖直方向和水平方向的特征不断汇集到上方和左方。这样,在
分别表示池化层的输入特征图,它们的目标是分别将竖直方向和水平方向的特征不断汇集到上方和左方。这样,在![]() 中的左上角点就分别拥有了竖直方向和水平方向的极大值特征,分别代表
中的左上角点就分别拥有了竖直方向和水平方向的极大值特征,分别代表![]() 中位置
中位置![]() 的特征值。
的特征值。
最终,将![]() 进行element-wise add得到输出特征图,于是,在其中的左上角点处就拥有了竖直加水平方向的极大值特征。
进行element-wise add得到输出特征图,于是,在其中的左上角点处就拥有了竖直加水平方向的极大值特征。

对于右下角点的处理也是同样道理,经Corner Pooling处理后,会在输出特征图的右下角点处汇聚到竖直和水平方向的极大值特征。
训练
网络模型在基于Pytorch的默认方式下进行随机初始化,并且没有在额外的数据集上预训练。
训练损失最终的形式为:

其中![]()
作者在训练时还添加了中间监督。前文提到过,backbone是两个相同结构的Hourglass Networks串联而成,中间监督的意思就是对第一个Hourglass Network的输出预测也实行监督。具体来说,就是将第一个Hourglass Network的输出特征图也输入到后面的预测模块:先经过corner pooling池化,然后分别输入到不同的卷积模块分别预测heatmaps、embeddings和offsets,对这部分的预测结果也计算损失进行训练。
那么可能有帅哥/靓女会疑问:那第二个Hourglass Network的输入是什么呢?
测试

● 测试图像处理
测试时对图像的处理方式还蛮有“个性”,作者在paper中一笔带过:
Instead of resizing an image to a fixed size, we maintain the original resolution of the image and pad it with zeros before feeding it to CornerNet.
意思是,不改变图像分辨率,但使用0填充。但是,具体怎么做的,填充多少部分却没有详细说明(能不能坦诚相对..)。CW对这实在不能忍,看了源码后,发现是这样做的:

代码中 ' | 127 ' 这种方式会将new height和new width的低7位全部置1,猜测作者这样做的意思应该是想使得输入图像的尺寸至少为128x128吧(联想到CornerNet训练时输入分辨率是511x511,输出特征图分辨率正好是128x128)。
最后,将原图裁剪下来放置在填充的全0图像中,保持中心对齐,同时会记录原图在这个填充图像中的区域边界:![]() ,以便后续将检测结果还原到原图坐标空间。也就是说,在网络输入图像中,区域边界以外的部分都是0。
,以便后续将检测结果还原到原图坐标空间。也就是说,在网络输入图像中,区域边界以外的部分都是0。
另外,对于每张图片,还会将其水平镜像图片也一并输入到网络中(组成一个batch)进行测试,最终的检测结果是综合原图和镜像图片的结果。
OK,再来说说后处理过程,看是如何得到最终检测结果的。
1. 首先,对heatmaps使用kernel大小为3×3的最大池化层(pad=1),输出分辨率维持不变。将池化后的heatmaps与原heatmaps作比较,于是可以知道,值改变了的位置就是非极大值位置,将这些位置的值(即置信度)置0,那么这些位置在后续就不可能作为可能的角点位置了,这样起到了抑制非极大值的作用(paper中称为NMS,但其实和目标检测常用的NMS有所区别,这里特别说明下);
2. 然后,从heatmaps中根据置信度选择top100个左上角和右下角位置(在所有分类下进行,不区分类别),并且根据对应位置预测的offsets来调整角点位置;
3. 接着,计算左上角和右下角(每个左上角都和其余99个右下角)位置对应预测的embeddings之间的距离,距离大于0.5的、属于不同类别的、坐标关系不满足(右下角坐标需大于左上角)的角点对就不能匹配成一对;
4. 紧接着,角点已经完成配对,再次根据每对角点的平均置信度(得分)选出top100对,同时它们的平均得分作为各目标的检测分数;
实验分析
CornerNet同时输出热图、嵌入和偏移,所有这些结果都会影响检测性能。比如:热图中漏检了任何一个角点就会丢失一个目标、不正确的嵌入将导致许多错误的边界框、预测的偏移不正确则严重影响边界框的定位。
为了理解每个部件对最终的误差有多大程度的影响,作者通过将预测的热图和偏移替换为gt,并在验证集上评估性能,以此来进行误差分析:
● 对负样本位置的惩罚度降低

思考
最后,CW谈谈值得思考的几个点:
参考链接:
https://arxiv.org/abs/1808.01244
作者简介
CW,毕业于中山大学(SYSU)数据科学与计算机学院,就职于腾讯技术工程与事业群(TEG)从事Devops工作,曾在AI LAB实习,实操过道路交通元素与医疗病例图像分割、视频实时人脸检测与表情识别、OCR等项目。
往期精彩回顾
本站qq群851320808,加入微信群请扫码: