SSD目标检测算法必须知道的几个关键点
❝上期一起学了
❞SSD算法的框架流程,如下:
目标检测算法SSD结构详解
今天我们一起学下成功训练SSD算法的一些注意点:
Loss计算 Match策略 数据增强 性能分析
Loss计算
SSD算法的目标函数分两部分:计算相应的预选框与目标类别的confidence loss以及相应的位置回归。如下公式:
其中N是match到Ground Truth的预选框数量(具体的match策略下面讲),参数用于调整confidence loss和location loss之间的比例,默认.
其中confidence loss具体如下:
其中i表示第i个预选框,j表示第j个真实框,p表示第p个类别。其中表示第i个预选框是否匹配到了第j个类别为p的真实框,匹配到就为1,否则为0。
而我们在最小化上面代价函数的时候,就是将逼近于1的过程。而对于location loss,如下:
其实,位置回归的loss是跟前面学的Faster RCNN中位置回归损失是一样,不在赘述,如下:
目标检测算法Faster RCNN的损失函数以及如何训练?
其中,
g:ground truth boxl:predicted boxd:prior boxw:widthh:heigth
Match策略
在训练时,ground truth boxes与prior boxes按照如下方式进行配对:首先,寻找与每一个ground truth box有最大交并比(IoU)的prior box,这样就能保证每一个真实标注框与至少会有一个预选框与之对应,之后又将剩余还没有配对到的预选框与任意一个真实标注框尝试配对,只要两者之间的IoU大于阈值,则认为match上了。显然在训练的时候,配对到真实标注框的预选框就是正样本,而没有配对上的则为负样本。如下图: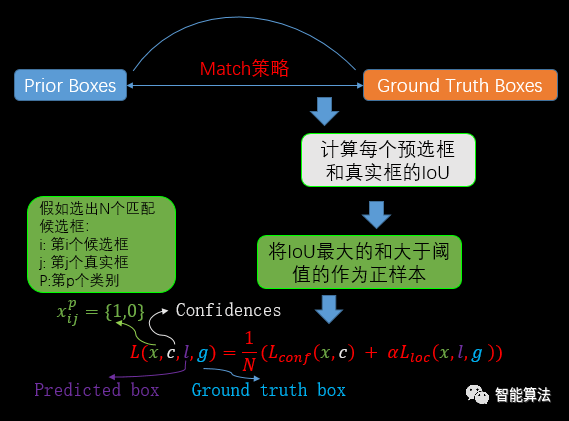 在进行
在进行match的时候,首先计算每个预选框和真实框的IoU,将IoU最大的预选框和大于阈值的预选框作为正样本,其余的作为负样本进行分类器训练。其中公式中的x表示预选框信息,c为置信度,l为预测框,g为真实标注。
数据增强
值得注意的是,一般情况下负样本预选框的数量是远远大于正样本预选框的数量,如果直接进行训练的话,会导致网络过于重视负样本,从而导致loss不稳定。所以SSD在抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差较大的top-k作为训练的负样本,控制正负样本比例为1:3,这样可以导致模型更快的优化和更稳定的训练。
另外为了使模型对于各种输入对象大小和形状更加鲁棒,每个训练图像通过以下选项之一进行随机采样:
使用整个原始输入图像 采样一个区域,使得采样区域和原始图片最小的交并比重叠为 0.1,0.3,0.5,0.7或0.9.随机采样一个区域
每个采样区域的大小为原始图像大小的[0.1,1],长宽比在1/2和2之间。如果真实标签框中心在采样区域内,则保留两者重叠部分作为新图片的真实标注。在上述采样步骤之后,将每个采样区域大小调整为固定大小,并以0.5的概率水平翻转。如下图: 上图左图为输入图片及真实标注,右侧的
上图左图为输入图片及真实标注,右侧的a,b,c,d为随机采样得到的4张图片及标注。
性能分析
SSD算法和我们前面学的Faster RCNN以及后面要学的YOLO的性能对比如下表: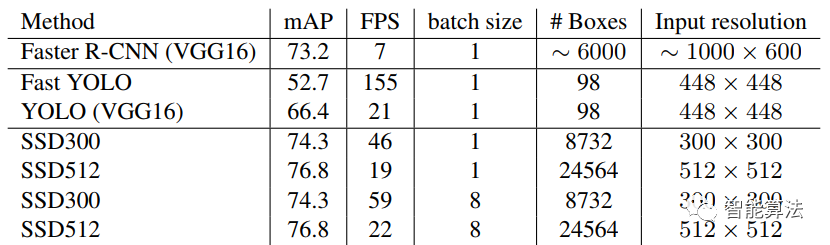 从上表中可以看到
从上表中可以看到SSD算法相比Faster RCNN和YOLO都有较高的mAP,FPS也比Faster RCNN高。而由于SSD512输入图片比300大,所以SSD512相对于SSD300有更好的mAP。
SSD缺点
需要人工设置预选框的 min-size,max_size和aspect_ratio值。网络中预选框的基础大小和形状需要手工设置。而网络中每一层feature使用的预选框大小和形状不一样,导致调试过程非常依赖经验。虽然采用了特征金字塔的思路,但是对小目标的识别效果依然一般,可能是因为 SSD使用了VGG16中的conv4_3低级feature去检测小目标,而低级特征卷积层数少,存在特征提取不充分的问题。
至此结果上期,我们基本上了解了SSD算法的大致原理,下期,我们一起看下另一个牛哄哄的检测算法YOLO,一起加油!