
手指关键点检测论文复现

一、模型介绍
这是一篇来自华工的团队发表的关于手指关键点检测的论文,论文虽然旧,但是复现效果并没有论文中展示的这么好,因为很多实验细节论文中并没有提到,这是让我觉得很尴尬的地方。
论文的整体读下来思路非常简单,毕竟是15年的论文。论文通过构建两个CNN模型,第一个CNN模型用于大致定位关键部位,然后截取出该关键部位送到第二个CNN模型进行关键点检测(指尖点和关节点)。两个CNN并没有端对端训练,而是分开训练,这也是导致最终推断效果不好的原因之一。
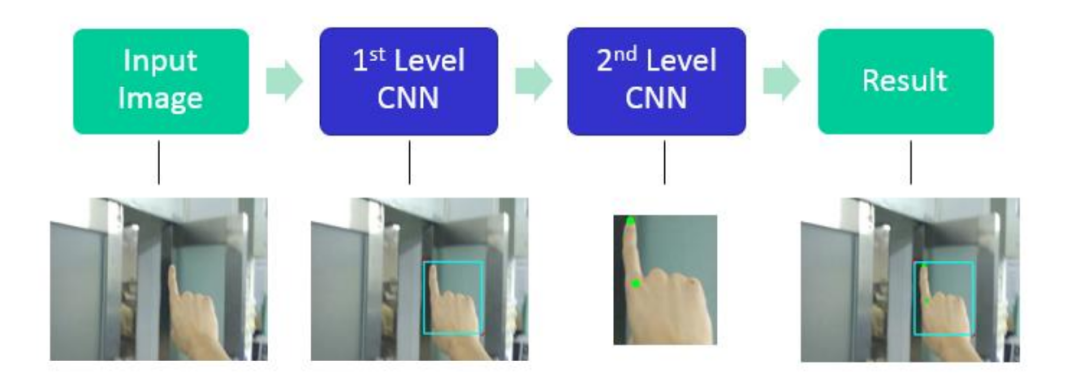
数据集是在各个场景下拍摄的图像,标注信息包括手部矩形框的左上角和右下角归一化坐标,以及指尖点和关节点的归一化坐标。

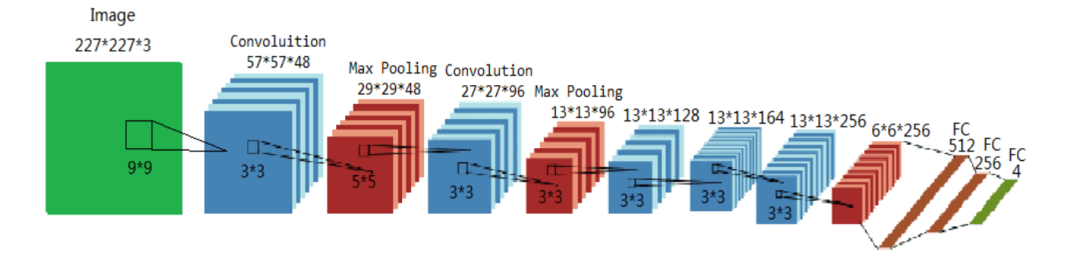
第一个CNN模型结构如下,说实话下面的图有些数据不太准确,有些kernel_size并不能得到相应feature map大小。一般来说,下一层卷积层的输出大小都会依照下面公式得到,即上一层卷积层的大小减去卷积核大小,除以步进大小,再加上2乘以边缘填充大小,最后加1。大家感兴趣可以自行推算。
模型PyTorch代码:
class cascadelevel1(nn.Module):
def __init__(self, num_classes=4):
super(cascadelevel1, self).__init__()
self.conv_pool = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=48, kernel_size=3, stride=4),
nn.BatchNorm2d(num_features=48),
nn.ReLU(),
nn.MaxPool2d(kernel_size=1, stride=2),
nn.Conv2d(in_channels=48, out_channels=96, kernel_size=5, stride=1, padding=1),
nn.BatchNorm2d(num_features=96),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(in_channels=96, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=128),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=164, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=164),
nn.ReLU(),
nn.Conv2d(in_channels=164, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.fc1 = nn.Sequential(
nn.Linear(6*6*256, 512),
nn.ReLU(),
nn.Dropout(0.5),
)
self.fc2 = nn.Sequential(
nn.Linear(512, 256),
nn.ReLU(),
nn.Dropout(0.5),
)
self.fc3 = nn.Linear(256, num_classes)
def forward(self, x):
x = self.conv_pool(x)
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
在第二个CNN模型的构建上,在数据处理阶段,作者认为HSV颜色空间的效果比RGB好,因为主要是关键点都在手部,HSV可以很好的聚类皮肤颜色的重要特征。除此之外,论文还是对HSV三个分量分别使用拉普拉斯算子提取边缘、形状、轮廓等特征(公式如下),并结合到原始HSV中,构成6通道输入,整体模型如下图所示。
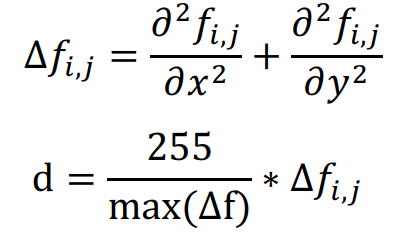
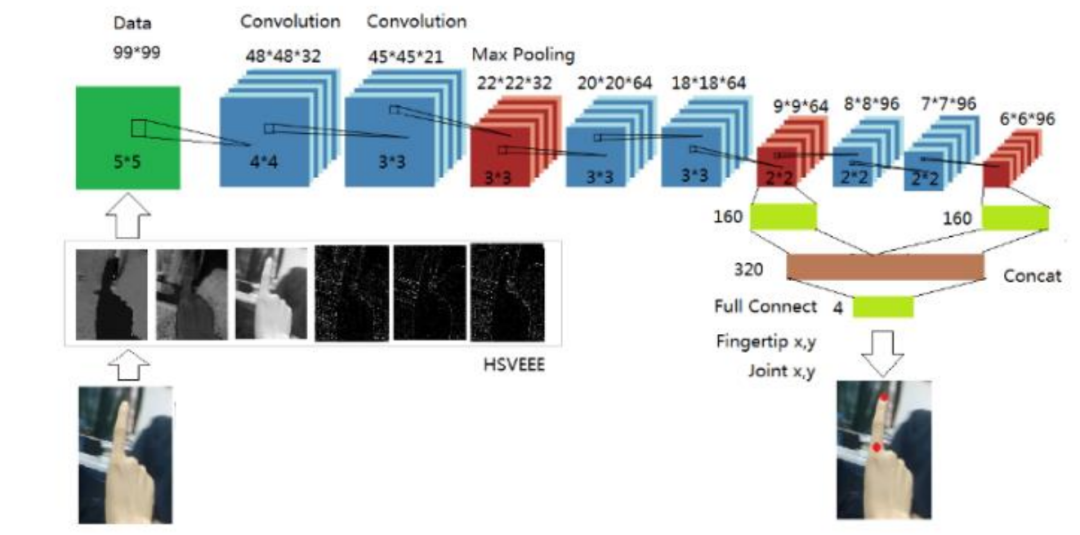
模型PyTorch代码:
class cascadelevel2(nn.Module):
def __init__(self, num_classes=4, first_in_channel=3):
super(cascadelevel2, self).__init__()
assert first_in_channel in [3, 4, 6], "[ERROR] 'first_in_channel' should be 3, 4, 6"
self.conv_pool_1 = nn.Sequential(
nn.Conv2d(in_channels=first_in_channel, out_channels=32, kernel_size=5, stride=2),
nn.BatchNorm2d(num_features=32),
nn.ReLU(),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=4, stride=1),
nn.BatchNorm2d(num_features=32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.conv_pool_2 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=96, kernel_size=2, stride=1),
nn.BatchNorm2d(num_features=96),
nn.ReLU(),
nn.Conv2d(in_channels=96, out_channels=96, kernel_size=2, stride=1),
nn.BatchNorm2d(num_features=96),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=1),
)
self.fc1 = nn.Sequential(
nn.Linear(9*9*64, 160),
nn.ReLU(),
nn.Dropout(0.5),
)
self.fc2 = nn.Sequential(
nn.Linear(6*6*96, 160),
nn.ReLU(),
nn.Dropout(0.5),
)
self.fc3 = nn.Linear(320, num_classes)
def forward(self, x):
x = self.conv_pool_1(x) # 20, 64, 9, 9
x1 = x.view(x.size(0), -1) # 20, 5184
x1 = self.fc1(x1) # 20, 160
x2 = self.conv_pool_2(x) # 20, 96, 6, 6
x2 = x2.view(x2.size(0), -1) # 20, 3456
x2 = self.fc2(x2)
x3 = torch.cat((x1, x2), 1)
out = self.fc3(x3)
return out
二、实验
论文在实验阶段提供的细节太少,损失函数用的是欧拉损失函数,其实就是MSE,
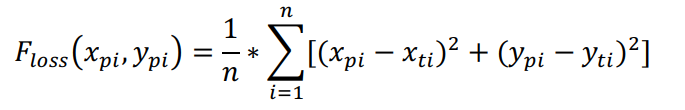
第一个CNN还用了覆盖率F0作为精确率的criteria,其实就是IoU指标。

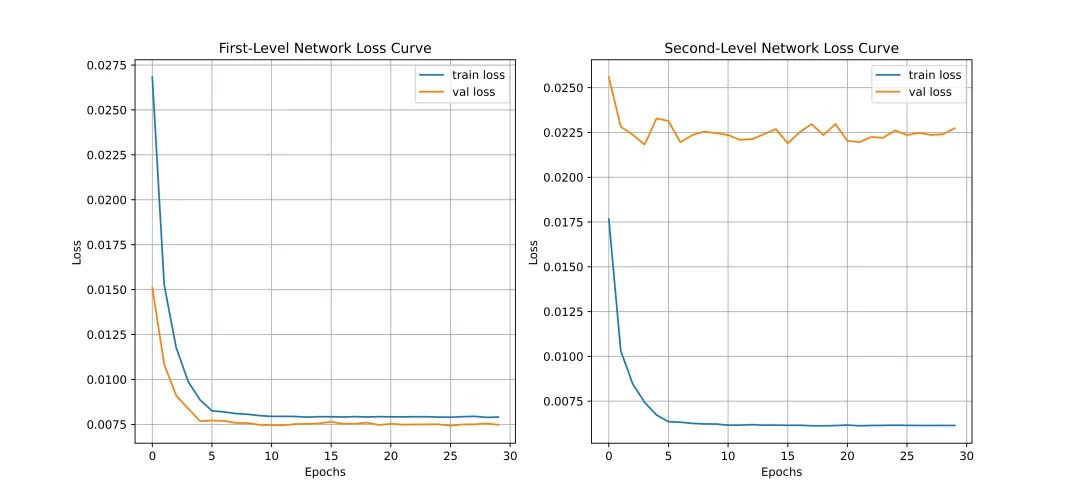
优化器的选择,超参的设置,参数初始化策略等,论文均没有提及,这让我很尴尬到底验证集IoU大于0.7是怎么来的,因为做了很多次试验,结果最好只是去到0.49左右。下图左是两个CNN训练的loss曲线。可以看到,几乎是没有什么下降的。很可能的原因就是训练遇到瓶颈,需要减小学习率或批量数目。
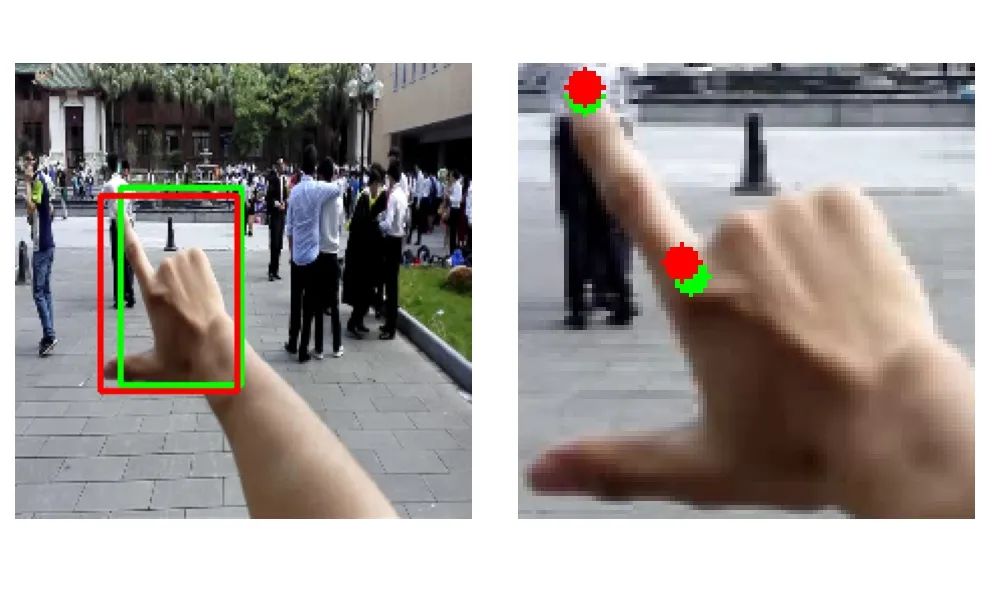
下面展示一些结果,红色表示真实结果,绿色表示预测结果。可以看到,很多效果还是很差。

代码分享:
链接:https://pan.baidu.com/s/1GtdUKLdwUoUEKubBr08-cg
提取码:du7j