
CSWin Transfomer:超越Swin Transformer的网络来了
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
近期,微软亚研院继Swin Transformer之后又推出了CSWin Transformer。和Swin Transformer一样,CSWin Transformer也是一种local self-attention网络,相比Swin的方形window self-attention,CSWin采用的是十字形(cross-shaped)window self-attention,这使得CSWin Transformer的建模能力更强,在分类和检测等任务上也超过Swin Transformer,其中CSWin-L在语义分割数据集ADE20K上达到了SOTA:55.7 mIoU,超过Swin-L的53.5(不过目前微软提出的无监督训练模型BEiT-L已经再次刷新了榜单:57.0 mIoU)。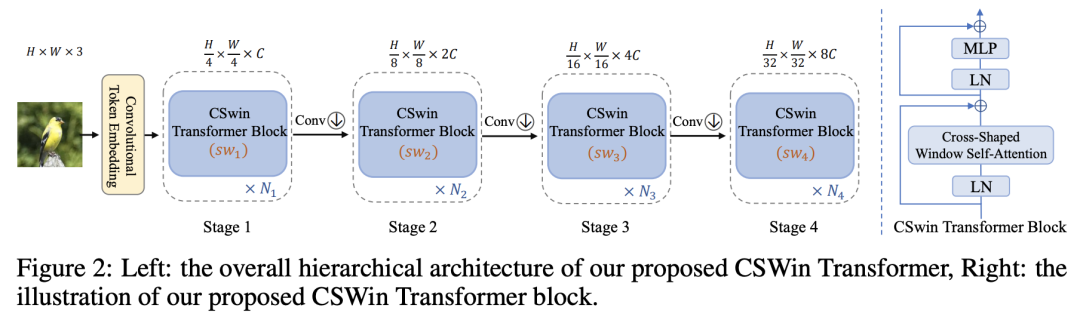 CSWin Transformer和Swin Transformer一样采用金字塔结构,共包括4个stage,各个stage的特征图大小分别是原图的1/4,1/8,1/16和1/32。CSWin Transformer主要有三个重要的改进:Overlapping Patch Embedding,Cross-Shaped Window Self-Attention和Locally-Enhanced Positional Encoding。
CSWin Transformer和Swin Transformer一样采用金字塔结构,共包括4个stage,各个stage的特征图大小分别是原图的1/4,1/8,1/16和1/32。CSWin Transformer主要有三个重要的改进:Overlapping Patch Embedding,Cross-Shaped Window Self-Attention和Locally-Enhanced Positional Encoding。
Overlapping Patch Embedding
PVT和Swin Transformer等较早的金字塔模型中patch embedding是没有overlap的,patch size为的patch embedding操作上等价于stride和kernel size均为的卷积,所以模型开始的patch embedding就是一个stride为4的4x4卷积,而后面各个stage间的patch merging就是一个stride为2的2x2卷积。但是随后的CvT和PVTv2都采用overlapping patch embedding,这个变动是对性能有提升的。因此,CSWin Transformer也采用overlapping patch embedding:开始的patch embedding采用stride为4的7x7卷积,而后面各个stage间的patch merging采用stride为2的3x3卷积:
# patch embedding
stage1_conv_embed = nn.Sequential(
nn.Conv2d(in_chans, embed_dim, 7, 4, 2),
Rearrange('b c h w -> b (h w) c', h = img_size//4, w = img_size//4),
nn.LayerNorm(embed_dim)
)
# patch merging
class Merge_Block(nn.Module):
def __init__(self, dim, dim_out, norm_layer=nn.LayerNorm):
super().__init__()
self.conv = nn.Conv2d(dim, dim_out, 3, 2, 1)
self.norm = norm_layer(dim_out)
def forward(self, x):
B, new_HW, C = x.shape
H = W = int(np.sqrt(new_HW))
x = x.transpose(-2, -1).contiguous().view(B, C, H, W)
x = self.conv(x)
B, C = x.shape[:2]
x = x.view(B, C, -1).transpose(-2, -1).contiguous()
x = self.norm(x)
return x
注意,这里的卷积都需要包含zero padding来保持和原来一样的输出大小。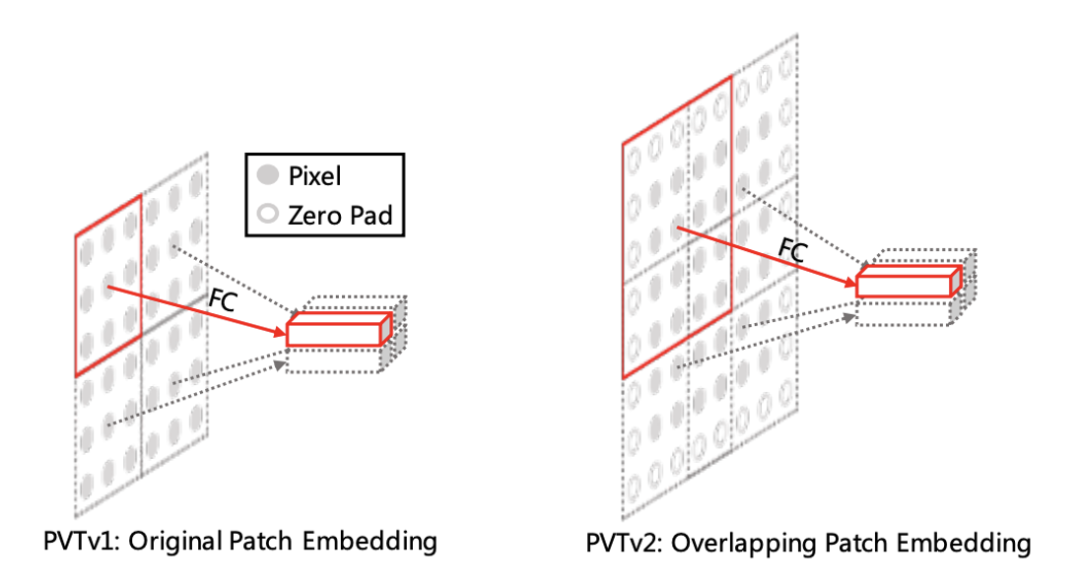
Cross-Shaped Window Self-Attention
CSWin Transformer最核心的部分就是cross-shaped window self-attention,如下所示,首先将self-attention的mutil-heads均分成两组,一组做horizontal stripes self-attention,另外一组做vertical stripes self-attention。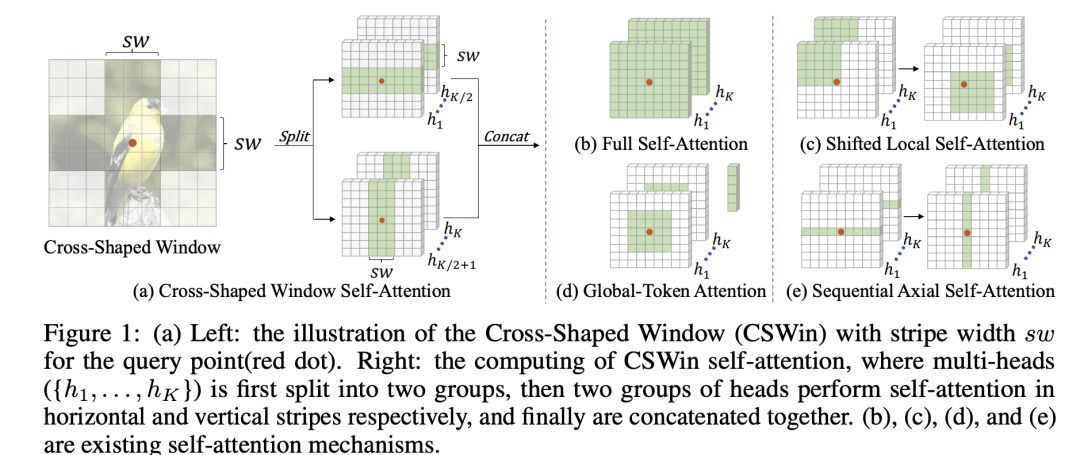 所谓horizontal stripes self-attention就是沿着H维度将tokens分成水平条状windows,对于输入为HxW的tokens,记每个水平条状window的宽度为,那么共产生个windows,每个window共包含个tokens;而vertical stripes self-attention就是沿着W维度将tokens分成竖直条状windows,同样地会产生个windows,每个window的tokens量为。具体的划分窗口代码和Swin transformer一样,通过设定window的宽度和长度来实现两组attention:
所谓horizontal stripes self-attention就是沿着H维度将tokens分成水平条状windows,对于输入为HxW的tokens,记每个水平条状window的宽度为,那么共产生个windows,每个window共包含个tokens;而vertical stripes self-attention就是沿着W维度将tokens分成竖直条状windows,同样地会产生个windows,每个window的tokens量为。具体的划分窗口代码和Swin transformer一样,通过设定window的宽度和长度来实现两组attention:
# 对于水平attention,H_sp=sw, W_sp=W
# 对于竖直attention,H_sp=H, W_sp=sw
def img2windows(img, H_sp, W_sp):
"""
img: B C H W
"""
B, C, H, W = img.shape
img_reshape = img.view(B, C, H // H_sp, H_sp, W // W_sp, W_sp)
img_perm = img_reshape.permute(0, 2, 4, 3, 5, 1).contiguous().reshape(-1, H_sp* W_sp, C)
return img_perm
def windows2img(img_splits_hw, H_sp, W_sp, H, W):
"""
img_splits_hw: B' H W C
"""
B = int(img_splits_hw.shape[0] / (H * W / H_sp / W_sp))
img = img_splits_hw.view(B, H // H_sp, W // W_sp, H_sp, W_sp, -1)
img = img.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return img
两组self-attention是并行的,完成后将tokens的特征concat在一起,这样就构成了CSW self-attention,最终效果就是在十字形窗口内做attention,CSW self-attention的感受野要比常规的window attention的感受野更大。用公式表示的话就是:
可以得到CSWin attention的计算复杂度为,普通的window attention的计算复杂度是和成正比的,而global attention的计算复杂度和的平方成正比的,而CSWin attention的计算复杂度介于两者之间。另外一点是CSWin transformer中不同的stage采用不同的,前面的stage采用较小的,而后面的stage采用较大,这其实也是渐进式地扩大感受野。默认4个stage的分别设为1, 2, 7, 7。CSWin attention的代码实现如下所示:
class CSWinBlock(nn.Module):
def __init__(self, dim, reso, num_heads,
split_size=7, mlp_ratio=4., qkv_bias=False, qk_scale=None,
drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm,
last_stage=False):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.patches_resolution = reso
self.split_size = split_size # sw
self.mlp_ratio = mlp_ratio
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.norm1 = norm_layer(dim)
# 最后一个阶段,实际上执行的是global attention
if self.patches_resolution == split_size:
last_stage = True
if last_stage:
self.branch_num = 1 # 只有一个分支
else:
self.branch_num = 2 # 两个分支,分别执行两组attention
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(drop)
# 最后一个阶段,就只有一个window,不需要再分成两组
if last_stage:
self.attns = nn.ModuleList([
LePEAttention(
dim, resolution=self.patches_resolution, idx = -1,
split_size=split_size, num_heads=num_heads, dim_out=dim,
qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
for i in range(self.branch_num)])
else:
self.attns = nn.ModuleList([
LePEAttention(
dim//2, resolution=self.patches_resolution, idx = i,
split_size=split_size, num_heads=num_heads//2, dim_out=dim//2,
qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
for i in range(self.branch_num)]) # idx区分两组attention
mlp_hidden_dim = int(dim * mlp_ratio)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, out_features=dim, act_layer=act_layer, drop=drop)
self.norm2 = norm_layer(dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H = W = self.patches_resolution
B, L, C = x.shape
assert L == H * W, "flatten img_tokens has wrong size"
img = self.norm1(x)
qkv = self.qkv(img).reshape(B, -1, 3, C).permute(2, 0, 1, 3)
if self.branch_num == 2:
x1 = self.attns[0](qkv[:,:,:,:C//2]) # 一半heads执行水平attention
x2 = self.attns[1](qkv[:,:,:,C//2:]) # 另外一半heads执行竖直attention
attened_x = torch.cat([x1,x2], dim=2) # concat在一起
else:
attened_x = self.attns[0](qkv)
attened_x = self.proj(attened_x)
x = x + self.drop_path(attened_x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
从代码实现可以看到两点,首先是对最后一个stage,由于输入为已经为7x7(输入图像为224x224),而也是7,那么其实只有一个window,就等于在做global attention,也就没必要再分成两组了。而对于前面3个stage,其实CSWin attention是分成两支的,分别做两种attention,虽然两者是相对独立的,但是也是分开做的,主要有两个原因,一是两种attention的窗口数量不一定相同(当H和W不相等时),二是两种attention的positional encoding也是不同的。另外CSWin attention和早期的Sequential Axial很类似,不过后者。论文中也对各种attention机制做了对比实验,无论是分类,检测还是分割,CSWin attention都是更胜一筹(这里CSWin采用non-overlapping patch embedding以及Swin的positional encoding来减少其它因素的干扰):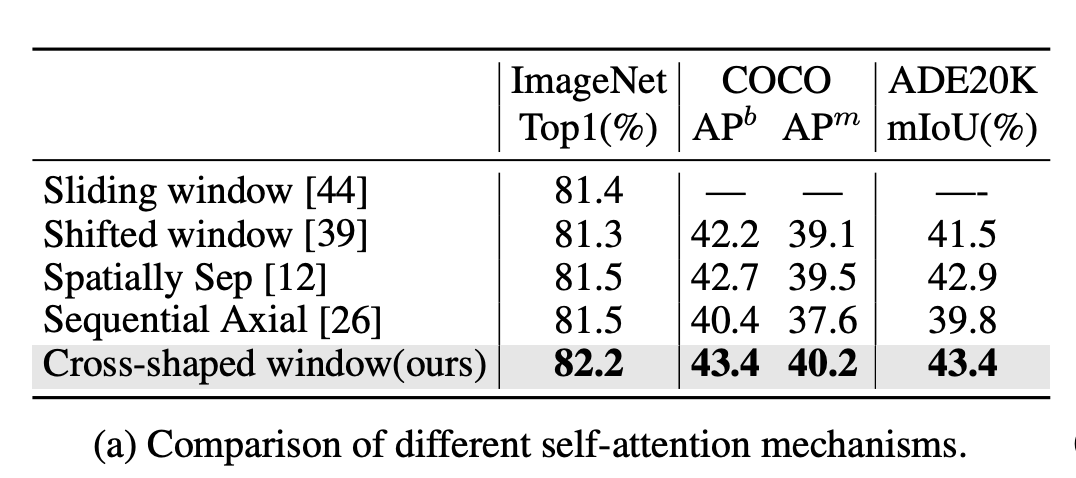
Locally-Enhanced Positional Encoding
CSWin Transformer采用的也是一种relative positional encoding(RPE),不过不同于常规RPE将位置信息加在attention的计算上,这里考虑将位置信息直接施加在上,如下所示:
考虑到的计算量较大,这里用一个depth-wise convolution(3x3卷积)来替换,这其实就主要考虑局部位置信息了,论文称这种位置编码为locally-enhanced positional encoding (LePE):
由于是卷积,所以LePE可以接受任意输入大小,对下游任务如检测和分割比较友好,其具体实现如下:
class LePEAttention(nn.Module):
def __init__(self, dim, resolution, idx, split_size=7, dim_out=None, num_heads=8, attn_drop=0., proj_drop=0., qk_scale=None):
super().__init__()
self.dim = dim
self.dim_out = dim_out or dim
self.resolution = resolution
self.split_size = split_size
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
# 最后一个stage
if idx == -1:
H_sp, W_sp = self.resolution, self.resolution
elif idx == 0: # 水平attention
H_sp, W_sp = self.resolution, self.split_size
elif idx == 1: # 竖直attention
W_sp, H_sp = self.resolution, self.split_size
else:
print ("ERROR MODE", idx)
exit(0)
self.H_sp = H_sp
self.W_sp = W_sp
# LePE
self.get_v = nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1,groups=dim)
self.attn_drop = nn.Dropout(attn_drop)
def im2cswin(self, x):
B, N, C = x.shape
H = W = int(np.sqrt(N))
x = x.transpose(-2,-1).contiguous().view(B, C, H, W)
x = img2windows(x, self.H_sp, self.W_sp)
x = x.reshape(-1, self.H_sp* self.W_sp, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3).contiguous()
return x
def get_lepe(self, x, func):
B, N, C = x.shape
H = W = int(np.sqrt(N))
x = x.transpose(-2,-1).contiguous().view(B, C, H, W)
H_sp, W_sp = self.H_sp, self.W_sp
x = x.view(B, C, H // H_sp, H_sp, W // W_sp, W_sp)
x = x.permute(0, 2, 4, 1, 3, 5).contiguous().reshape(-1, C, H_sp, W_sp) ### B', C, H', W'
lepe = func(x) ### B', C, H', W'
lepe = lepe.reshape(-1, self.num_heads, C // self.num_heads, H_sp * W_sp).permute(0, 1, 3, 2).contiguous()
x = x.reshape(-1, self.num_heads, C // self.num_heads, self.H_sp* self.W_sp).permute(0, 1, 3, 2).contiguous()
return x, lepe
def forward(self, qkv):
"""
x: B L C
"""
q,k,v = qkv[0], qkv[1], qkv[2]
### Img2Window
H = W = self.resolution
B, L, C = q.shape
assert L == H * W, "flatten img_tokens has wrong size"
q = self.im2cswin(q)
k = self.im2cswin(k)
v, lepe = self.get_lepe(v, self.get_v)
q = q * self.scale
attn = (q @ k.transpose(-2, -1)) # B head N C @ B head C N --> B head N N
attn = nn.functional.softmax(attn, dim=-1, dtype=attn.dtype)
attn = self.attn_drop(attn)
x = (attn @ v) + lepe
x = x.transpose(1, 2).reshape(-1, self.H_sp* self.W_sp, C) # B head N N @ B head N C
### Window2Img
x = windows2img(x, self.H_sp, self.W_sp, H, W).view(B, -1, C) # B H' W' C
return x
论文中也对各种位置编码方式做了对比,可以看到LePE在各个任务上效果均最好: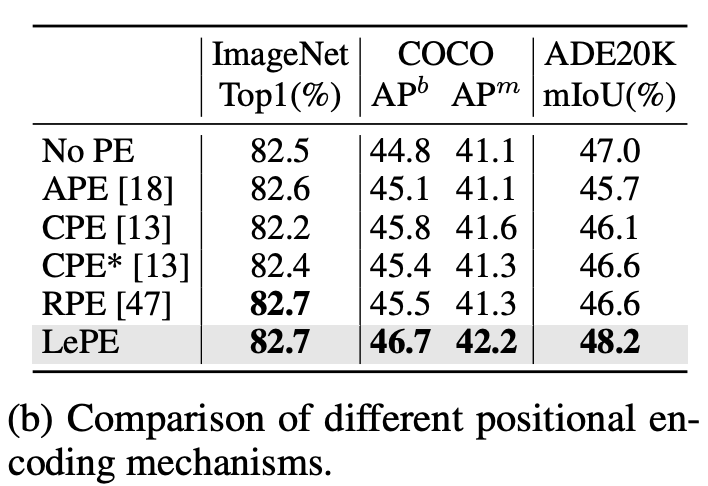
CSWin Transformer
CSWin Transformer的网络设置如下,也包括4个不同大小的模型,其主要区别在channels和各个stages的depth: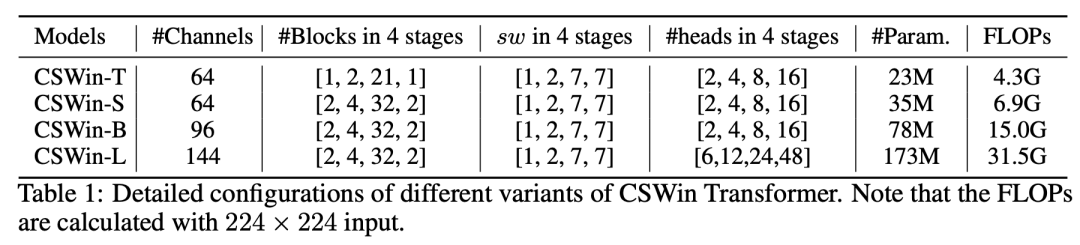 在ImageNet分类上,CSWin Transformer要优于Swin Transformer和Twins等模型:
在ImageNet分类上,CSWin Transformer要优于Swin Transformer和Twins等模型: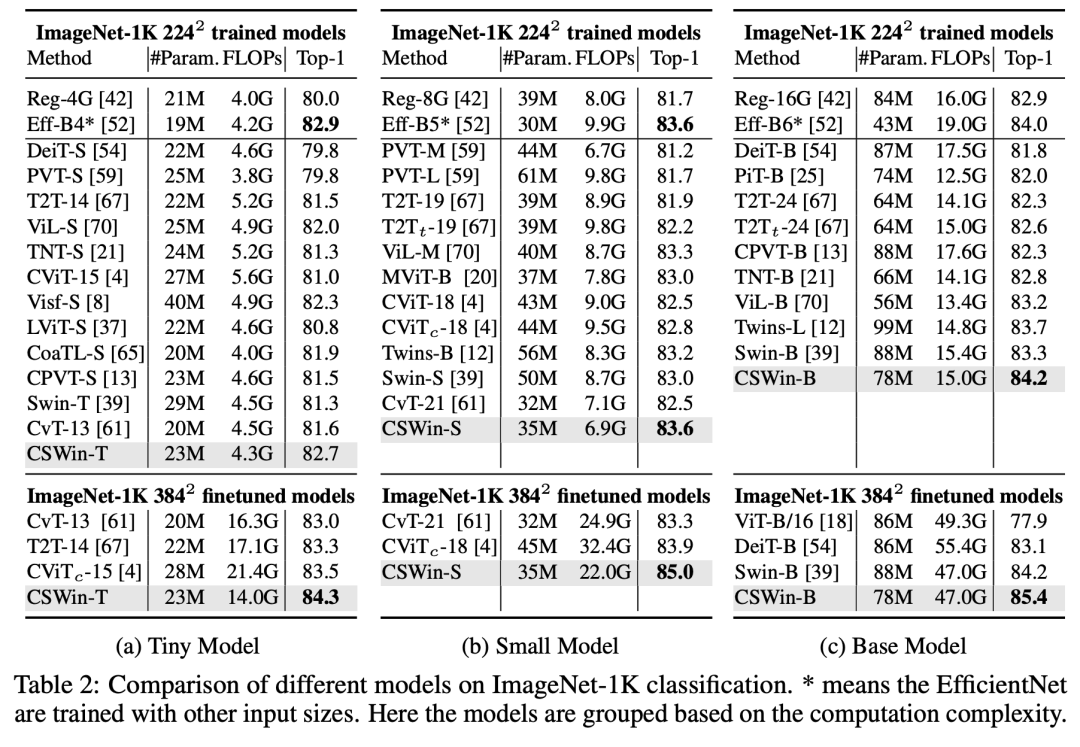 在COCO实例分割任务上,CSWin Transformer的AP也要优于Swin Transformer和Twins等模型:
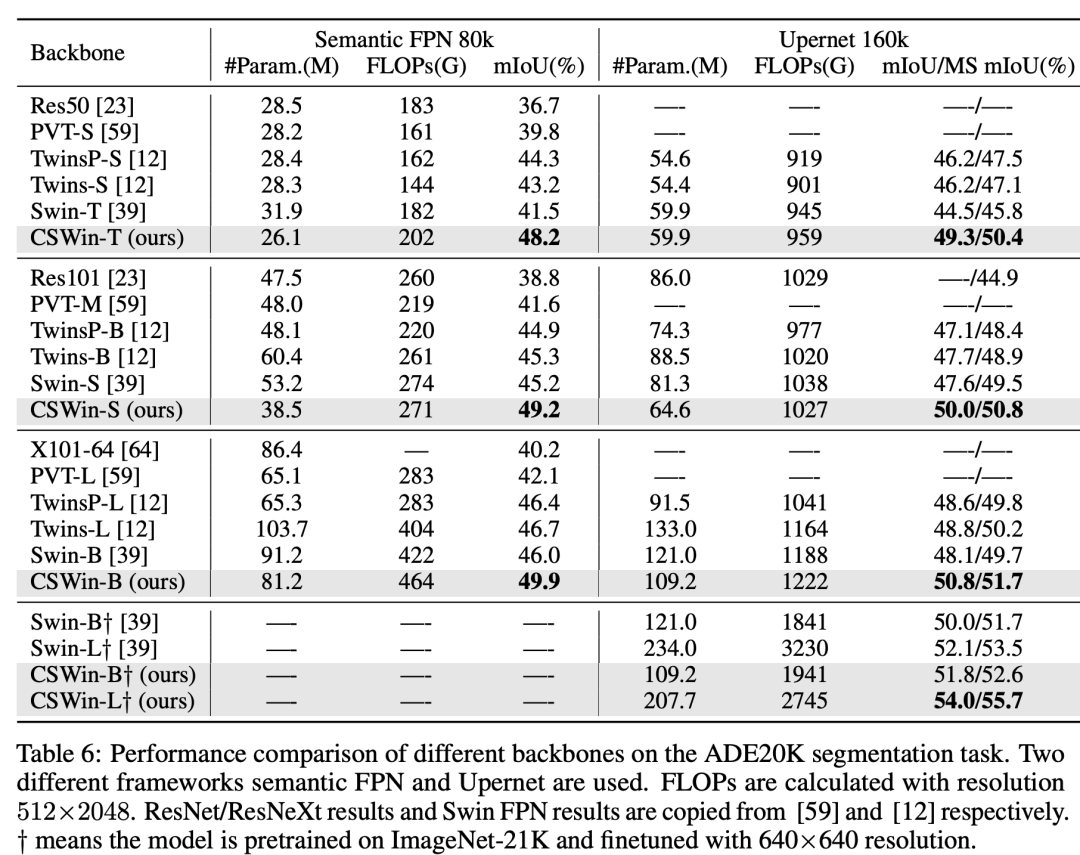
在COCO实例分割任务上,CSWin Transformer的AP也要优于Swin Transformer和Twins等模型: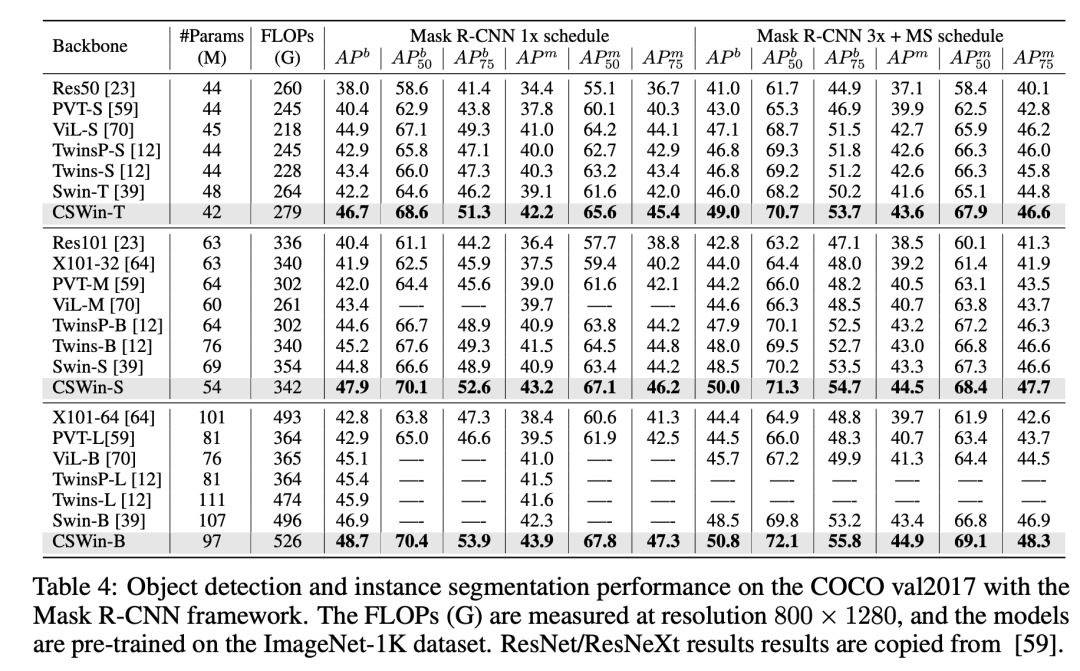 在语义分割ADE20K数据集上,最终的CSWin-L的mIoU达到了55.7:
在语义分割ADE20K数据集上,最终的CSWin-L的mIoU达到了55.7:
小结
相比Swin Transformer,CSWin Transformer更进了一步,这也是local attention网络在CV任务上的胜利。其实同期微软团队还有另外一篇论文Focal Self-attention for Local-Global Interactions in Vision Transformers也取得了较好的性能,但是效果稍微比CSWin Transformer差一些(Focal-L在ADE20K数据集上达到了55.4)。
参考
CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows PVTv2: Improved Baselines with Pyramid Vision Transformer Focal Self-attention for Local-Global Interactions in Vision Transformers
推荐阅读
谷歌AI用30亿数据训练了一个20亿参数Vision Transformer模型,在ImageNet上达到新的SOTA!
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
