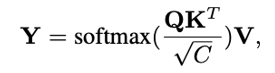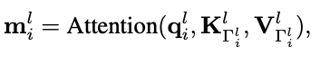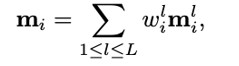点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达

编辑:LRS 好困
【导读】还在发愁注意力的复杂度太高?最近来自西蒙菲莎的华人团队提出一个新机制QuadTree Attention,不仅能够大幅降低计算复杂度,性能还不受影响,并且在self attention和cross attention的任务里都适用!
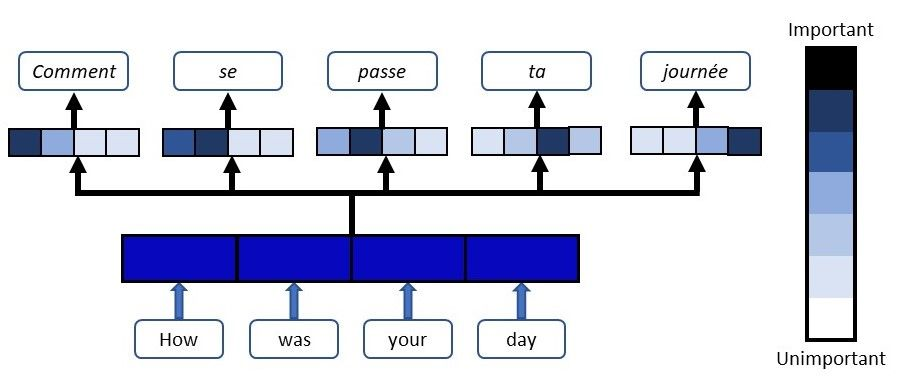
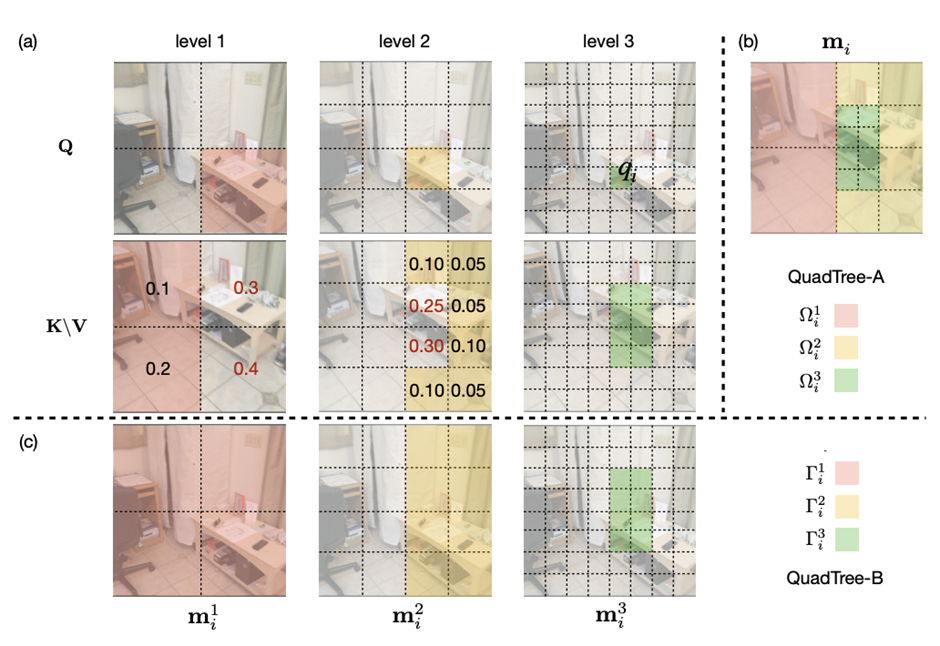
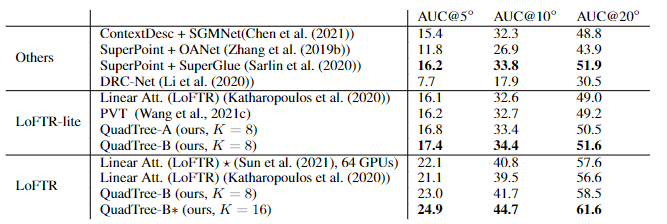
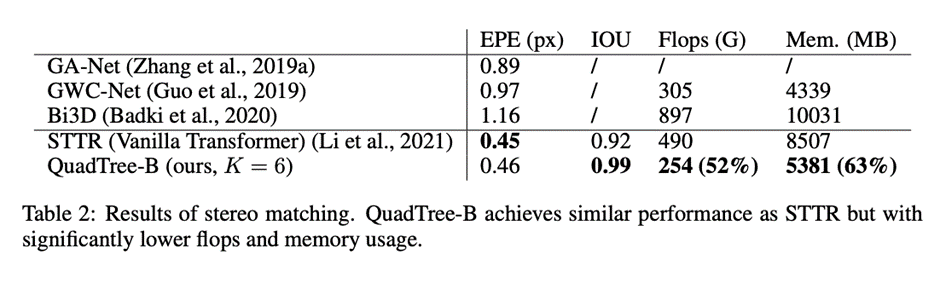
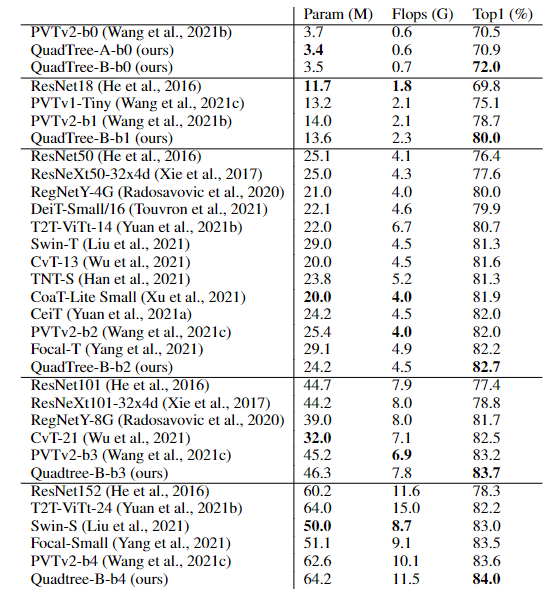
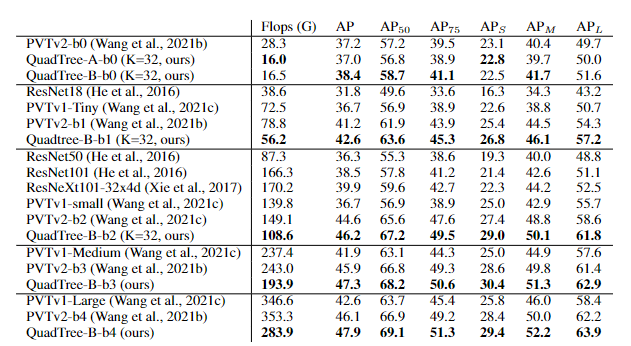
Transformer模型能够捕捉长距离依赖和全局信息,在引入计算机视觉任务后,大多都取得了显著的性能提升。但Transformer的缺陷始终还是绕不过:时间和空间复杂度太高,都是输入序列长度的二次方。通常情况下,一个输入图像被划分为patch,然后flatten这些patch为一个token序列送入Transformer,序列越长,复杂度也就越高。所以,很多视觉任务中为了利用上Transformer,选择将其应用于低分辨率或将注意力机制限制在图像局部。但在高分辨率上应用Transformer能够带来更广阔的应用前景和性能提升,因此,许多工作都在研究设计有效的Transformer以降低计算的复杂性。有学者提出线性近似Transformer,用线性方法近似于标准的Transformer。然而,实验结果显示这些线性Transformer在视觉任务中的性能是比较差的。为了降低计算成本,PVT使用降采样的key和value,使得模型捕捉像素级细节的能力有所下降。相比之下,Swin变换器则是限制了全局注意力的交互信息来减少计算量与以往的工作方向不同,来自西蒙菲莎大学和阿里巴巴AI Lab的研究人员提出了一个全新的注意力机制QuadTree attention,由粗到细地建立注意力机制,能够同时包含全局交互和细粒度的信息,将时间复杂度降低为线性,论文已被ICLR 2022接收。论文地址:https://arxiv.org/abs/2201.02767代码地址:https://github.com/Tangshitao/QuadTreeAttention当我们看一张图片的时候,可以发现,大多数图像区域都是不相关的,所以我们可以建立一个token金字塔,以从粗到细的方式计算注意力。通过这种方式,如果对应的粗级区域不相关,那么我们也可以快速跳过精细级别的不相关区域。例如,第一层计算了图像A中的蓝色区域的注意力,即计算图像A中的蓝色patch与图像B中的所有patch的注意力,并选择前K个patch,把这些patch也被标记为蓝色,代表他们是相关的区域。在第二层,对于图像A中的第一层中蓝色patch的四个子patch,我们只计算它们与对应第一层图像B中top K个patch的子patch的注意力,其他所有其他阴影的子patch都被跳过以减少计算量。我们将图像A中的两个patch用黄色和绿色表示,它们在图像B中对应的前K个patch也用同样的颜色突出显示。整个过程在第三层迭代进行,通过这种方式,既能获得精细的注意力,还能够保留长距离的依赖连接。最重要的是,在整个过程中只需要计算少量的注意力。因此,这种方法具有更低的内存消耗和计算成本。在实现上,研究人员采用了Quadtree 这种数据结构去构建注意力机制。与传统注意力机制一样,首先将embeddings映射Q,K,V。然后用kernel size为2x2的pooling层或者卷积层将他们降采样若干次构建token金字塔。从最粗的那层开始,每一层只选K个最高注意力分数的patch参与下一层的计算。根据计算方式的不同设计了2种机制:QuadTree-A与QuadTree-B。在QuadTree-B方法中,对于最粗的那层,只需根据注意力公式计算。 对于其余几层,则是从上一层选k个注意力分数最高的patch,然后计算message passing。最后把每层的信息结合起来即可,其中w_i是第i层可学参数。寻找不同图像之间的特征对应关系(feature corresponding)是一个经典三维计算机视觉任务,通常的评估方式就是对应点的相机姿态估计准确率。研究人员使用最近提出的SOTA框架LoFTR,其中包括一个基于CNN的特征提取器和一个基于Transformer的匹配器。为了验证QuadTree Transformer的效果,研究人员将LoFTR中的线性变换器替换为QuadTree。此外,文章内还实现了一个新版本的LoFTR与spatial reduction(SR)注意力进行对比。研究人员在包含1513个场景的ScanNet上进行了实验。对于QuadTree Transformer的参数,使用三层金字塔,最粗的分辨率为15×20个像素。在最精细的级别的参数K设置为8,而在较粗的级别上则为两倍。对于SR注意力,将value和key tokens平均池化到8×8的大小以保证和QuadTree Attention相似的内存消耗和flops。在(5◦,10◦,20◦)下相机姿势误差的AUC实验结果中可以看到,SR注意力与线性Transformer取得了类似的结果。相比之下,QuadTreeA 和QuadTreeB在很大程度上超过了线性Transformer和SR注意力,并且Quadtree-B 总体上比Quadtree-A表现得更好。为了进一步提高结果,研究人员还训练了一个K=16的模型,可以看到模型的性能得到进一步提升。在双目视差估计(stereo matching)任务中,目的是在两幅图像之间找到对应的线上的像素。最近的工作STTR将Transformer应用于epipolar line之间的特征点,并取得了SOTA的性能。在将STTR中的标准Transformer替换为QuadTree Transformer后,在Scene Flow FlyingThings3D合成数据集上进行实验,该数据集包含25,466张分辨率为960×540的图像。研究人员建立了四层的金字塔来评估QuadTree Attention,实验结果可以看到非遮挡区域的EPE(End-Point-Error)和遮挡区域的IOU(Intersection-over- Union),表中还包括计算复杂性和内存使用量也被报告。与基于标准Transformer的STTR相比,QuadTree Transformer实现了类似的EPE(0.45 px vs 0.46 px)和更高的闭塞估计IOU,但计算和内存成本低得多,只有52%的FLOPs和63%的内存消耗。研究人员还在基本的self-attention任务中测试了QuadTree Transformer的性能。首先在ImageNet上的图像分类任务实验结果中可以看到,基于PVTv2的模型,将其中的spatial reduction attention替换成quadtree attention,就能够在ImageNet上实现了84.0%的top 1准确度,在不同大小的模型上比PVTv2高0.4-1.5个百分点。在COCO目标检测数据集的实验结果中可以看到,对于QuadTree Attention来说,一个小的K就足够捕捉粗到细的信息了。因此,在使用高分辨率的图像时,可以减少更多计算量。并且QuadTree-B实现了更高的性能,同时比PVTv2的flops少得多,而且性能也同时超过了ResNet和ResNeXt。QuadTree-B-b2的性能比ResNet101和ResNeXt101-32x4d分别高出7.7AP和6.3AP,骨干flops减少约40%。在ADE20K的语义分割实验中,在相似的参数量与flops下,比PVTv2提升了0.8-1.3。一作唐诗涛,现在西蒙菲莎大学三年级在读博士,导师谭平,研究方向为深度学习,三维视觉。在ECCV、ICCV、CVPR、ICML、ICLR等会议上发表多篇论文。共同一作张家辉,现任阿里巴巴算法工程师。2020年于清华大学取得博士学位,研究方向为三维重建、三维深度学习。博士期间在Intel中国研究院及港科大实习或交流。在ECCV、ICCV、CVPR、ICLR、TPAMI、TVCG等会议或期刊上发表多篇论文。朱思语博士,阿里云人工智能实验室算法团队负责人。他于香港科技大学获得博士学位。在攻读博士学位期间,共同创办了3D视觉公司Altizure。朱思语博士在ICCV、CVPR、ECCV、PAMI等计算机视觉国际学术会议和期刊上发表30多篇论文。谭平,现就职于阿里巴巴XR实验室,曾任西蒙菲莎大学终身副教授、新加坡国立大学副教授。主要研究兴趣包括计算机视觉、计算机图形学、机器人技术、3D 重建、基于图像的建模、图像和视频编辑、照明和反射建模。
参考资料:
https://arxiv.org/abs/2201.02767
推荐阅读
13个你一定要知道的PyTorch特性
解读:为什么要做特征归一化/标准化?
一文搞懂 PyTorch 内部机制
张一鸣:每个逆袭的年轻人,都具备的底层能力
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!