
Delta 性能 | Delta vs Iceberg:到底哪个性能更强?

上周大数据领域的大事毫无疑问就是一年一度的Spark Summit(现在改名叫Data + AI Summit)。Databricks在大会上宣布了很多重磅消息,如新的数据共享方式Data Cleanroom[1],新的Spark Streaming处理引擎Lightspeed[2],MLflow 2.0[3]等,但其中最重磅的莫过于Delta Lake宣布完整开源[4],包括之前只有付费版才有的Z-ordering等功能也都开源了(上周刚说Databricks藏着掖着不愿开源,没想到打脸来得如此迅速)。
Databricks选择在这个时间点开源,很明显的是因为感受到来自Iceberg等开源项目的挑战。因此在官宣文章中特意强调Delta 2.0可以直接和Flink,Presto,Trino等交互,不依赖于Spark(因为Delta之前常被诟病为强绑定Spark)。也支持通过Python,Rust,Ruby等语言进行直接读写。
至于为什么对手是Iceberg,那是因为Iceberg这两年的发展势头非常迅猛,还有Dremio,Cloudera等Databricks的竞争对手强力助推,应该是让Databricks感到了威胁。尽管在官宣文章里没有直接提到Iceberg,但处处都有影射(例如“Delta Lake始终提供无人可比的,开箱即用的高性能体验,无论是批处理还是流处理——相比于其他存储系统快至多4.3倍”),甚至在新功能列表里还有一项:Iceberg to Delta converter。

新功能列表里就有一项:Iceberg to Delta converter。
正好性能也是我很感兴趣的话题,这周又碰巧看到一篇比较Delta和Iceberg性能的文章,觉得很有参考价值,因此翻译过来,希望帮助大家更好地做技术选型。
介绍
数据湖仓是一种开放的数据架构,它同时带来数据湖的可扩展性和低成本,与数据仓库的可靠性和高性能——在一个数据平台上。
简单地说,数据湖仓是唯一一种数据架构,允许你在数据湖中存储所有类型的:非结构化的、半结构化的和结构化的数据,又同时保持数据仓库的数据质量和治理标准。
数据湖的关键支柱之一就是它的开放格式。数据的存储格式可能是建设数据湖仓时需要做的最重要的决定。想想看,仅仅只是改变数据的存储格式,就可以获得新的功能,并提高整个系统的性能,这是多么令人激动的一件事。
不幸的是,在所有关于Delta和Iceberg之间对比的文章,比较的范围都仅限于功能。这就是为什么我们想对这两种格式进行性能层面的比较,通过使用TPC-DS的基准测试,模拟真实世界的场景。
什么是TPC-DS?
TPC-DS是一个数据仓库的基准测试,由Transaction Processing Performance Council(TPC)定义。TPC是一个非营利性组织,由数据库社区在20世纪80年代末成立的,其目标是开发可以客观地用于通过模拟真实世界场景来测试数据库系统性能的基准。TPC已经对数据库行业产生了重大影响。
"帮助决策"(Decision Support)是TPC-DS中的"DS"所代表的含义。TPC-DS共包含99个查询,从简单的聚合到高级模式分析。
环境搭建
在这个基准测试中,我们使用了Delta 1.0和Iceberg 0.13.0,环境配置列于下表。

如前所述,我们使用了Delta Oss的开源TPC-DS基准测试[5],并对其进行了扩展以支持Iceberg。我们记录了Load性能,也就是将数据从Parquet格式加载到Delta/Iceberg表中所需的时间。然后,我们也记录了Query性能。每个TPC-DS查询被运行三次,使用平均运行时间作为结果。
测试结果
1. 整体性能
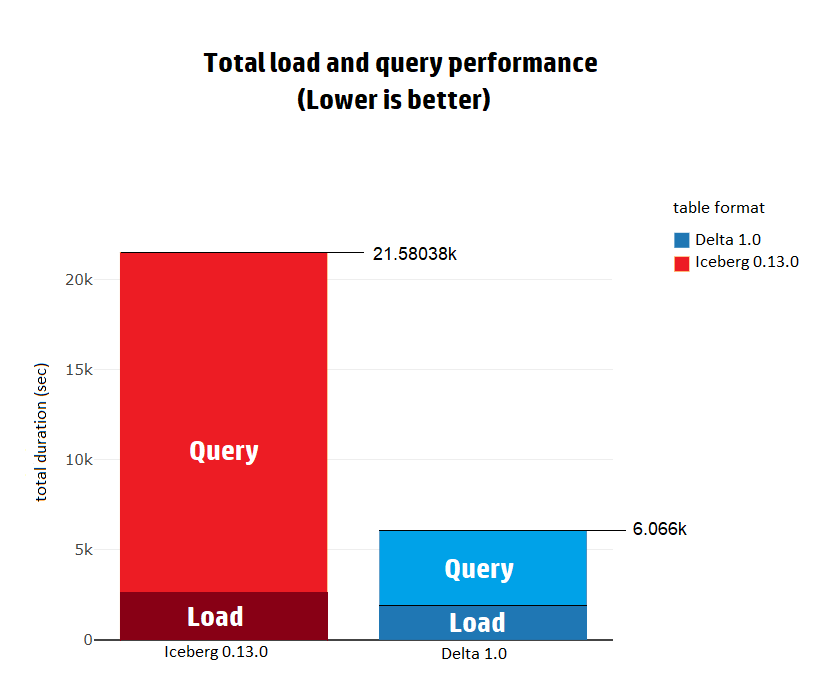
在完成基准测试后,我们发现无论是Load还是Query,整体性能都是Delta更优,因为它比Iceberg快3.5倍。将数据加载到Delta并执行TPC-DS查询需要1.68小时,而Iceberg则需要5.99小时。
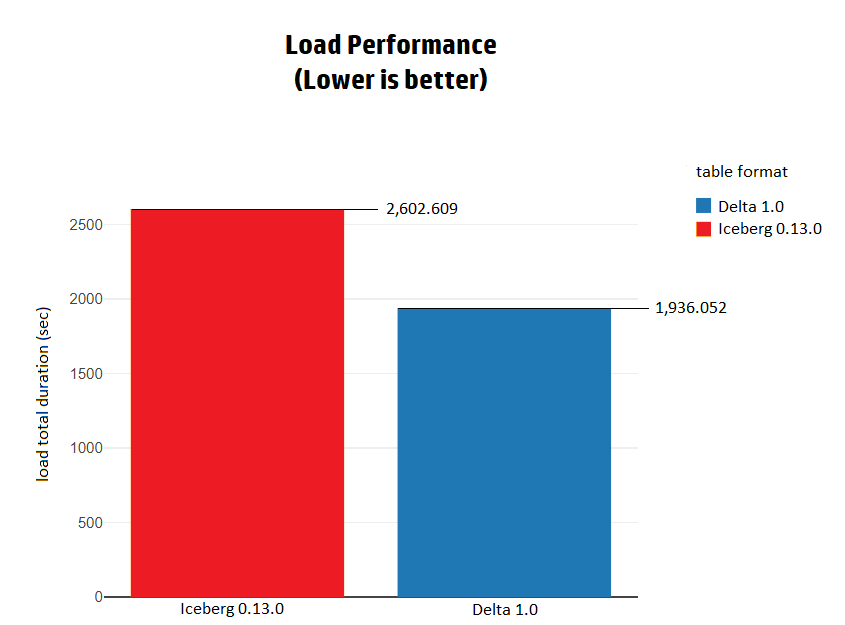
2. Load性能
当从Parquet文件加载数据到两种格式时,Delta在整体性能上比Iceberg快1.3倍。
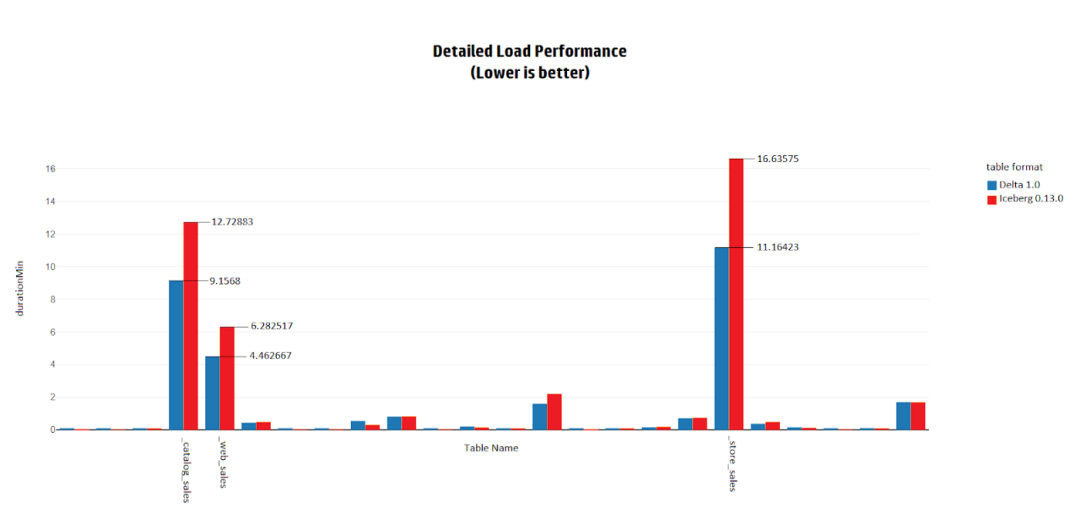
为了进一步分析Load性能的结果,我们深入研究了每张表的详细加载结果,并注意到当表的大小变大时,加载时间的差异会变大。例如,当加载customer表时,Delta和Iceberg的性能实际上是一样的。另一方面,在加载store_sales表,也就是TPC-DS基准中最大的表之一时,Delta比Iceberg快1.5倍。
这表明,在加载数据时,Delta比Iceberg更快、扩展性更好。
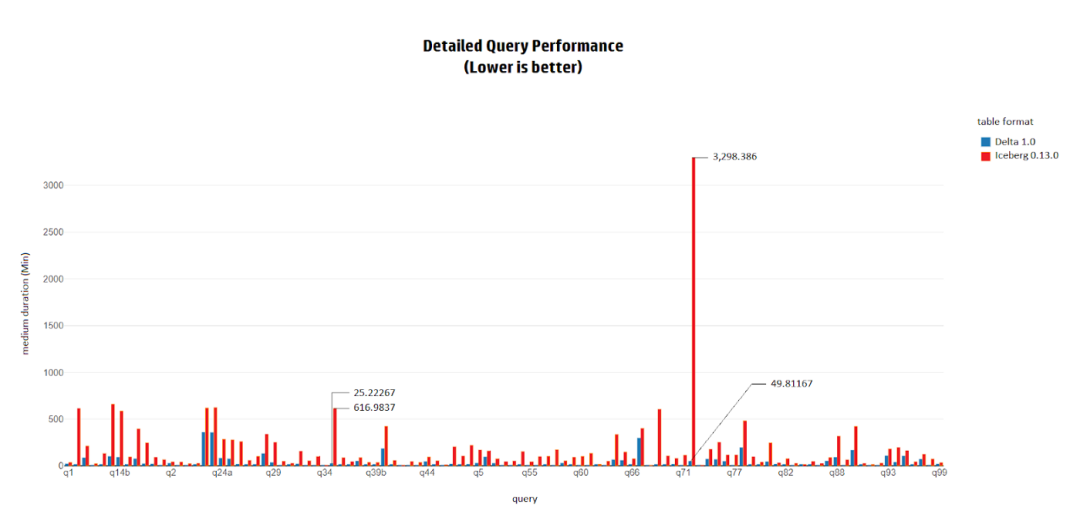
3. Query性能
在执行TPC-DS查询时,Delta的整体性能比Iceberg快4.5倍。在Delta上执行所有查询需要1.14小时,而在Iceberg上执行同样的查询需要5.27小时。
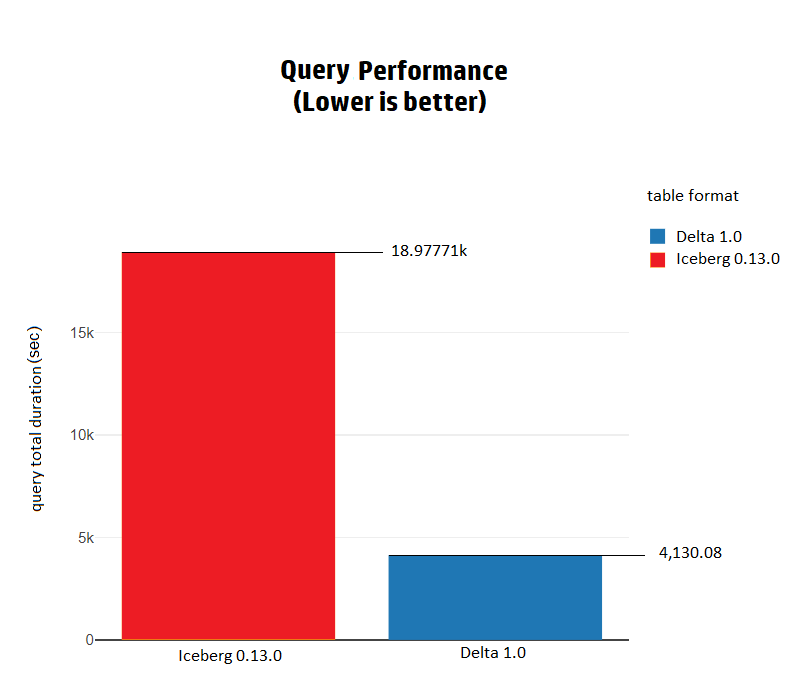
Iceberg和Delta在query34、query41、query46和query68中表现出基本相同的性能。在这些查询中的差异小于1秒。
然而,在其他的TPC-DS查询中,Delta都比Iceberg快,而且差异水平各有不同。
在一些查询中,如query72,Delta比Iceberg快66倍。
而在其他的查询中,Delta和Iceberg之间的差异在1.1倍到24倍之间,都是Delta更快。
总结
在运行该基准测试后,Delta在可扩展性和性能方面都超过了Iceberg,并且幅度有时候意想不到地大。这个基准测试对我们和我们的客户来说提供了一个明确的答案,在构建数据湖仓时应该选择哪种解决方案。
同样需要指出的是,Iceberg和Delta都在不断地改进,随着他们的改进,我们将持续关注他们的性能表现,并在更广泛的社区分享我们的结果。
如果你希望进一步分析并从这个基准测试结果中提炼你的见解,你可以在这里下载完整的基准测试报告[6]。
原文地址:
如果觉得这篇文章对你有所帮助,
请点一下赞或在看,是对我的肯定和支持~
参考资料
Introducing Data Cleanrooms for the Lakehouse: https://databricks.com/blog/2022/06/28/introducing-data-cleanrooms-for-the-lakehouse.html
[2]Project Lightspeed: Faster and Simpler Stream Processing With Apache Spark: https://databricks.com/blog/2022/06/28/project-lightspeed-faster-and-simpler-stream-processing-with-apache-spark.html
[3]MLflow 2.0 with MLflow Pipelines: https://databricks.com/blog/2022/06/29/introducing-mlflow-pipelines-with-mlflow-2-0.html
[4]Open Sourcing All of Delta Lake: https://databricks.com/blog/2022/06/30/open-sourcing-all-of-delta-lake.html
[5]benchmarks: https://github.com/delta-io/delta/tree/master/benchmarks
[6]TPC-DS-Benchmark: https://github.com/saifeddine1992/TPC-DS-Benchmark-report.gi
一个专注于大数据领域顶层认知和底层实现的公众号: