
任务通用!清华提出主干网络Flowformer,实现线性复杂度|ICML2022
新智元报道
新智元报道
作者:吴海旭
【新智元导读】近年来,Transformer方兴未艾,但是其内在的二次复杂度阻碍了它在长序列和大模型上的进一步发展。清华大学软件学院机器学习实验室从网络流理论出发,提出任务通用的线性复杂度主干网络Flowformer,在长序列、视觉、自然语言、时间序列、强化学习五大任务上取得优秀效果。
为此,来自清华大学软件学院的团队深入探索了这一关键问题,提出了任务通用的线性复杂度主干网络Flowformer,在保持标准Transformer的通用性的同时,将其复杂度降至线性,论文被ICML 2022接受。

作者列表:吴海旭,吴佳龙,徐介晖,王建民,龙明盛
链接:https://arxiv.org/pdf/2202.06258.pdf
代码:https://github.com/thuml/Flowformer
线性复杂度,可以处理数千长度的输入序列; 没有引入新的归纳偏好,保持了原有注意力机制的通用建模能力; 任务通用,在长序列、视觉、自然语言、时间序列、强化学习五大任务上取得优秀效果。
1. 问题分析
2. 动机
Softmax中的竞争机制
网络流中的竞争机制
3. Flowformer
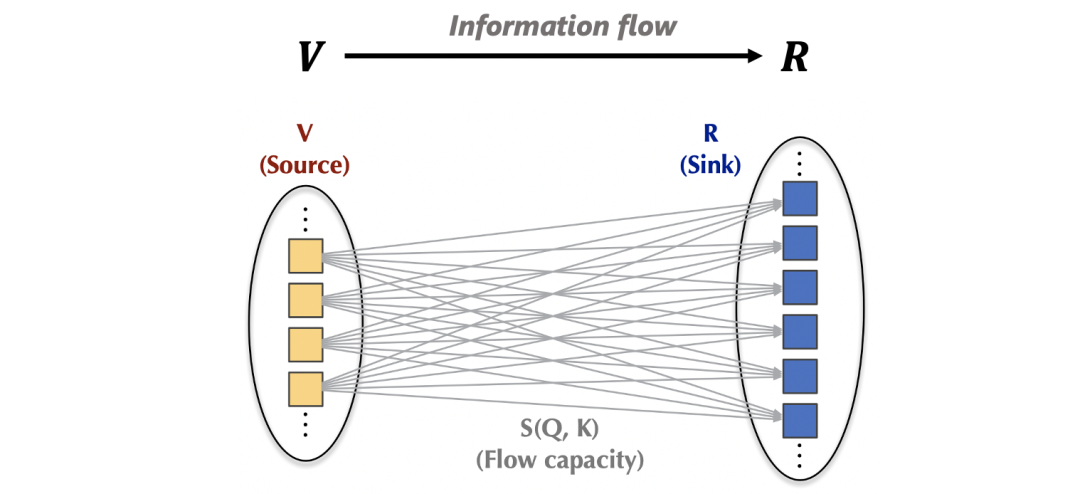
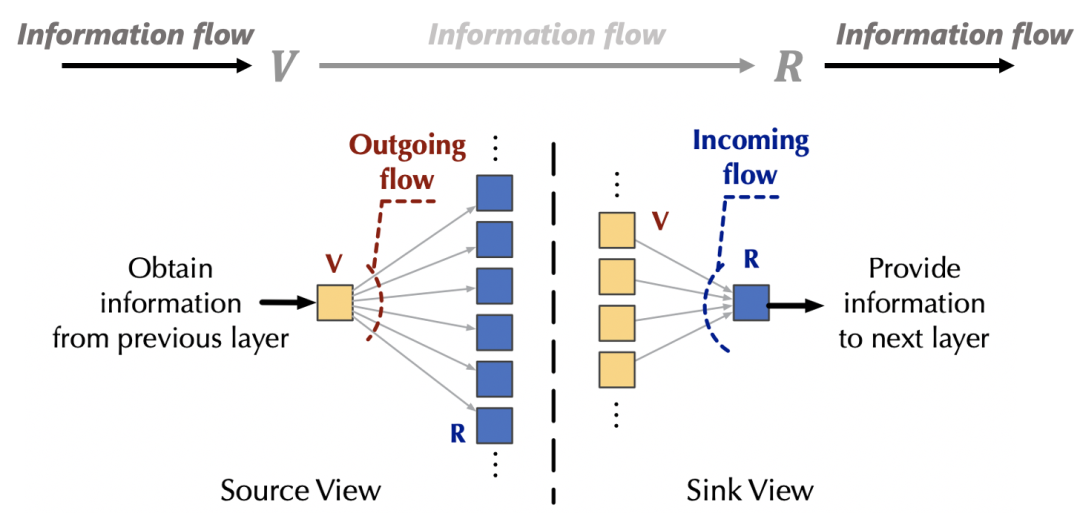
3.1 网络流视角下的注意力机制
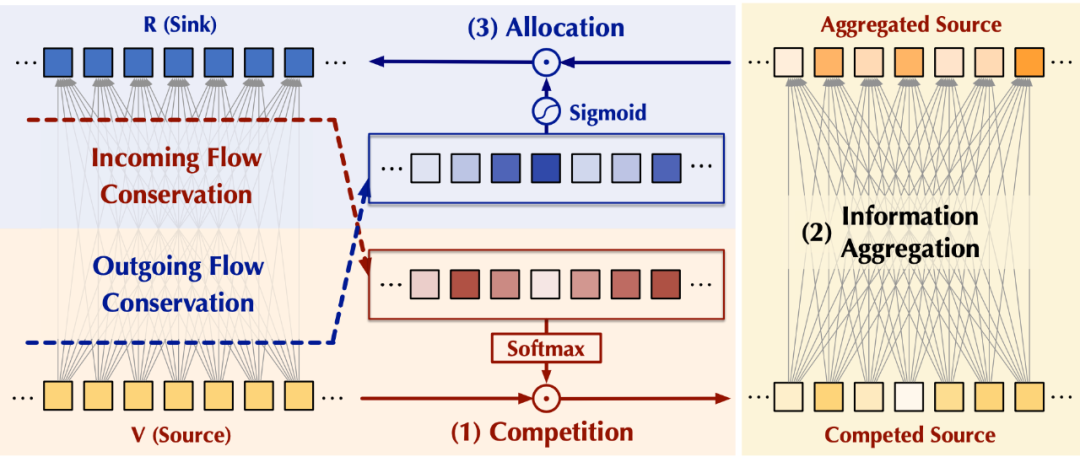
3.2 Flow-Attention
基于上述观察,我们可以通过分别从流入和流出两个角度,控制注意力机制与外部网络的交互,来实现「固定资源」,从而分别引起源和汇内部的竞争,以避免平凡注意力。不失一般性,我们将注意力机制与外部网络的交互信息量设置为默认值1.
(3)整体设计
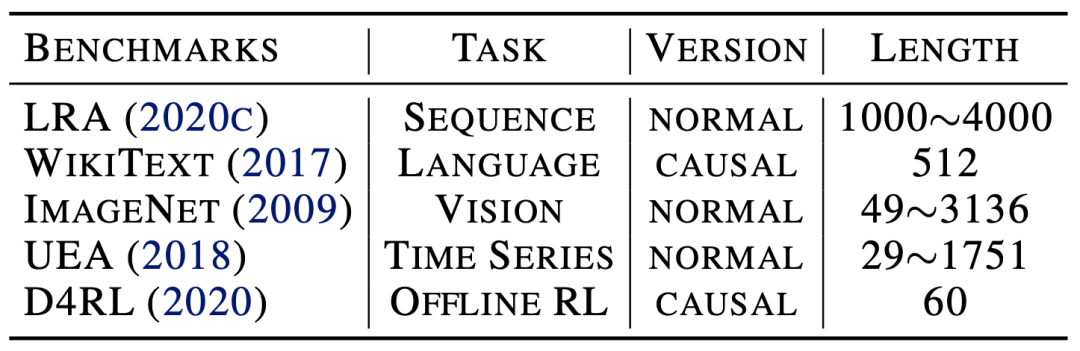
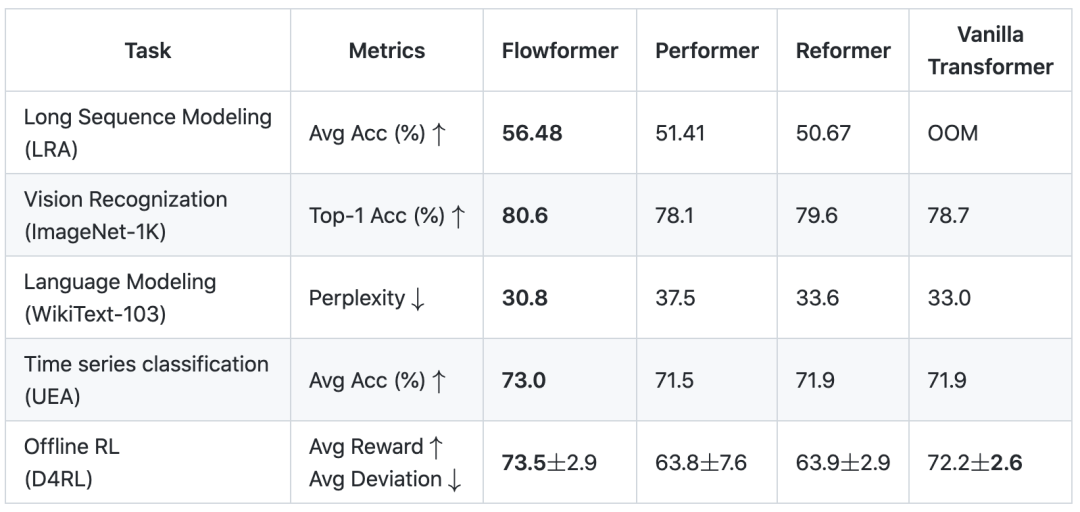
4. 实验
覆盖了长序列、视觉、自然语言、时间序列、强化学习五大任务;
考察了标准(Normal)和自回归任务(Causal)两种注意力机制类型。
涵盖了多种序列长度的输入情况(20-4000)。
对比了各领域经典模型、主流深度模型、Transformer及其变体等多种基线方法。
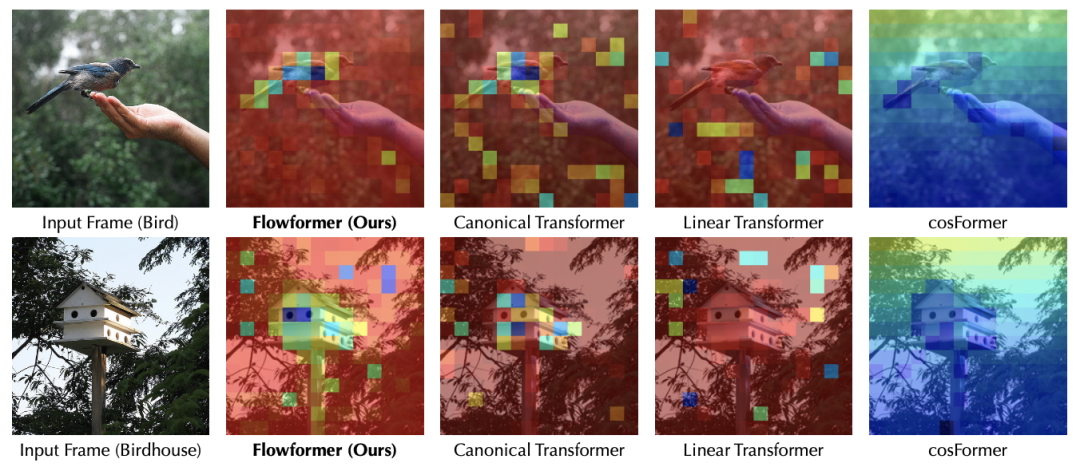
5. 分析
如果仅仅使用核方法进行分解,如Linear Transformer,会造成模型注意力分散,无法有效捕捉到关键区域;
经典Transformer和Flowformer均可以准确捕捉到图像的关键位置,但是后者在计算复杂度上具有优势;
cosFormer在注意力机制中引入一维局部性假设,在语言任务上效果突出。但是在图像(将2D数据展开成1D序列)中,如果不将局部性假设扩展至二维,则无法适配视觉任务。这也印证了Flowformer中「没有引入新的归纳偏好」设计方式的优势。
6. 总结
参考资料:
https://arxiv.org/pdf/2202.06258.pdf

评论