
中山大学提出ASAG | 简单有效的Query加权成就性能更强的目标检测
点击下方卡片,关注「集智书童」公众号

最近,具有多个解码器层的稀疏检测器,例如6个,取得了令人鼓舞的性能,但由于复杂的Head结构而导致推理时间较长。以前的研究探讨了使用密集先验作为初始化并构建一个解码器层检测器的方法。尽管它们取得了显著的加速,但其性能仍远远落后于具有6个解码器层的对应模型。
在这项工作中,目标是弥合这一性能差距,同时保持快速速度。作者发现,密集和稀疏检测器之间的架构差异导致了特征冲突,妨碍了单解码器层检测器的性能。因此,提出了Adaptive Sparse Anchor Generator(ASAG),它以一种稀疏的方式在图像块而不是网格上预测动态Anchor,从而减轻了特征冲突问题。对于每个图像,ASAG动态选择要预测的特征图和位置,形成了一种完全自适应的生成图像特定Anchor的方式。
此外,一个简单而有效的Query 加权方法可以减轻由于自适应性而引起的训练不稳定性。大量实验证明,本文的方法优于密集初始化方法,并实现了更好的速度-精度权衡。
代码:https://github.com/iSEE-Laboratory/ASAG
1、简介
目标检测是一个基础且具有挑战性的计算机视觉任务。与传统的基于CNN的密集目标检测器不同,基于Query 的稀疏检测器使用数百个目标Query 来搜索整个图像,每个 Query 代表一个目标或背景。它们摆脱了一些传统的手工制作组件和流程,例如Anchor和非极大值抑制(NMS),这极大简化了检测管道,并使检测器完全可端到端训练。在强大的Transformer编码器-解码器架构的帮助下,稀疏检测器展现出令人期待的性能。
然而,稀疏检测器需要n个解码器层(通常n = 6)来逐渐精化边界框,从而导致更复杂的Head结构,因此推理时间更长。仅使用一个解码器层的推理速度要快得多,例如AdaMixer(43帧/秒对比22帧/秒)和Sparse RCNN(43帧/秒对比25帧/秒)。解码器越复杂,FPS差距就越大。不幸的是,简单地丢弃额外的解码器层会导致性能显著下降。
最近,一些方法试图弥合一个解码器层和6个解码器层检测器之间的性能差距。Efficient DETR发现,当使用一个解码器层时,图像无关的Box和内容Query 应该受到严重性能下降的指责。因此,这两种方法都在解码器之前使用额外的密集Box预测步骤来提供适当的Query 初始化。然而,它们无法达到与具有6个解码器层的检测器可比较的结果,例如,Featurized Query RCNN的性能低于Sparse RCNN 1.5AP(100个Query )。本文发现,与稀疏检测器相对应的特征明显不同。这种特征冲突妨碍了一个解码器层检测器的性能,如第3节所示。因此,尽管这些方法取得了显著的加速,但仍然有很大的改进空间。
在这项工作中,本文的目标是构建一个完全稀疏的一个解码器层检测器,缩小1个和6个解码器层检测器之间的性能差距,并保持快速速度。本文的方法与其他密集初始化方法的关键区别在于,本文将图像块作为基本的预测单位,它可以是整个图像或图像的一部分。在图像块上稀疏预测可以缓解通过网格预测引起的特征差异,并享受全局感受野。
此外,本文提出了放宽每个图像都应使用固定数量Query 来检测目标的约束,以便更复杂的图像可以使用更多的Query 来检测目标,反之亦然。基于这两个前提条件,本文提出使用Adaptive Sparse Anchor Generator(ASAG)来初始化图像特定的Query ,ASAG可以在Anchor的位置和数量方面完全适应每个图像。
本文还设计了自适应探测,以自适应地裁剪不同特征图级别上可能的位置上的图像块。它以自上而下和由粗到细的方式运行,极大地增强了检测小目标的能力。最后,本文提出了一种有效的Query 加权方法,用于处理自适应性带来的不稳定性。
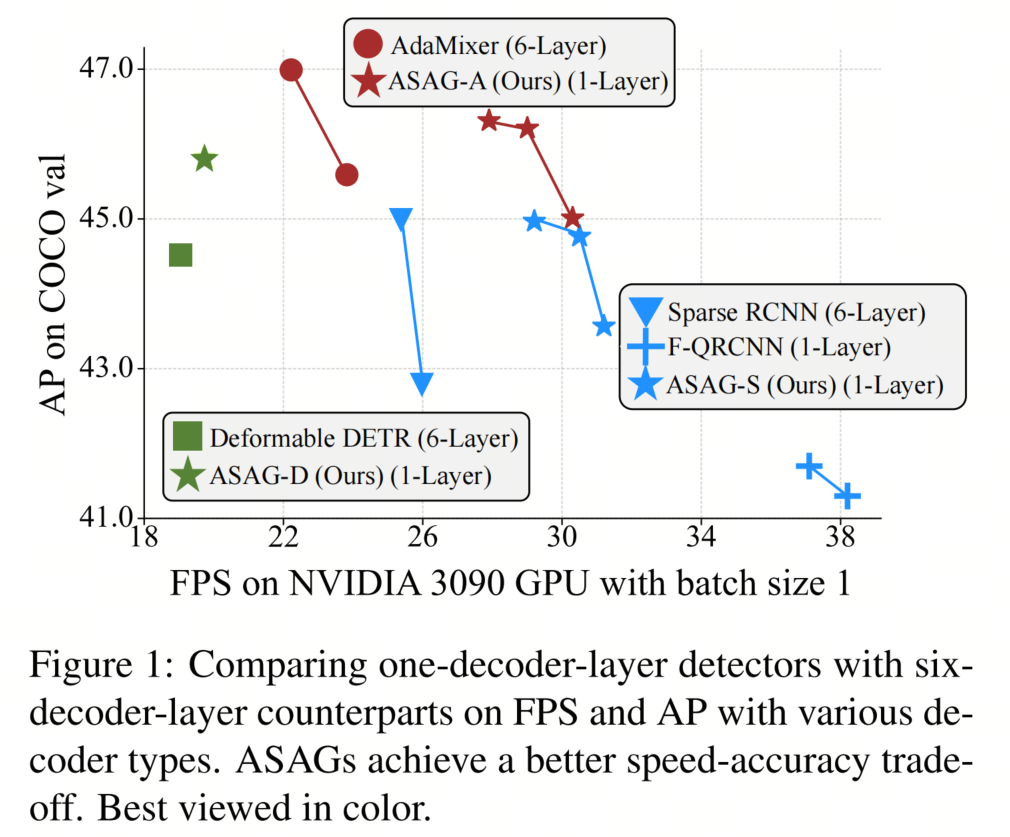
本文在COCO数据集上进行了大量实验,使用不同的解码器类型。如图1所示,本文的模型ASAG-S在更少的FLOPs和相同的解码器下优于密集初始化的Query RCNN 2.6 AP。本文还保留了一个解码器层检测器的快速速度,从而实现更好的速度-精度权衡。
2、相关工作
2.1、Improving Sparse Detectors
最近,DETR 将目标检测视为一个集合预测问题,并取得了令人满意的性能。但它仍然有一些明显的缺点,缺乏可解释性。许多后续工作通过利用多尺度特征金字塔,引入更多的空间先验,稳定双边匹配,对齐特征空间,增加正样本,使用知识蒸馏,初始化Query等方法来解决了慢收敛和在小目标上相对低性能等问题。尽管取得了出色的性能和快速的收敛速度,基于Transformer的稀疏检测器仍然需要比基于CNN的稠密检测器更多的推断时间,从而限制了它们的实际应用。
2.2、Accelerating Sparse Detectors
作为一个众所周知的经验,检测器中的大部分计算都集中在主干网络上,因为主干网络生成高分辨率特征图并执行密集计算。然而,由于稀疏检测器的颈部和Head具有更复杂的运算,例如自注意力和网格采样,因此FLOPs不能直接反映FPS。例如,AdaMixer的解码器占据了总FLOPs的31%,但几乎占据了一半的FPS。与关注通过近似编码器中的自注意力来减少颈部计算的工作不同,本文的目标是简化解码器。
最近,Li等人发现一些不重要的Query 不值得等价计算。然而,减少Query 数量带来的加速效果较小,因为将Query 数量从100增加到300只会额外使用1 FPS,就像Sparse RCNN一样。因此,减少解码器阶段的数量是加速稀疏检测器的更有前途的方式。
3、为什么应该对One-Decoder-Layer检测器使用稀疏初始化?
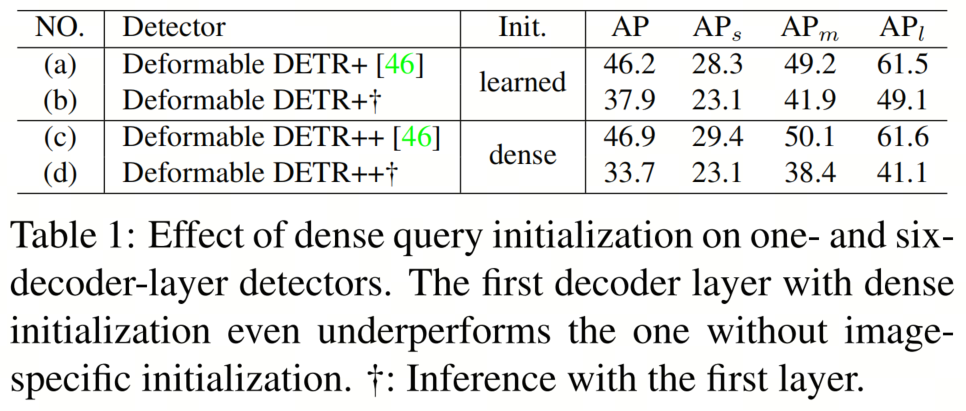
一些先前的研究发现,利用密集的Box预测步骤作为Query 初始化对于具有6个解码器层的检测器是有帮助的。例如,Deformable DETR++在表1中表现出比Deformable DETR+ 高0.7 AP。然而,令人惊讶的是,本文发现具有更好初始化的第一个解码器层甚至表现不如具有图像不可知初始化的解码器层,如表1中的(b)和(d)所示。这种现象表明,对于具有6个解码器层的检测器,来自密集Box预测步骤的好处不在于更好的初始化,而在于对编码器的更多监督信号,正如许多研究所发现的,一对一的匹配对于特征学习是不足够的。

为了更好地说明上述现象,在图3中可视化了编码器中的可辨识性得分,这些得分是对应网格特征的l2-范数。具有更高可辨识性得分的目标可以更好地被检测到。由于密集检测器基于网格特征来预测目标,而稀疏检测器使用Query 来检测目标,架构上的差异使所需的特征完全不同。
如图3所示,稀疏检测器更关注背景信息而不是密集检测器。此外,密集检测器更喜欢均匀激活整个目标,因为每个网格都有同等机会来预测目标,而稀疏检测器倾向于突出一些有区别的部分。带有密集初始化的稀疏检测器的分数图位于密集和稀疏检测器之间。由于具有6个层的强大解码器,具有密集初始化的这种检测器可以容忍特征的差异,并受益于更多的正信号。
然而,具有有限表示能力的一个解码器层的检测器会遇到特征冲突。本文假设这就是为什么具有良好初始化的Query 的一个解码器层的检测器仍然落后于具有6个解码器层的检测器的原因。这种现象也证明了6个解码器层的检测器中存在冗余,可以减少以加速。因此,本文提供了一种稀疏方法,进一步缩小了一个解码器层和6个解码器层检测器之间的性能差距,并保留了一个解码器层检测器的快速速度。
4、本文方法
4.1、Overview
在本节中,本文介绍了本文的自适应稀疏Anchor生成器(简称ASAG),它以稀疏方式初始化Query ,更适用于稀疏解码器,同时保持快速速度。如图2所示,ASAG从位置和数量的角度自适应地生成图像特定的Anchor,而不使用预定义的空间先验。与复杂的解码器不同,本文的ASAG非常轻量,仅使用0.06G FLOPs。使用动态Anchor,本文使用RoIAlign生成内容Query ,因为初始化Box和内容Query 对于一个解码器层检测器非常重要。
此外,还使用了额外的自注意层来建模目标之间的关系,并减少了无NMS的冗余,类似于Featurized QRCNN。最后,使用了任何类型的一个解码器层来进行最终的细化。
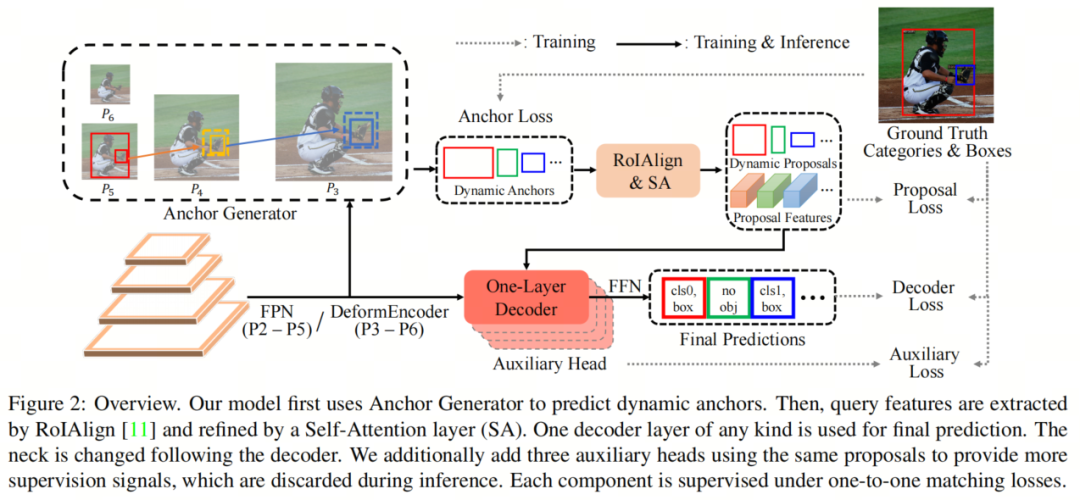
最近的研究表明,稀疏检测器受益于充分的监督信号。考虑到密集方法为每个网格提供监督信号,而其他6个解码器层的检测器具有更多的辅助损失,本文额外添加了3个辅助的并行的一个解码器层,以进行公平比较。因此,本文的模型也通过6个一对一匹配损失进行监督。与使用不同Query 组和每个组的共享解码器的Group DETR 不同,本文使用相同的建议与不同的解码器。
4.2、自适应稀疏Anchor生成器
使用图块作为更好的预测单元
在这项工作中,本文将图块作为基本的预测单元,从中将预测可能的Anchor。图块是整个或部分图像,可能包含许多目标,并且比网格或感兴趣的区域大得多。因此,从图块进行预测减轻了由于从网格进行预测而引起的特征差异,并享受全局感受野。
使用固定数量的特征图进行推理
本文从使用固定数量的特征图来预测所有目标开始演示本文的方法,即P5和P6。如图4的上半部分所示,以P5特征图作为输入,本文首先沿通道维度压缩特征图以节省计算和参数。为了处理不同尺寸的图像,本文将P5插值到固定尺寸,然后将其均匀分成4个图块,从左上到右下,以缩小预测器的搜索空间。如果本文直接将整个P5特征图视为单个图块,模型往往会忽视一些小目标。
考虑到一些大目标可能跨越图块,P6特征图用于处理这个问题,它是从P5插值后下采样2倍的结果,并被视为单个图块(褐色图块)。本文使用MLP作为预测器,同时在每个图块上预测一定数量的Anchor,每个Anchor由4个坐标和1位置分数描述。位置分数可以看作是类概率,因此是与类别无关的,并由IoU进行监督,作为软标签。
使用动态数量的特征图进行推理
由于P5不足以预测小目标,使用尺寸更大的特征图可以获得更精确的Anchor。受QueryDet的启发,本文提出了使用自适应检测来在大特征图上稀疏计算,以校正置信度较低的小目标的Anchor。
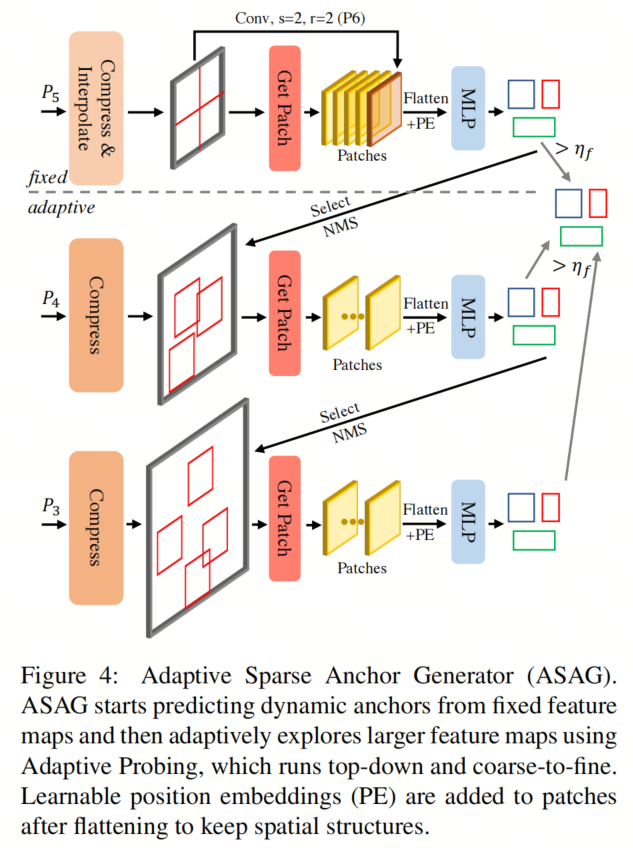
如图4的下半部分所示,本文选择从固定部分预测的一些Anchor,其置信度在
之间,并且大小小于图块大小的一半。得分低于
的Anchor被视为噪声Anchor,得分高于
的Anchor足够准确。因此,这些Anchor不用于自适应探测。使用选定的Anchor,本文在P4特征图上裁剪一些图块,其中心是相应Anchor的中心。
由于图块可能会彼此重叠,因此本文使用IoU阈值
进行NMS以减少冗余。从更高分辨率特征图预测的Anchor比原始Anchor更精确,因此本文将它们替换为新生成的Anchor。这种探测迭代会继续在以下更大的特征图上执行,直到最大的特征图P3。
本文凭经验发现,此外使用P2会带来轻微的改进,但会增加更多的推理时间。一旦不再选择Anchor,迭代将通过早期停止机制终止。因此,探测是自适应于迭代次数,图块数量和图块位置的数量。最后,所有得分高于
且未被选择进行自适应探测的Anchor都被收集起来。考虑到模型需要处理不同难度的图片,生成的图块数量和Anchor数量相应地变化。本文对输出的Anchor进行填充,以进行并行处理。
训练ASAG
本文首先定义了三种类型的图块:
-
生成的图块,这些图块是从选定的Anchor生成的
-
GT图块,这些图块是通过将小于图块大小一半的真实框进行分组获得的
-
随机图块,这些图块是随机生成的
为了确保每个金字塔层的预测器得到充分和平等的训练,本文为每个层定义了一个最小的训练图块数
,因为较低的层由于早停机制往往会接收较少的监督信号。对于从P5到P3的特征图,本文轮流使用生成的图块、GT图块和随机图块,直到满足最小图块数量为止。
对于P6,由于本文将整个特征图视为单个图块,本文将图块水平和垂直翻转以满足最小图块数量。只有从具有置信度得分高于ηf的生成图块生成的Anchor被收集并发送到后续的模型部分。每个图块的目标目标是其中心位于图块内的目标。由于输出的Anchor是无序的,本文使用二分图匹配来获得一对一的匹配,与本文模型的其他部分和其他稀疏检测器类似,只是它是与类别无关的。此外,本文使用真实框与匹配Anchor之间的IoU作为软标签。
与相关工作的关系
自适应探测在大特征图上稀疏计算,以节省计算量,类似于PointRend和QueryDet。然而,两者都是密集预测方法,明确知道在较大的特征图上探测的位置,而本文则稀疏地找到相应的位置。
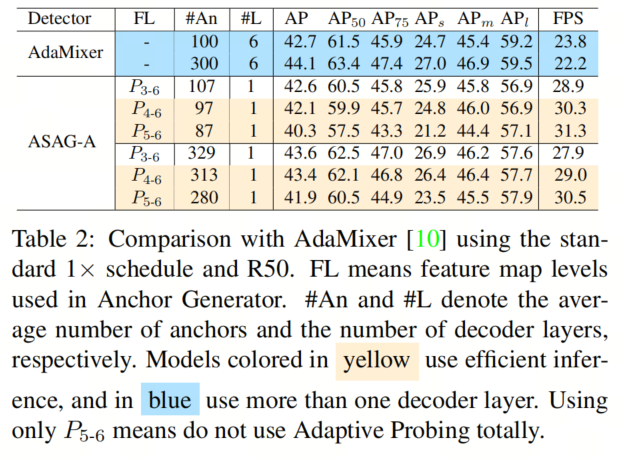
此外,QueryDet以分治方式预测目标,而自适应探测则是以校正和替换的方式,因此本文可以享受到早停机制。本文甚至可以手动丢弃大的特征图以进行高效的推理,如表2所示。
4.3、Stablizing Training
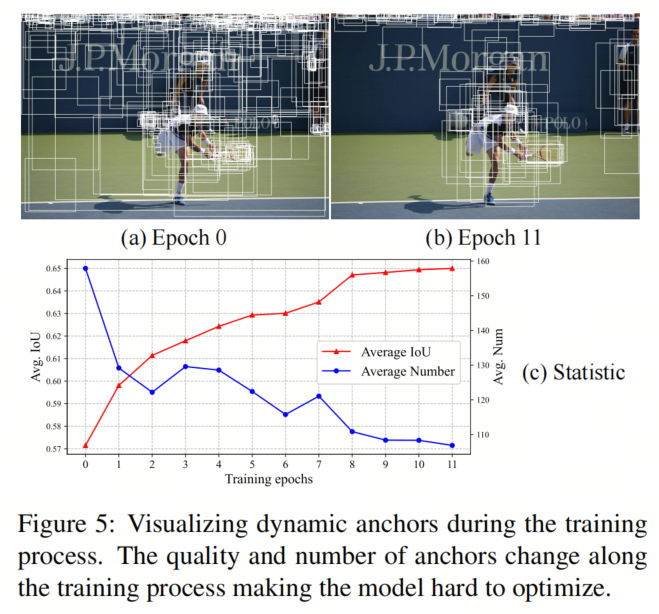
通过上述的新设计,本文有效地获得了自适应稀疏的Anchor和提议。然而,如图5所示,本文发现本文的动态Anchor具有两个与传统手工Anchor显著不同的特点:
-
动态Anchor在早期训练阶段可能不如预定义的Anchor精确
-
动态Anchor在训练过程中既在质量上变化,又在数量上变化,使得检测头难以优化。将0.1和0.9的IoU的两个Anchor视为相等是不合适的,因为它会让检测器对正样本的定义产生困惑。
因此,本文提出了Query 加权来通过给予质量较高的Anchor较大的权重,反之亦然,从而减轻训练的难度。软标签使检测器更加关注精确的预测,在动态Anchor变化时,尤其是在早期训练过程中,可以稳定训练。这种简单的加权机制不会增加推理成本。
受到DW给予多样化的正负损失权重的启发,本文的权重函数如下:
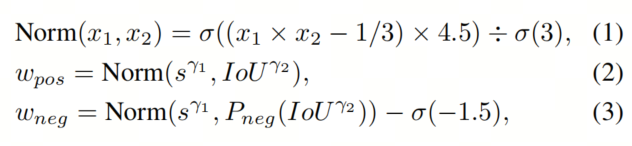
其中s和IoU分别是分类得分s和IoU,
与DW中的函数相同,
表示
函数。在归一化后,正权重大致在[0.2, 1]之间,负权重在[0, 0.8]之间。由于
函数是非线性的,它会提高小的值,但仍将它们保持在[0, 1]之间。即使匹配的Anchor与目标没有重叠,本文也不能将正权重分配为零,因为在一对一的标签分配中不会分配其他Anchor给目标。本文避免将负权重分配给唯一匹配的Anchor。这些权重仅适用于损失,而不适用于匹配成本。
与密集检测器中的标签加权方法不同,后者通过给予每个真实目标候选包内更合适的Anchor更大的权重,来使回归和分类头对齐,Query 加权则是为了容忍训练过程中的动态Anchor。
因此,本文的Query 加权是全局性的,而标签加权是实例级的。本文在第5.5节中展示,6解码层检测器不受Query 加权的益处,因为它们是从固定Query 中回归的。
4.4、损失函数
在这项工作中,本文在Anchor生成器中将图像块作为基本的预测单元。本文独立地为每个图像块计算二分图匹配和损失,每个图像块的目标是中心位于图像块内的物体。
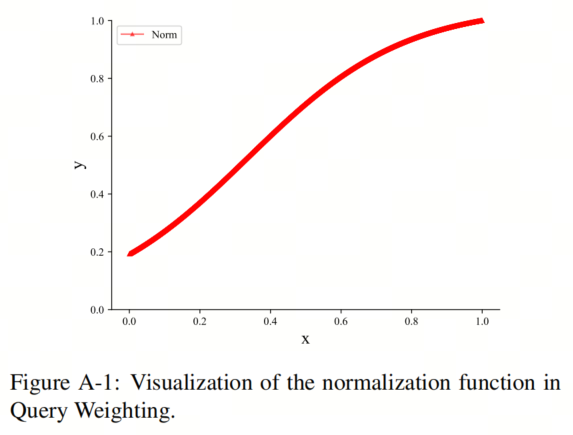
此外,本文提出了Query 加权(Query Weighting)来稳定训练过程,它给予质量较高的Anchor更大的权重,反之亦然。规范函数如图A-1所示。图片中的变量x是主文本中Equ.(1)中
和
的乘积。单调递增的规范化函数提高了小值并使它们保持小于1。
与其他DETR类似的模型一样,本文使用带有Query 加权的L1损失和GIoU损失进行边界框回归:
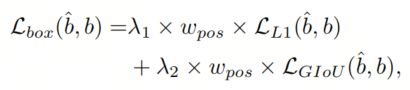
其中
和b分别是GT和预测的边界框。
和
设置为5和2。
在主文本的Equ.(2)中定义。对于负样本的分类损失是
,对于正样本的分类损失定义如下:
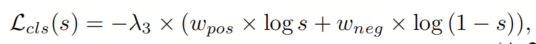
其中s是与相应类别相关的分类得分,
设置为2。
在主文本的Equ.(3)中定义。特别地,用于Anchor生成器的分类损失中的
设置为IoU,因为动态Anchor是与类别无关的,位置分数应与选择的IoUs高度相关。总损失是所有组件的总和:
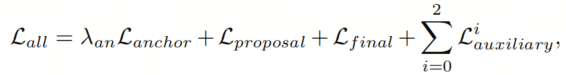
与损失不同,二分图匹配中的匹配成本不使用Query 加权。
5、实验
5.1、主要结果
在标准的1×调度下进行比较
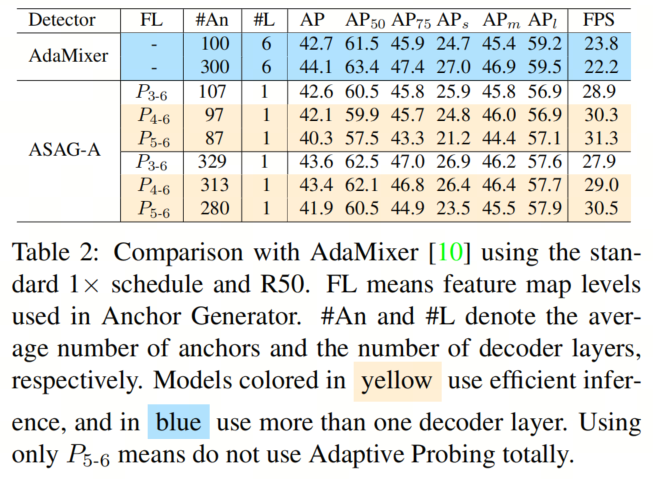
本文首先在几个时期内公平地比较了ASAG-A与AdaMixer。如表2所示,尽管在早期动态Anchor在改变并且不精确,但Query 加权稳定了训练,ASAG-A在12个时期内仍然收敛,并实现了与6解码层的AdaMixer相当的结果,速度提高了1.25×。由于自适应探测是以迭代的方式进行的,并且是正确的并替代的方式,本文可以手动停止在特定级别以进行有效的推理,而无需重新训练。请注意,高效的推理不会损害大目标的性能。
与单解码层检测器的比较
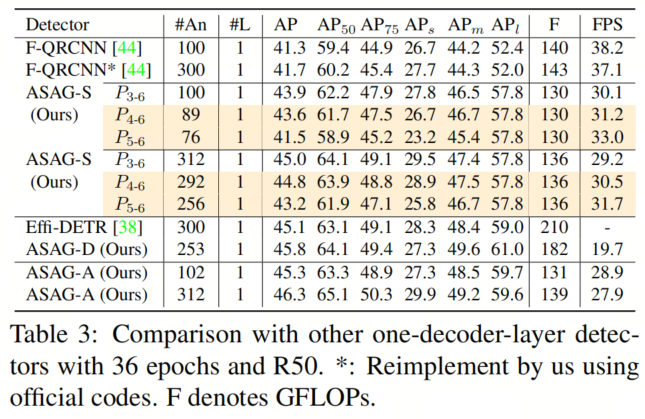
由于Anchor生成器减轻了由于从网格进行预测而引起的特征差异,ASAG-D在表3中表现出色,比Efficient DETR高出0.7 AP,ASAG-S比Featurized Query RCNN高出2.6 AP,显示出ASAG的有效性。此外,与在大型特征图上密集计算不同,ASAG稀疏地选择不同特征图上的Patch,节省了大量计算。
此外,由于P6上的Patch是整个图像,ASAG具有全局感受野,相对于密集(网格)初始化的模型,带来了更高的APl。
与相同解码器类型的6解码层检测器的比较
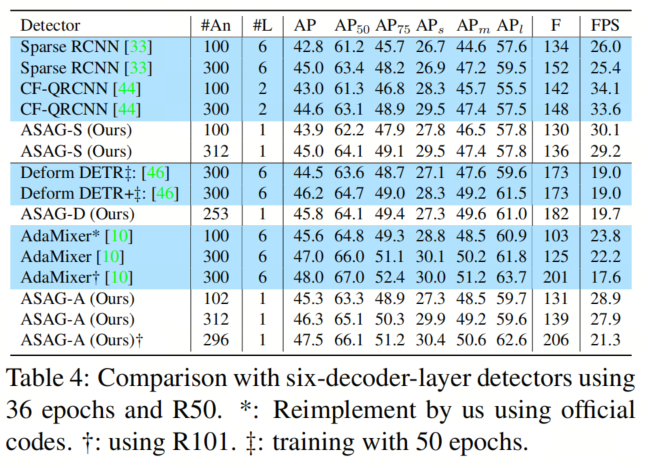
如表4所示,虽然现有的带有密集初始化的单解码层检测器在性能上远远落后于其6解码层的对应模型,但本文的模型极大地缩小了性能差距。特别是,本文的ASAG-S甚至在100个Query 设置下的性能优于Sparse RCNN,而速度更快,FLOPs更少。
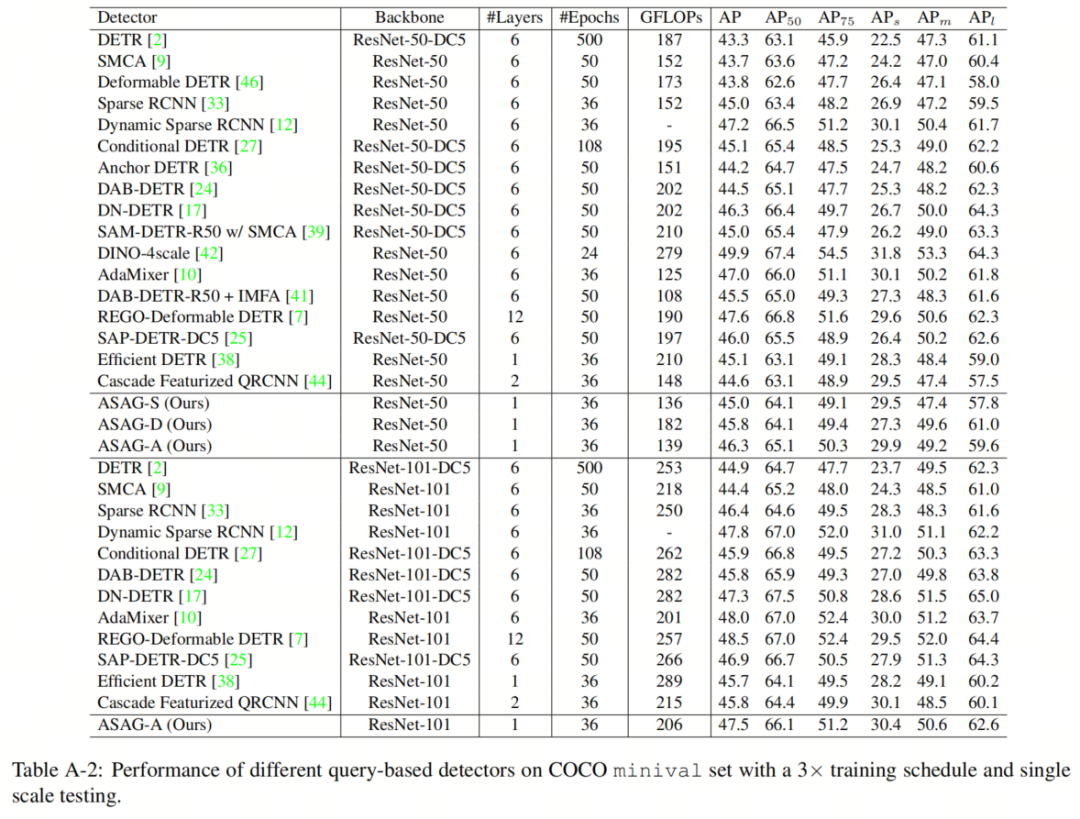
在这项工作中,本文的目标是通过自适应稀疏Anchor生成来缩小单解码器层和6解码器层检测器之间的性能差距,并保持快速速度。因此,本文模型的性能与基线密切相关。然而,仅具有一个解码器层和更少FLOPs的ASAG与众所周知的检测器相比,性能仍然令人鼓舞,如表A-2所示。
请注意,一些SOTA方法提出了一些高级的训练技巧,而不是新颖的解码器结构,这些技巧也可以提升ASAG的性能,例如去噪训练、更多的正样本、知识蒸馏。在表A-1中,本文根据DN-DETR的方法,为ASAG-A配备了200个噪声Query 。结果显示,去噪训练也可以使本文的方法受益。
5.2、消融实验
本文使用ASAGA进行了下列消融研究,使用R50,100个Query 和1×的训练计划,因为其快速的收敛速度。
主要组件
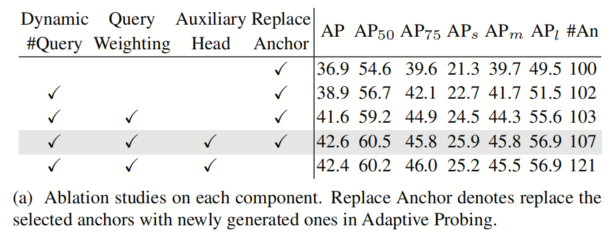
在表5a中,本文去除了模型中引入的主要组件。首先,由于使用不同特征图预测的Anchor使用不同的预测器无法平等对待,所以使用基于分数的动态Anchor而不是固定的topkAnchor更为合适,增加了2.0AP。从最后一行本文还发现,在自适应探测中保留所选Anchor没有帮助,但具有更多的Anchor,表明在更大的特征图上生成的Anchor要比所选的要好,并且Anchor不能均匀地按分数排序。其次,Query 加权稳定了训练,并带来了2.7AP的增益。此外,提供充分的监督信号对于稀疏检测器至关重要,使用额外的辅助平行的单层解码器增加了1.0AP。
自适应探测的Patch大小

由于在不同特征图上剪裁的Patch独立地预测Anchor,因此每个级别的Patch大小可以不同。为了简单起见,本文在自适应探测中使用相同的大小,共享MLP预测器。在表5c中,大和小的Patch大小都不适合小目标。对于小的Patch大小,由于长度限制,自适应探测中选择的Anchor较少,从而减少了Patch的数量。而且,检测小型和中型物体需要相对较大的上下文。至于大的Patch大小,由于本文进行稀疏预测,没有使用空间先验,因此预测器忽略了一些小目标。
自适应探测的置信度阈值
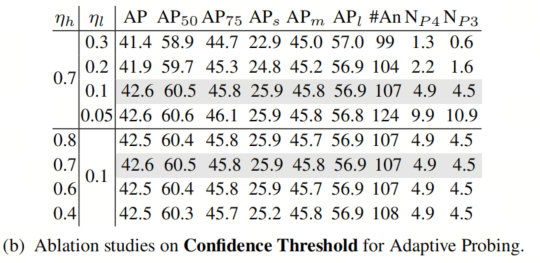
在表5b的上半部分,相对较高的
会忽略一些可能的小目标,因此导致较少的Anchor和Patch,从而在小目标上性能较差。低于0.1的阈值
是不必要的,因为置信度较低的Anchor往往是噪点Anchor。下半部分显示自适应探测对ηh是稳健的。请注意,自适应探测不会影响APl。
自适应探测的NMS阈值
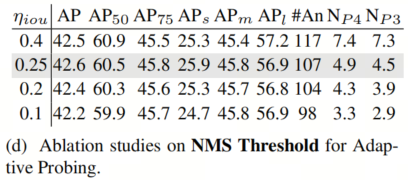
为了减少冗余,本文使用NMS来减少重叠的Patch,阈值会大大影响Patch的数量。在表5d中,较低的阈值会错误地减少一些有用的Patch。
AR的比较
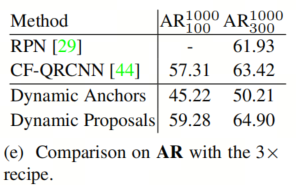
为了验证本文动态Anchor和动态提议的质量,表5e中比较了AR1000与著名的RPN中使用的QGN。AR1000 100表示AR1000在100个Query 设置下。尽管本文的模型缺少密集的先验,如Anchor框或Anchor,但从AR1000的角度来看,动态Proposals在性能上仍然优于RPN和QGN。而且本文的Anchor生成器只使用了0.06 GFLOPs。
动态Anchor数量的分布
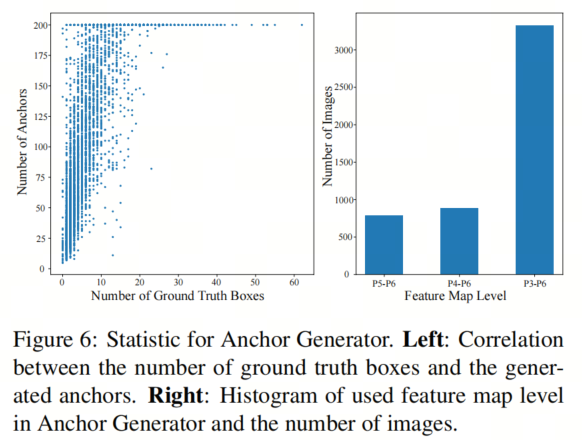
如图6左侧所示,图像的数量与生成的Anchor数量之间存在明显的正相关关系,表明Anchor生成器通过为难处理的图像生成更多的Query ,反之亦然。
使用的特征图级别的分布
本文的自适应探测方法享有早停机制。如图6右侧所示,在验证集中,大约40%的图像不使用所有的特征图,从而节省了一些计算。
自适应探测的超参数稳健性
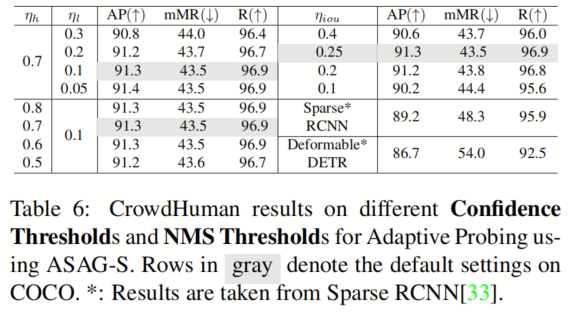
在自适应探测中,本文只选择那些置信度在
之间的Anchor来剪裁较大特征图上的Patch,而Patch则通过NMS与IoU阈值ηiou进行过滤,以减少冗余。
为了展示这些超参数的稳健性,本文遵循Sparse RCNN在CrowdHuman数据集上进行了实验,该数据集与COCO有很大不同。与Sparse RCNN一样,本文在50个时期内运行ASAG-S,平均每500个Anchor之间的数量。如表6所示,COCO上自适应探测的默认超参数在CrowdHuman上仍然有效。而且ASAG-S在性能上远远优于Sparse RCNN和Deformable DETR。
5.3、可视化对比
特征图的比较。在这项工作中,本文提供了一种稀疏的方法来初始化目标Query ,即使用Patch作为预测单元,从而减轻了通过在网格上进行预测引起的特征图不一致性。如图7所示,本文的方法生成的特征图更类似于具有6个解码器层的稀疏检测器,它们以自适应的方式激活目标,而不是均匀激活。

自适应探测的可视化
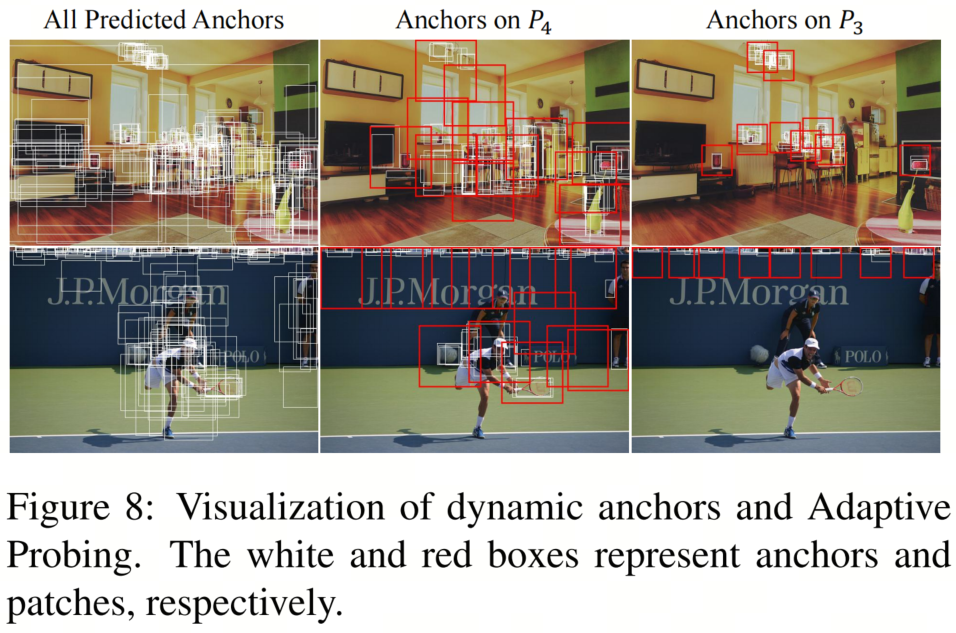
本文可视化了一些结果,以了解Anchor Generator的工作原理。更多的图片将显示在补充材料中。在图8中,本文以白色绘制了动态Anchor,以红色绘制了Patch。如第一列所示,不同图像的Anchor是不同的,并且已经覆盖了大多数前景目标,显示它们确实是自适应和精确的。通过自适应探测,Anchor Generator倾向于为小目标生成更多的Anchor,这极大地增强了检测小目标的能力。尽管红色框,即Patch,在图像上稀疏分布,但它们精确覆盖了小目标,如桌子上的物品和看台上的观众,大大提高了召回率。

在图C-2中,本文可视化了ASAG-A流程中出现的所有边界框。Anchor精确地覆盖了前景目标,自适应探测在大特征图上稀疏地进行探索。根据不同的图像,Patch的数量和位置都会有所不同。特别是最后一个图像由于没有小目标,通过早停机制不使用自适应探测。凭借精确的Anchor,最终的预测与真实值非常接近。对于第一个图像,本文甚至可以为书架上的书预测比真实值更精细的边界框。
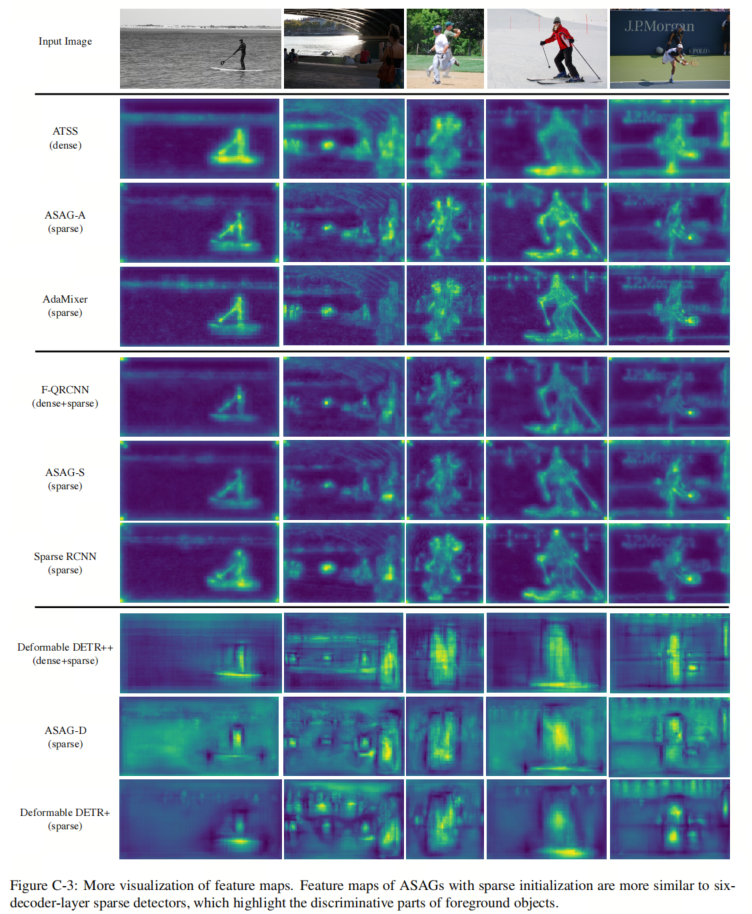
在图C-3中,本文将本文模型的特征图与相应的具有6个解码器层的稀疏检测器和密集初始化的检测器进行了比较。与均匀激活整个目标的密集初始化方法不同,ASAG突出了目标的判别性部分,并更多地关注背景,与具有6个解码器层的稀疏检测器类似。
5.4、讨论与分析
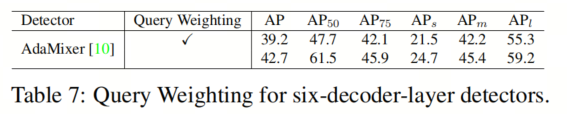
Query 加权是否有益于6解码器层检测器?
大多数六解码器层检测器和密集检测器都是从与图像无关且固定的Query (或Anchor)中检测目标的。初始Query 的质量在训练过程中无法改进。因此,每个解码器层应该在不同的IoU水平下进行训练[1],而Query 加权对它们没有好处,如表7所示。
增加相同数量的Anchor对一解码器层和六解码器层检测器是否相等?
由于六解码器层检测器可以很好地处理与图像无关且固定的Query ,因此Query 初始化对它们的帮助较小。但对于它们来说,增加Query 只是缩小了每个Query 的搜索空间。然而,Query 初始化对一解码器层检测器至关重要,直接影响其性能。如表5e所示,将Query 从100增加到300仅增加了5.6的AR,因为前100个建议已经包含在前300个中。因此,对于一解码器层检测器来说,增加Query 的好处小于六解码器层检测器,如表2和表4所示。如何扩展一解码器层检测器需要未来的研究。
关于APl的更多分析
类似DETR的检测器的一个核心优势是它们进行全局推理,因此APl要明显高于传统检测器。然而,尽管本文的ASAG在AP上与相应的六解码器层检测器相媲美,但APl仍然落后于它们,如表4所示。似乎APl在使用更多Query 时也不能像对应的检测器那样提高。在这里,本文提供一些分析。
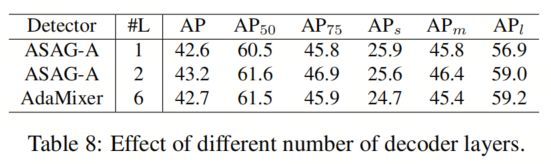
APl受两个因素影响:解码器层数和Query 初始化。关于解码器层数,本文在表8中运行了一个具有两个解码器层的ASAG-A,获得了43.2AP和59.0APl(与一层的42.6AP和56.9APl相比),其中APl已经与AdaMixer相媲美。至于Query 初始化,ASAG在P6中将整个图像视为一个Patch,并从中初始化Anchor,在初始化过程中享有全局感受野的优势,因此在APl上表现优于密集初始化的一解码器层检测器,如表3所示。
此外,APl不随更多Query 而提高的现象也发生在另一个一解码器层检测器中,显示这不是特定于ASAG。由于一解码器层检测器使用与图像特定的Query ,而大型目标相对容易检测,初始Query 已经足够精确,因此增加Query 仅为大型目标带来了一点召回率。相反,六解码器层检测器的Query 是随机初始化的。因此,在使用更多Query 时,一解码器层检测器的APl增益较小。
6、参考
[1]. ASAG: Building Strong One-Decoder-Layer Sparse Detectors via Adaptive Sparse Anchor Generation.
7、推荐阅读
ExMobileViT | 优化轻量化ViT的不二选择,源于MobileViT又高于MobileViT!
LSKA注意力 | 重新思考和设计大卷积核注意力,性能优于ConvNeXt、SWin、RepLKNet以及VAN
大模型系列 | 两张3090显卡就可以玩起来医疗SAM-LST大模型

扫码加入👉「集智书童」交流群
(备注:方向+学校/公司+昵称)




前沿AI视觉感知全栈知识👉「分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF」
欢迎扫描上方二维码,加入「集智书童-知识星球」,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!