
线性Attention的探索:Attention必须有个Softmax吗?

极市导读
通过去掉标准attention中的softmax,可以使之成为线性化attention,降低其复杂度。本文即介绍了这一方法的原理和优点。

1 Attention
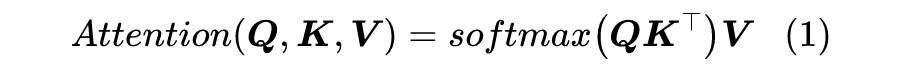
这里的 ,简单起见我们就没显式地写出 Attention 的缩放因子了。
1.1 摘掉Softmax
读者也许想不到,制约 Attention 性能的关键因素,其实是定义里边的 Softmax!事实上,简单地推导一下就可以得到这个结论。
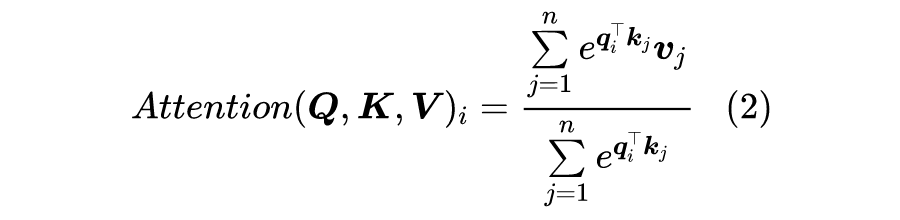
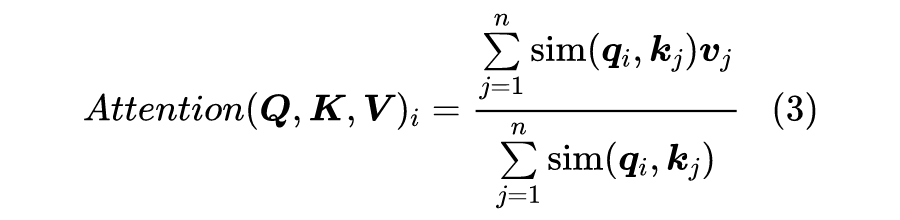
2 几个例子
2.1 核函数形式
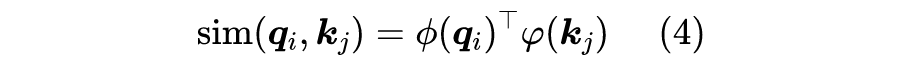
2.2 妙用Softmax
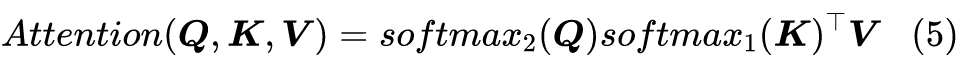
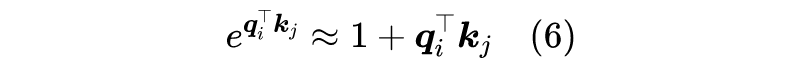
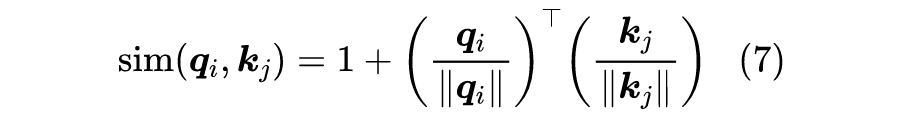
3 相关工作
3.1 稀疏Attention
但是很明显,这种思路有两个不足之处:
1、如何选择要保留的注意力区域,这是人工主观决定的,带有很大的不智能性;
2、它需要从编程上进行特定的设计优化,才能得到一个高效的实现,所以它不容易推广。
3.2 Reformer
3.3 Linformer
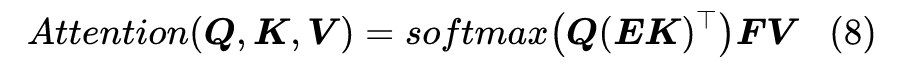
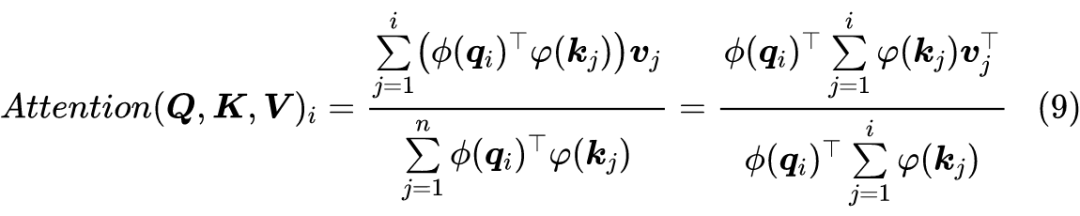
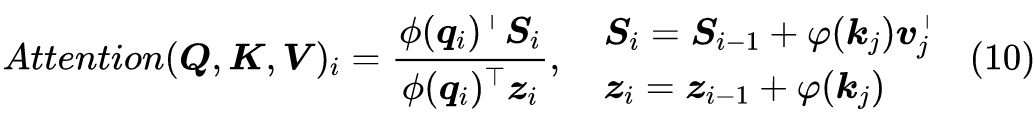
3.5 下采样技术
近来也有类似的工作发出来,比如IBM的PoWER-BERT: Accelerating BERT Inference via Progressive Word-vector Elimination [8] 和 Google 的 Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing [9] 。
4 文章小结
推荐阅读

评论