
CLIP 及其改进工作
1. CLIP
论⽂地址:https://arxiv.org/abs/2103.00020
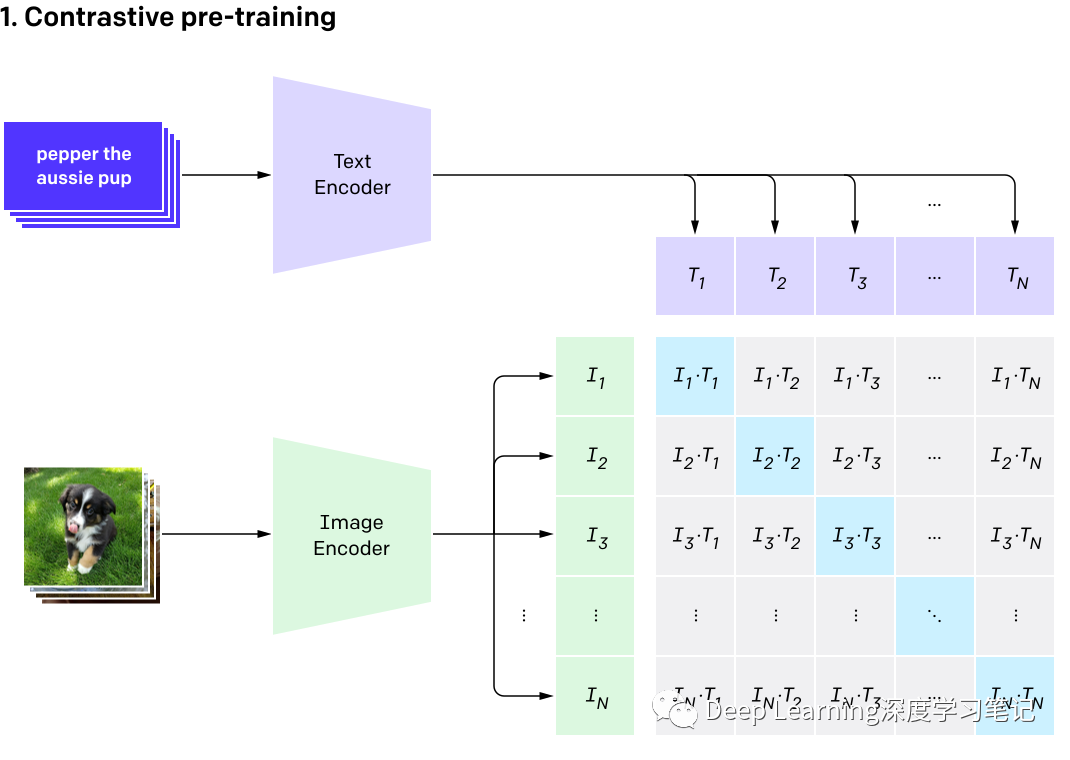
模型:对比学习,预测N*N对图文数据,将图片分类任务转换成图文匹配任务:
⽂本编码器( CBOW or Text Transform) ⽤ [SOS] token 和 [EOS] token 将句⼦包裹,[EOS] token 对应的输出视为句⼦的特征表示 Masked self-attention 作为辅助训练⽬标以保留预训练⽂本编码器的初始化能⼒(防⽌遗忘) 采⽤ Transformer 经典结构(源⾃ Atten-tion is all you need 论⽂) 基础模型 63M 参数量,8 个注意⼒头,⽂本宽度 512,12 层 transformer encoder token embedding:采⽤⼩写字节对编码( byte pair encoding,BPE),词表⼤⼩ 49152,最⼤句⼦ ⻓度为 76。 图像编码器( ResNet or Vision Transform) 改进策略:在 patch embedding 和 position embedding 之前采⽤ LN 改进策略:ResNet-D,antialiased rect-2 blur pooling,将全局池化替换为注意⼒池化机制 (attention pooling mechanism) 选择 ResNet-50 作为基础模型 选择 Vision Transformer
共有 5 个 ResNet 系列以及 3 个 Vision Transformers 系列
ResNet 系列包括 ResNet-50/ResNet-101,以及参考 EfficientNet 进⾏模型扩展。基于 ResNet-50 ⼤约进⾏ 4 倍,16 倍以及 64 倍计算扩展,分别称为 RN50x4, RN50x16, 以及 RN50x64 Vision Transformers 系列包括 ViT-B/32,ViT-B/16,ViT-L/14
1.1 模型训练细节
模型训练 epoch 均为 32 使⽤ Adam 优化器结合解耦权重衰减正则化(paper:Decoupled Weight Decay Regularization )以及使⽤ 余弦调度衰减学习率(paper:SGDR: Stochastic Gradient Descent with Warm Restarts ) 基于 ResNet50 的超参的初始化使⽤⽹格搜索和随机搜索 learnable temperature 参数 被初始化为 0.07 并剪裁以防⽌将 logits 缩放超过 100,作者认为这是防⽌训 练不稳定所必需的
decrease , the distribution becomes more peaky — values that were larger become even larger, and values that were smaller become even smaller. On the other hand, as you increase , the distribution becomes flatter — values that were larger become smaller, and values that were smaller become larger.
使⽤⼀个⾮常⼤的 batch size:32768 (Tips:在实际训练中使用 torch.distributed.nn.all_gather 进行 GPU 进程数据通信将推理结果汇总到一起就行 loss 计算)
使⽤混合精度进⾏训练以节省内存空间
半精度 Adam 优化器策略
⽂本编码器权重半精度随机取整
RN50x60 模型的训练在 592 个 V100 显卡上耗时 18 天
ViT-L/14 模型的训练在 256 个 V100 显卡上耗时 12 天
2. ViLT
论文地址:https://arxiv.org/abs/2102.03334
2.1 作者对 VLP 模型现状进行概括
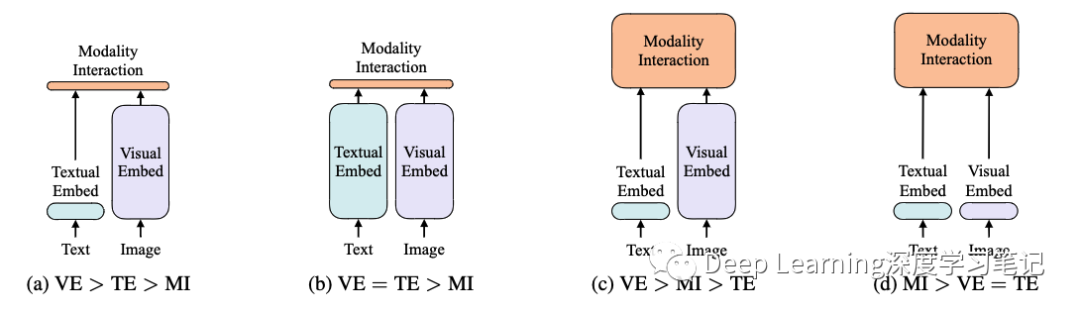
上图是 4 种不同类型的 VLP 模型示意图。
其中每个矩形的⾼表示相对计算量⼤⼩,VE、TE 和 MI 分别是 visual embedding(视觉嵌入)、text embedding(文本嵌入) 和 modality interaction(多模态交互) 的简写。
作者提出这 4 种类型的主要依据有两点:
在参数或者计算上,两种模态是否保持平衡。
在⽹络深层中,两种模态是否相互作⽤。
VSE、VSE++ 和 SCAN 属于 (a) 类型。对图像和⽂本独⽴使⽤ encoder,图像 encoder 参数量更大(可以通俗理解“更重”),⽂本更轻,使⽤简单的点积或者浅层 attention 层来表示两种模态特征的相似性。
CLIP 属于 (b) 类型。每个模态单独使⽤重的 transformer encoder ,使⽤池化后的图像特征点积计算特征相似 性。
ViLBERT、UNTER 和 Pixel-BERT 属于 (c) 类型。这些⽅法使⽤深层 transformer 进⾏交互作⽤,但是由于 VE 仍 然使⽤重的卷积⽹络进⾏特征抽取,导致计算量依然很⼤。
作者提出的 ViLT 属于 (d) 类型。ViLT 是⾸个将 VE 设计的如 TE ⼀样轻量的⽅法,该⽅法的主要计算量都集中在模态交互上。
2.2 Modality Interaction Schema
模态交互部分可以分成两种⽅式:
⼀种是 single-stream (如 BERT 和 UNITER ),另⼀种是 dual-stream (如 ViLBERT 和 LXMERT )。其中 single-stream 是对图像和⽂本 concate 然后进⾏交互操作,⽽ dual-stream 是不对图像和⽂本 concate 然后进⾏交互操作。ViLT 延⽤ single-stream 的交互⽅式,因为 dual-stream 会引⼊额外的计算量。
2.3 模型设计
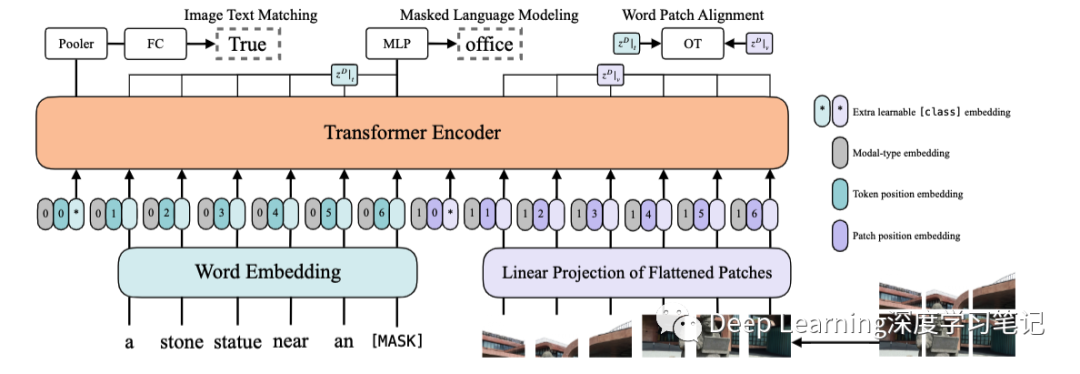
作者提出的 ViLT 可以认为是⽬前最简单的多模态 Transformer ⽅法。ViLT 使⽤预训练的 ViT 来初始化交互的 transformer,这样就可以直接利⽤交互层来处理视觉特征,不需要额外增加⼀个视觉 encoder。
⽂本特征输⼊部分,将⽂本看成⼀个词序列,通过 word embedding matrix 转化成word embedding,然后和 position embedding 进⾏相加,最后和 modal-type embedding 进⾏ concate。
图像特征输⼊部分,将图像切块看成⼀个图像块序列,通过 linear projection 转化成 visual embedding,然后和 postion embedding 进⾏相加,最后和 modal-type embedding 进⾏ concate 。
其中 word embedding 和 visual embedding 通过可学习的 modal-type embedding 标志位来区分,其中 0 位表示 word embedding 部分, 1 标志位表示 visual embedding 部分。
wrod embedding 和 visual embedding 分别都嵌⼊了⼀个额外的可学习class embedding ,⽅便和下游任务对接。
3. BLIP
论文链接:https://arxiv.org/abs/2201.12086
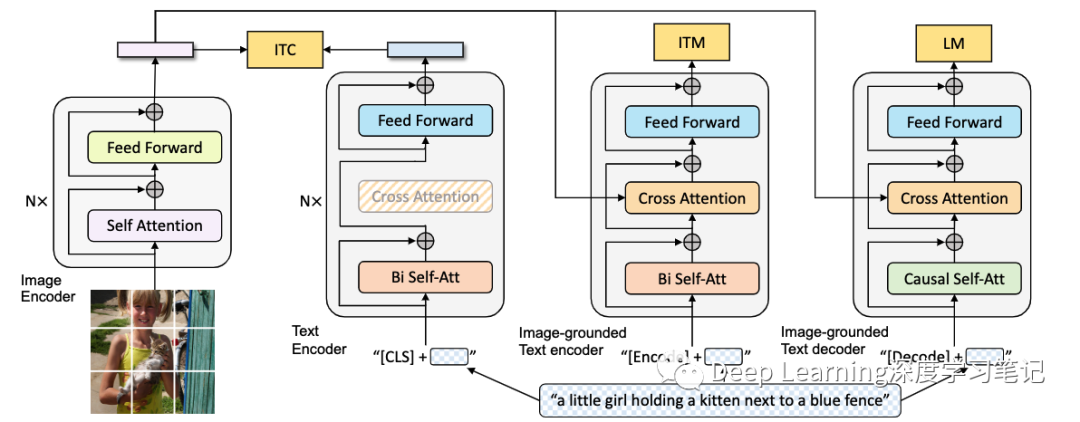
作者使用视觉 Transformer 作为图像编码器,该图像编码器将输入图像分成 patch,并将它们编码为嵌入序列,并带有额外的 [CLS] token 来表示全局图像特征。与使用预训练的目标检测器进行视觉特征提取相比,使用 ViT 更易于计算,并且已被较新的方法采用。
为了预训练一个既有理解能力又有生成能力的统一模型,作者提出了多模态混合编码器-解码器(MED),这是一个多任务模型,可以在以下三种结构之一中运行:
单模态编码器,分别对图像和文本进行编码。文本编码器与 BERT 相同,其中将 [CLS] token 附加到文本输入的开头以概括句子。
Image-grounded 文本编码器,通过在文本编码器的每个 transformer 块的自注意 (SA) 层和前馈网络 (FFN) 之间插入一个额外的交叉注意 (CA) 层来注入视觉信息。文本中附加了一个特定于任务的 [Encode] token,[Encode] 的输出嵌入被用作图像-文本对的多模态表示。
Image-grounded 文本解码器,将基于图像的文本编码器中的双向自注意力层替换为因果自注意力层。[Decode] token 用于表示序列的开始,而 [EOS] token 用于表示其结束。
3.1 Pre-training Objectives
作者在预训练期间共同优化了三个目标,其中两个基于理解的目标和一个基于生成的目标。每个图像-文本对仅需要一次通过计算较重的视觉 Transformer 的正向传递,而三次通过文本转换器的正向传递,以激活不同的结构以计算如下所述的三个损失函数。
图像文本对比损失 (ITC) 激活单模态编码器。其目的是对齐视觉 transformer 和文本 transformer 的特征空间,通过鼓励正图像-文本对具有相似的表示来实现。事实证明,这是提高视力和语言理解的有效目标。
图像文本匹配损失(ITM)激活图像文本编码器。它的目的是学习图像-文本多模态表示,捕捉视觉和语言之间的细粒度对齐。ITM 是一个二分类任务,给定其多模态特征,模型使用 ITM 头 (线性层) 来预测图像-文本对是正 (匹配) 还是负 (不匹配)。
语言建模损失(LM)激活 image-grounded 文本解码器,该解码器旨在生成给定图像的文本描述。它优化了交叉熵损失,从而训练模型以自回归方式最大化文本的可能性。在计算损失时,作者采用 0.1 的标签平滑。与广泛用于 VLP 的 MLM 损失相比,LM使模型具有将视觉信息转换为连贯字幕的泛化能力。
为了在利用多任务学习的同时进行有效的预训练,文本编码器和文本解码器共享除 SA 层之外的所有参数。原因是编码和解码任务之间的差异最好由 SA 层捕获。尤其是,编码器采用双向自注意来构建当前输入 token 的表示,而解码器采用因果自注意来预测下一个 token。另一方面,嵌入层、CA 层和 FFN 在编码和解码任务之间的作用类似,因此共享这些层可以提高训练效率,同时受益于多任务学习。
3.2 CapFilt
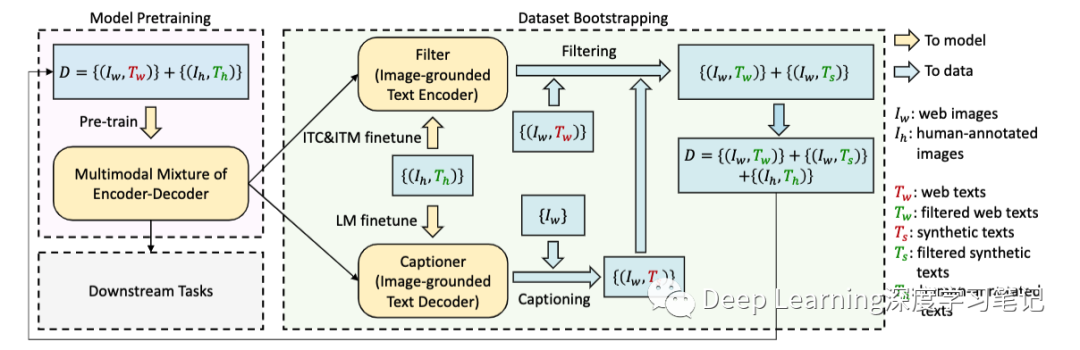
由于高昂的标注成本,存在有限数量的高质量人工标注图像文本对 ,如 COCO。最近的研究利用了大量从网络上自动收集的图像和文本对。但是,这些文本通常无法准确描述图像的视觉内容,从而使它们成为嘈杂的信号,对于学习视觉语言对齐不是最佳的。
作者提出了字幕和过滤(Captioning and Filtering,CapFilt),这是一种提高文本语料库质量的新方法。上图给出了 CapFilt 的图示。它引入了两个模块:一个用于生成给定 web 图像的字幕的字幕器,以及一个用于去除噪声图像-文本对的过滤器。字幕器和过滤器都是从同一个预训练过的 MED 模型中初始化的,并在 COCO 数据集上单独微调。微调是一个轻量级的过程。
具体地说,字幕器是一个基于图像的文本解码器。它与 LM 目标相结合,对给定图像的文本进行解码。给定 web 图像,字幕器生成合成字幕。过滤器是一个基于图像的文本编码器。它与 ITC 和 ITM 的目标相结合,以了解文本是否与图像匹配。
过滤器会去除原始 web 文本和合成文本中的噪声文本,如果 ITM 头预测文本与图像不匹配,则该文本被视为噪声文本。最后,作者将过滤后的图像-文本对与人类标注对结合起来,形成一个新的数据集,并使用该数据集预训练一个新模型。
