
StyleGAN-NADA:CLIP + StyleGAN
点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
来源:GitHub 编辑:LRS 文章:新智元
【新智元导读】零样本的风格迁移听说过没有?英伟达一个实习生小哥集文本CLIP和图像生成StyleGAN于一身,只需要输入几个单词就可以完成你想要的风格迁移效果!再也不用为了风格迁移找数据啦!


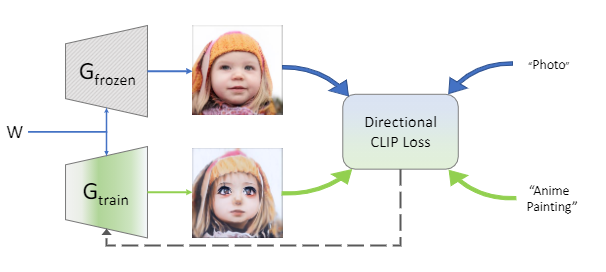
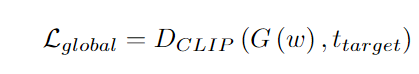

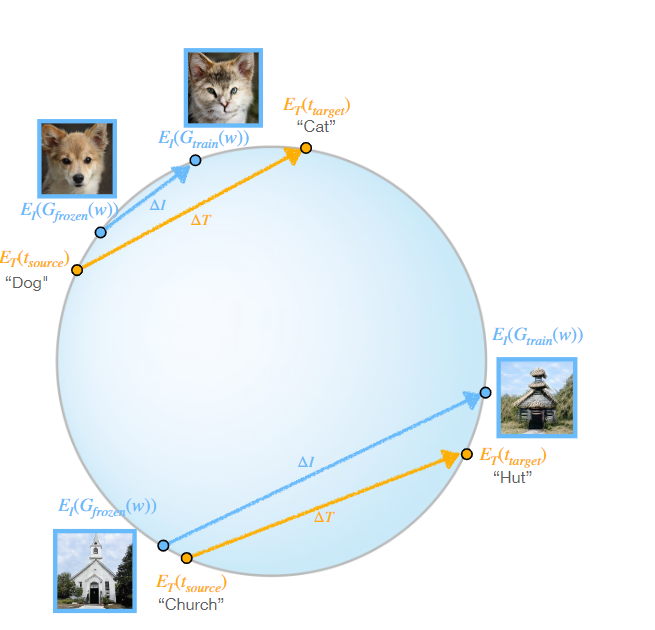


参考资料:
https://stylegan-nada.github.io/
猜您喜欢:
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!
评论