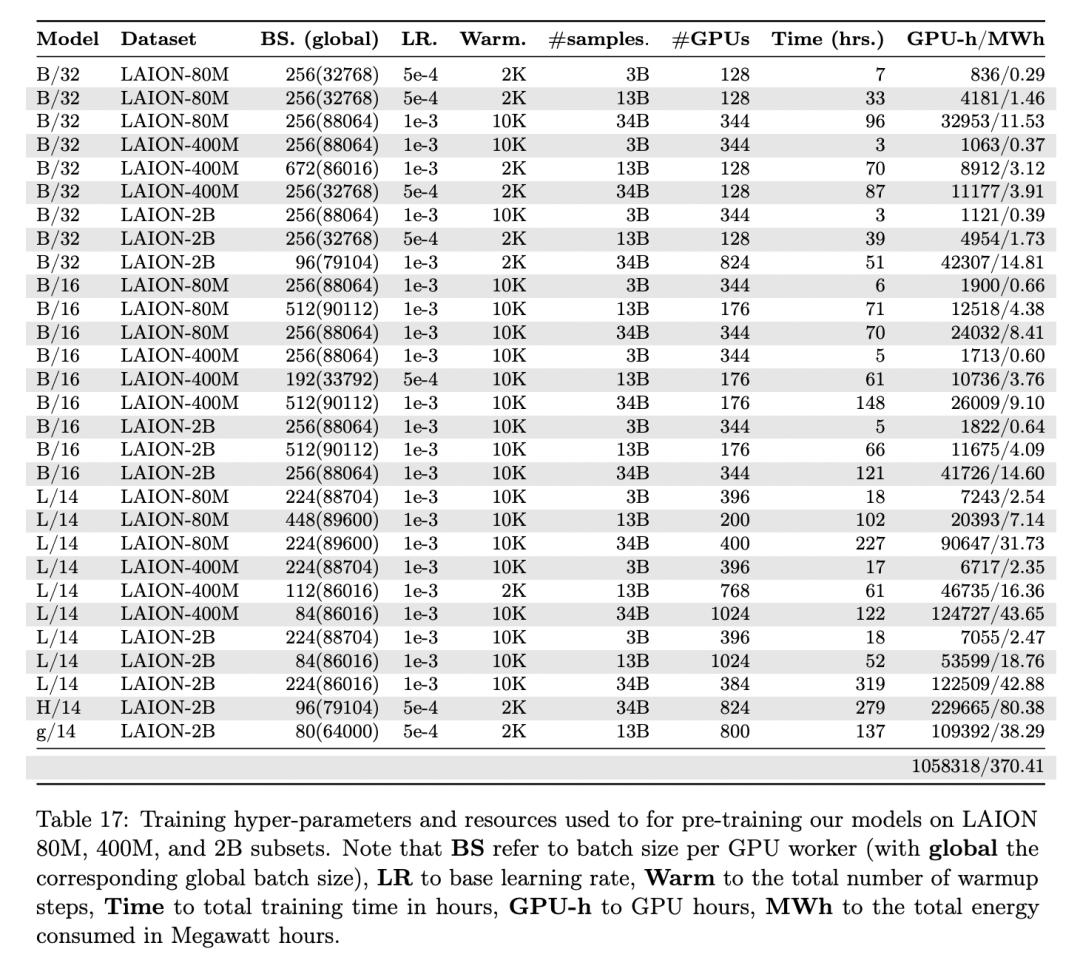
最大CLIP!LAION发布CLIP的扩增定律机器学习算法工程师关注共 1186字,需浏览 3分钟 ·2022-12-22 15:14点蓝色字关注“机器学习算法工程师”设为星标,干货直达!近日,LAION等机构在Reproducible scaling laws for contrastive language-image learning发布了CLIP的扩增定律(scaling law),其中最大的CLIP为ViT-H/14,基于LAION-2B数据集训练,可以在ImageNet1K数据集上到78.0%的zero-shot准确度,性能超过OpenAI目前开源的CLIP L/14,和Meta AI的FLIP Huge模型性能相当,但是模型已经开源在https://github.com/LAION-AI/scaling-laws-openclip。论文的实验采用开源数据集LAION-400M和LAION-2B数据集,训练框架采用开源的OpenCLIP,所以论文的实验是可以复现的。训练在1520 NVIDIA A100 GPUs上进行,采用PyTorch DDP分布式训练策略,采用混合精度(但是fp16会不稳定,所以采用bf16,或者基于TF32的float32),训练的batch size在 86-88K之间。实验的总体结论是:扩增定律也明显适用CLIP,当扩增模型,训练数据和算力时,模型在下游任务上有一致性的提升。但是不同的训练数据集表现出不同的扩增系数:OpenCLIP的模型(基于LAION-2B数据集)在图文检索任务上有较大的扩增系数,而OpenAI CLIP模型(基于私有的WebImageText 400M数据集)在zero-shot分类任务上有较强的扩增系数。这个结论和FLIP的结论比较吻合,这说明训练数据集对CLIP的性能确实有比较大的影响。用论文结论的一句话来说就是:Scaling behavior depends on task type and pre-training dataset。更多内容可见论文:https://arxiv.org/abs/2212.07143推荐阅读深入理解生成模型VAEDropBlock的原理和实现SOTA模型Swin Transformer是如何炼成的!有码有颜!你要的生成模型VQ-VAE来了!集成YYDS!让你的模型更快更准!辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!SimMIM:一种更简单的MIM方法SSD的torchvision版本实现详解机器学习算法工程师 一个用心的公众号浏览 194点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 StyleGAN-NADA:CLIP + StyleGAN机器学习与生成对抗网络0CLIP 及其改进工作Deep Learning深度学习笔记0animate clip style propertyQuick "plugin" to support animation of the CSS styanimate clip style propertyQuick"plugin"tosupportanimationoftheCSSstyle.clippropertyviathejQuery.fn.animate()facilityinthesamevOpenAI CLIP 论文解读GiantPandaCV0图文模态交互 | CLIP + GAN = ?机器学习与生成对抗网络0CLIP 引爆多模态方向!公众号CVer0YOLOv5 + CLIP = 搜图 + 裁剪机器学习与生成对抗网络0App Clip 离落地有多远?逆锋起笔0[LLaVA系列]CLIP/LLaVA/LLaVA1.5/VILA笔记GiantPandaCV1点赞 评论 收藏 分享 手机扫一扫分享分享 举报
近日,LAION等机构在Reproducible scaling laws for contrastive language-image learning发布了CLIP的扩增定律(scaling law),其中最大的CLIP为ViT-H/14,基于LAION-2B数据集训练,可以在ImageNet1K数据集上到78.0%的zero-shot准确度,性能超过OpenAI目前开源的CLIP L/14,和Meta AI的FLIP Huge模型性能相当,但是模型已经开源在https://github.com/LAION-AI/scaling-laws-openclip。论文的实验采用开源数据集LAION-400M和LAION-2B数据集,训练框架采用开源的OpenCLIP,所以论文的实验是可以复现的。训练在1520 NVIDIA A100 GPUs上进行,采用PyTorch DDP分布式训练策略,采用混合精度(但是fp16会不稳定,所以采用bf16,或者基于TF32的float32),训练的batch size在 86-88K之间。实验的总体结论是:扩增定律也明显适用CLIP,当扩增模型,训练数据和算力时,模型在下游任务上有一致性的提升。但是不同的训练数据集表现出不同的扩增系数:OpenCLIP的模型(基于LAION-2B数据集)在图文检索任务上有较大的扩增系数,而OpenAI CLIP模型(基于私有的WebImageText 400M数据集)在zero-shot分类任务上有较强的扩增系数。这个结论和FLIP的结论比较吻合,这说明训练数据集对CLIP的性能确实有比较大的影响。用论文结论的一句话来说就是:Scaling behavior depends on task type and pre-training dataset。更多内容可见论文:https://arxiv.org/abs/2212.07143
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”




 下载APP
下载APP