
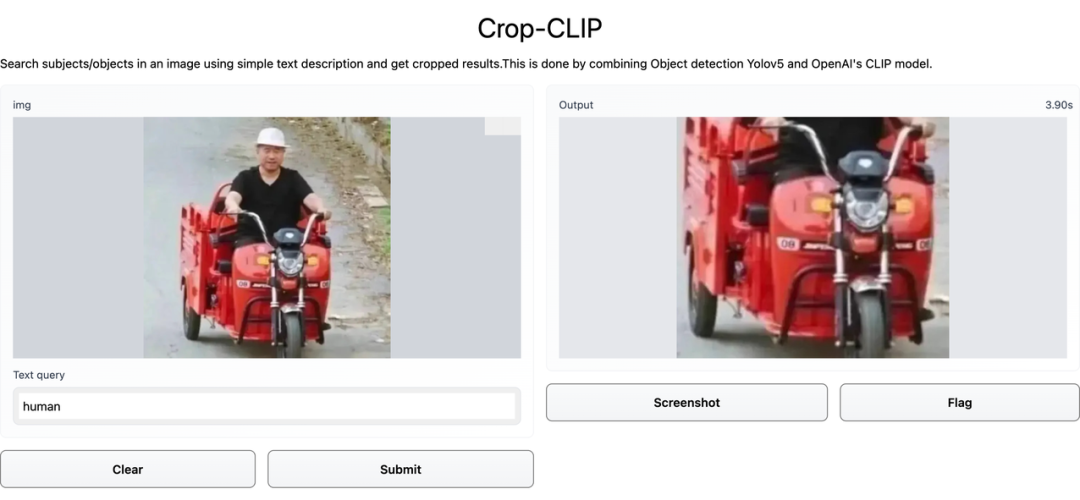
YOLOv5 + CLIP = 搜图 + 裁剪
给 Crop-CLIP 一个口令,就能自动搜图,还能帮忙裁剪出图片中的关键部分。

项目地址:https://github.com/vijishmadhavan/Crop-CLIP
在线试用地址:https://huggingface.co/spaces/Vijish/Crop-CLIP
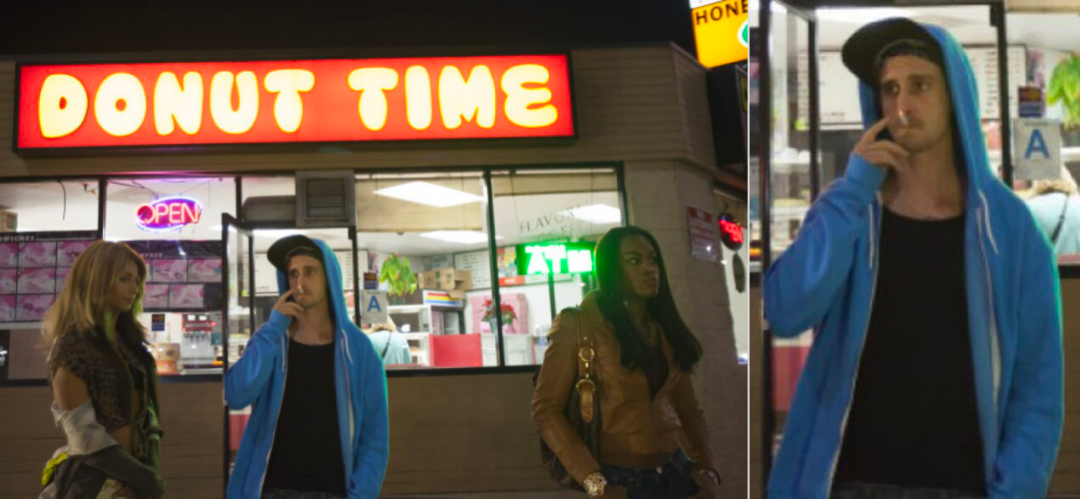

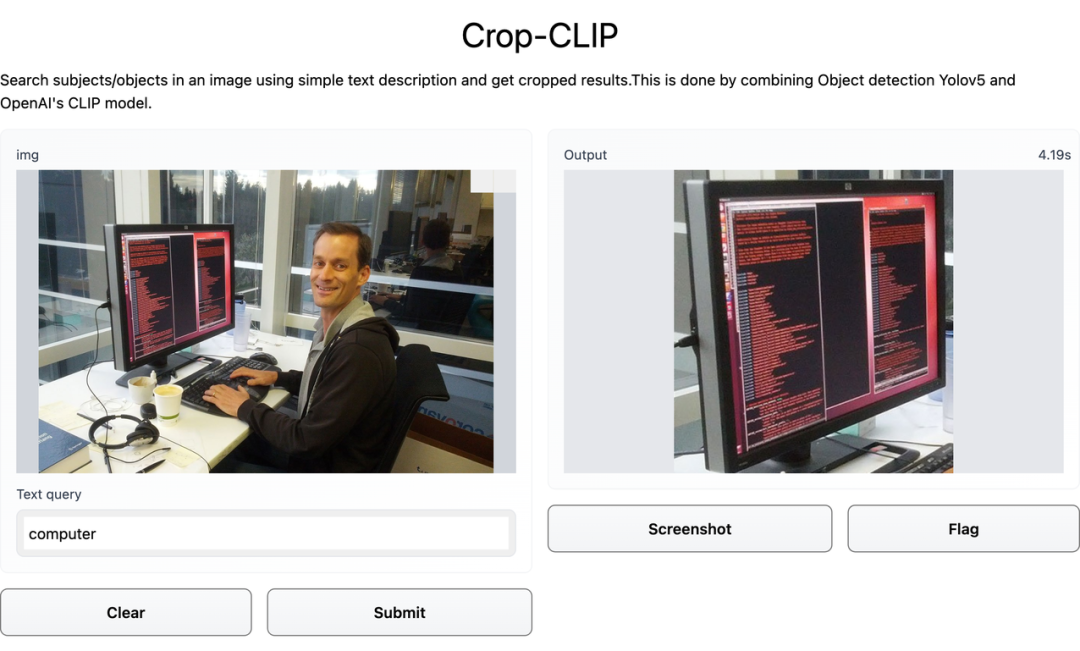
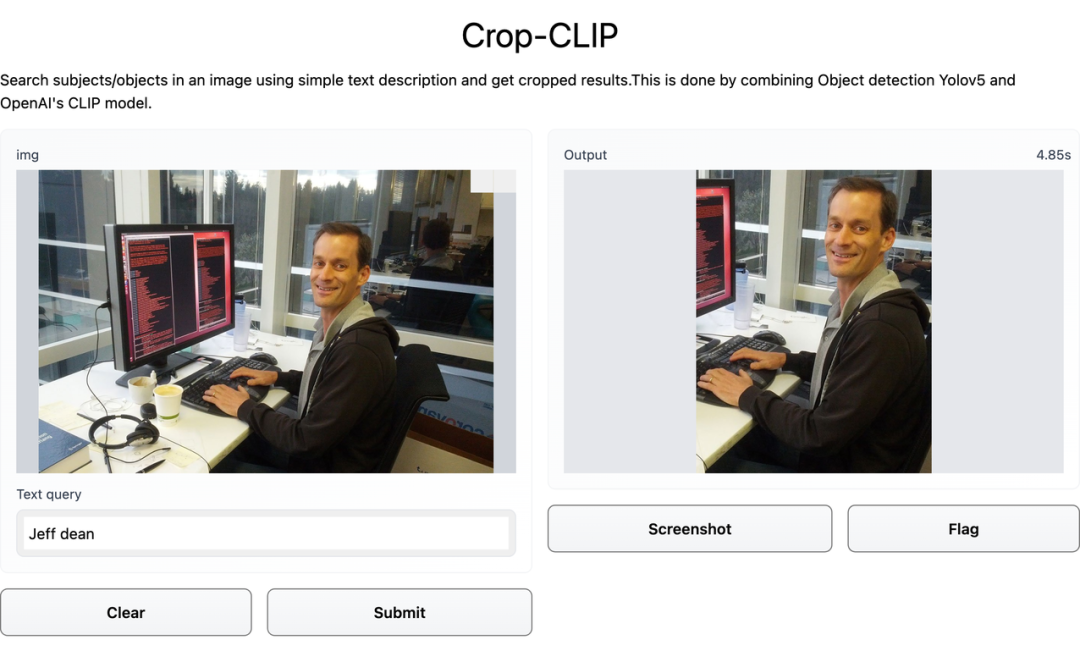
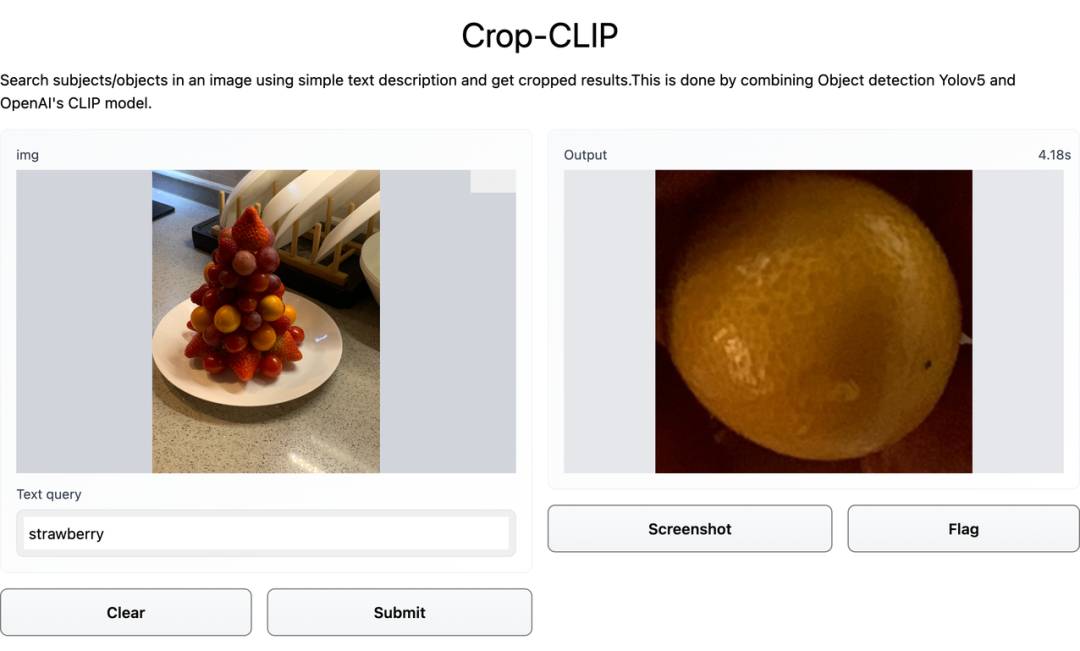
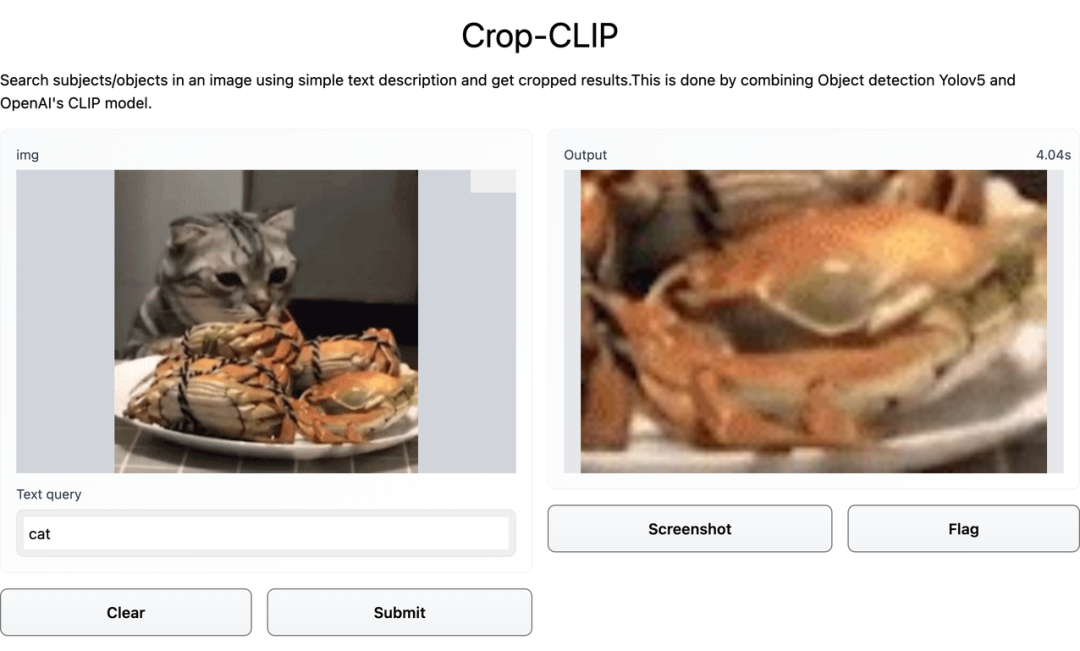
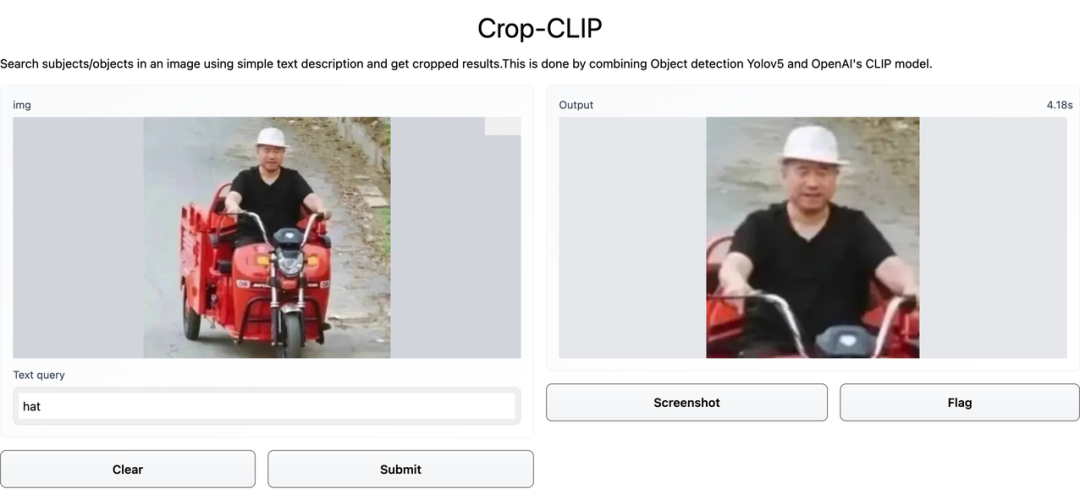
检测和裁剪对象 (yolov5s)
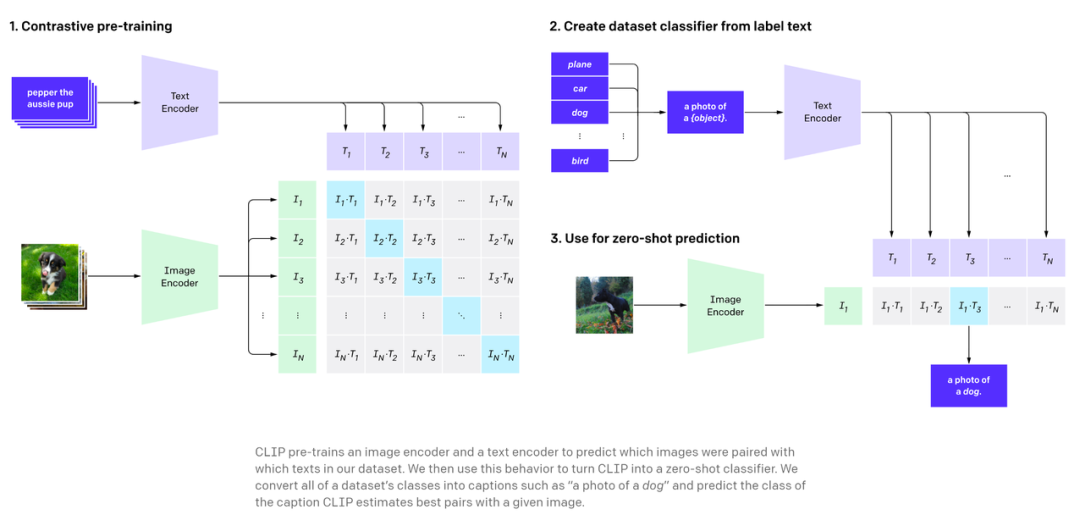
使用 CLIP 对裁剪后的图像进行编码
使用 CLIP 编码搜索查询
找到最佳匹配部分

© THE END
转载请联系机器之心获得授权
猜您喜欢:
附下载 |《TensorFlow 2.0 深度学习算法实战》
评论