点击上方“机器学习与生成对抗网络”,关注星标

新智元 来源:berkeley 编辑:好困
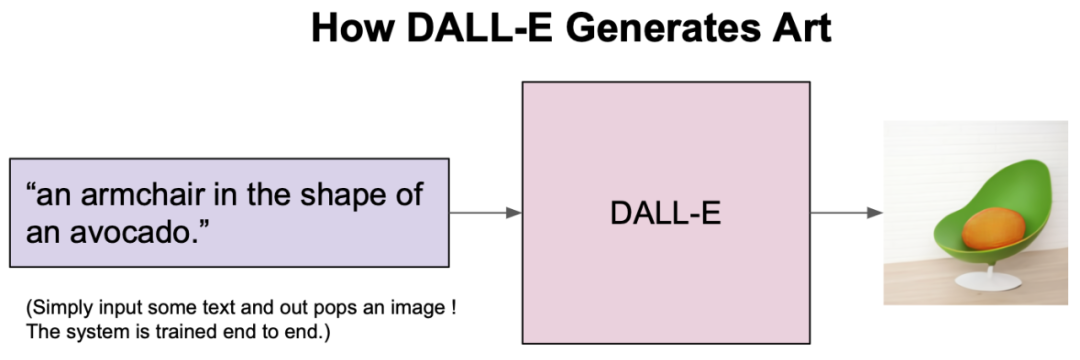
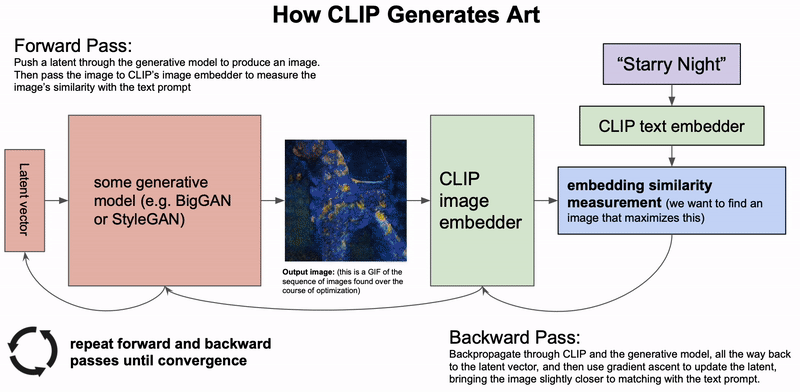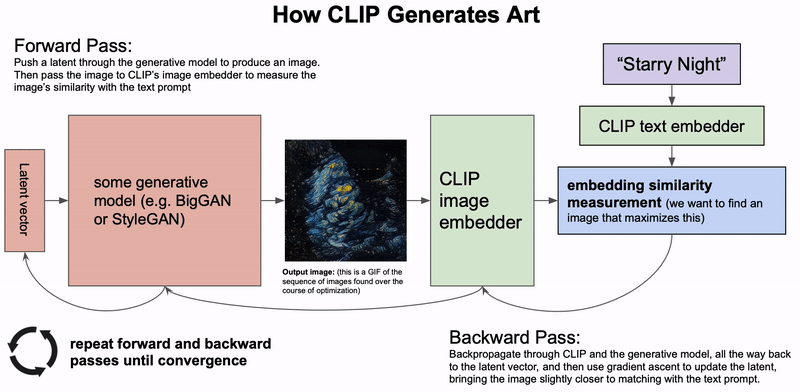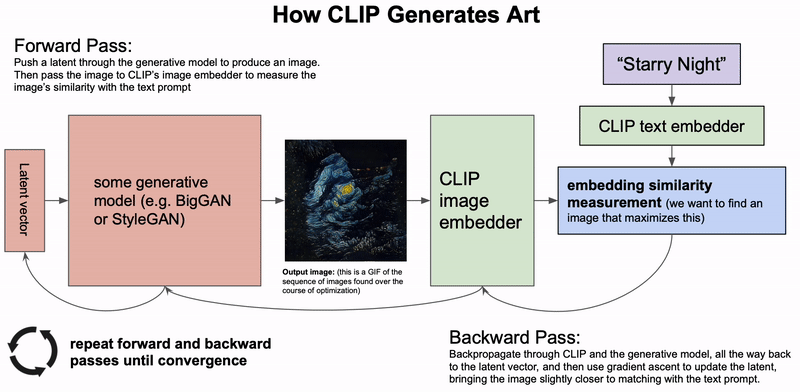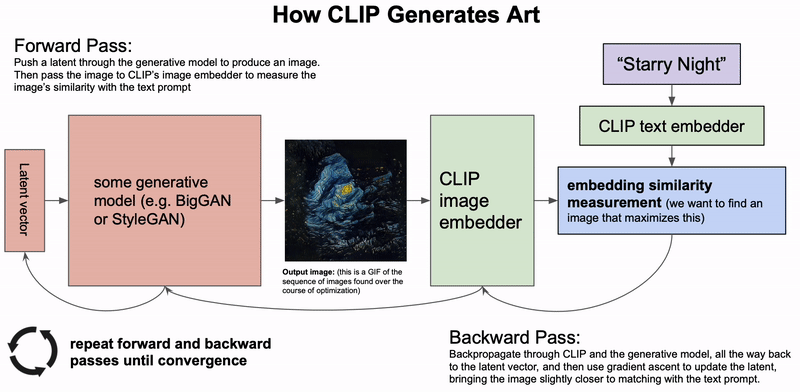
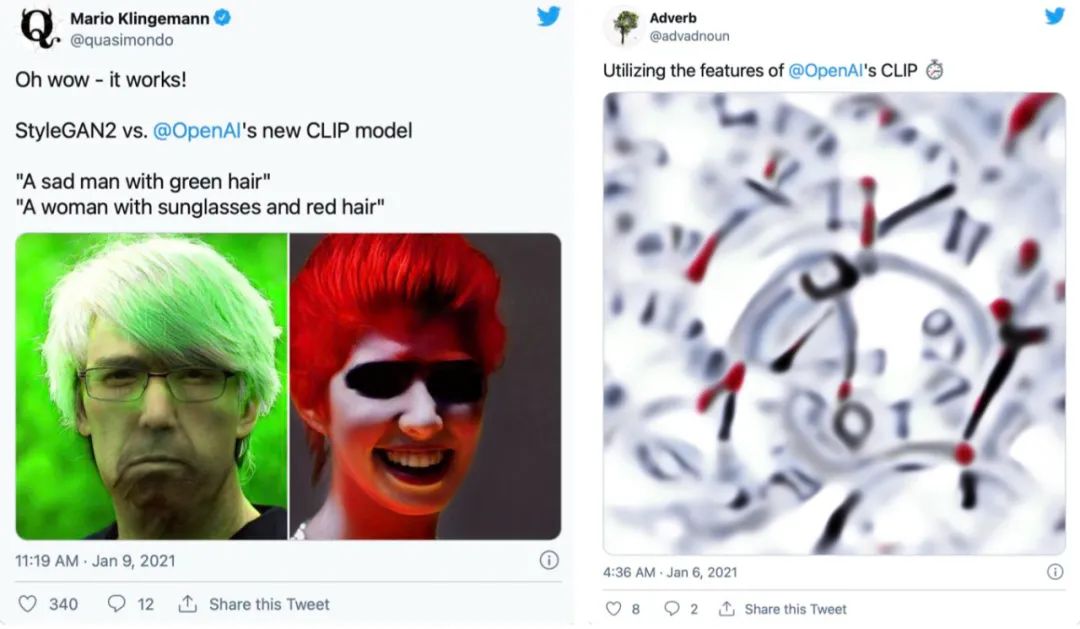
最近几个月,AI生成艺术领域的发展如同雨后春笋一般。自从OpenAI开源了CLIP模型的权重和代码之后,网友们就开始利用它去创造各种有趣的视觉艺术。而CLIP模型创造力是如此之强,仅根据这些短短的文字,就能以不可思议的抽象风格将它们呈现出来。而你,并不会知道出现的会是什么:可能是迷幻的伪现实场景,或者是更加抽象的东西。例如,输入 「夜晚的城市景观」,就会生成这种很酷、很抽象的画面。CLIP也可以用来生成短的动画,例如这个「星空」。自然语言输入是一个完全开放的沙盒,如果能按照模型的喜好使用文字,你几乎可以创造任何东西。在概念上,这种从文本描述生成图像的想法与OpenAI的DALL-E模型惊人地相似。但实际上却完全不同。DALL-E是直接从语言中产生高质量的图像而进行的端到端训练,而CLIP则是使用语言来引导现有的无条件图像生成模型。不过,这些基于CLIP的方法要相对拙略一些,所以输出的结果并不像DALL-E那样具有很高质量和精确度。相反,这些生成的图像是怪异、迷幻和抽象的。正是这种怪异使这些基于CLIP的作品如此独特,让人在熟悉的事物上看到完全不同的结果。「牛油果形状的扶手椅」:上图由DALL-E生成,下图由CLIP生成的2021年1月5日,OpenAI开源了CLIP:一个用来给图像进行标注的模型。在数以亿计的图像中学习之后,CLIP不仅在给图像挑选最佳的标注方面变得相当熟练,而且在分类方面还展示出了比以往任何模型都更强大的鲁棒性。除此以外,CLIP还学会了抽象的视觉表征,在某种程度上这还是第一次。但很显然,没有任何迹象表明CLIP还能在生成艺术方面带来任何帮助。然而,网友们只花了一天时间就发现,通过一个简单的技巧,CLIP就可以用来指导现有的图像生成模型(如GANs、Autoencoders或像SIREN这样的隐式神经表征),输出基于给定文字描述的图像。其中,CLIP在生成模型的潜在空间进行搜索,从而找到与给定的文字描述相匹配的潜在图像。不过,在短短的几周之后就有了突破性进展,advadnoun发布并开源了Big Sleep的代码:一种基于CLIP并使用Big GAN作为生成模型的文本到图像技术。有趣的是,模型的名字起源于一部超现实主义的黑色电影The Big Sleep。The Big Sleep以其独特的方式,几乎可以呈现任何能用文字表达的东西。在一切的尽头,摇摇欲坠的建筑和刺破天空的武器——The Big Sleep看到这些作品,也就不难想象为何网友给出一个富有「哲学」的观点了:你可以把CLIP的输出看作是单纯的统计平均数的产物:计算语言和视觉之间的相关性的结果,因为它们存在于互联网上。因此,从这个角度来看,CLIP的输出更像是在窥视时代潮流,并把事情看成是类似于 「互联网的统计平均值」。
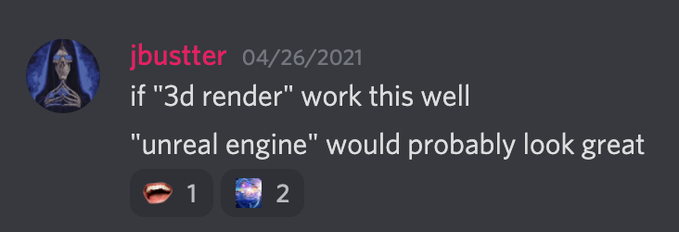
2020年12月17日,海德堡大学的研究人员发表了他们的论文「Taming Transformers for High-Resolution Image Synthesis」,提出了一种新的GAN架构:VQ-GAN。VQ-GAN将conv-nets和transformers结合在一起,并充分地利用了conv-nets在局部感应偏差和transformers在全局注意力上的优势。在四月初,advadnoun和RiversHaveWings开始把VQ-GAN和CLIP结合到一起,尝试从文本提示中生成图像。新的方法与The Big Sleep基本相同,只不过原本的生成模型Big-GAN,变成了VQ-GAN。VQ-GAN+CLIP的输出看起来不像是The Big Sleep那样的绘画,而更像一个雕塑。这个结果有些出乎意料,只是把生成模型从Big-Gan换成VQ-Gan,就能获得一个全新风格的「艺术家」。当然,这也从侧面说明了CLIP的通用性:可以插入任何一个生成模型,并在之后产生具有全新风格和形式的艺术。除了可以切换生成模型来改变输出的风格以外,还有一个更简单的技巧可以做到这一点。只需要添加一些特定的关键词到文字提示中,CLIP就能对输出的图像做出相应地修改——以它所「理解」的方式。这其中最有吸引力的一个技巧就是:「虚幻引擎技巧」。其中,虚幻引擎是一个由Epic Games开发的3D创作渲染工具。网友jbustter发现,如果在文字提示中加入 「在虚幻引擎中渲染」,输出结果看起来会更真实。CLIP似乎学习了很多被标记为「用虚幻引擎渲染」的电脑游戏图片,因此,通过在文字提示中加入这一点,就能有效地激励了模型去「复现」那些由虚幻引擎渲染的图像。一个神奇的童话屋,虚幻引擎——VQ-GAN+CLIP在某种程度上,虚幻引擎的技巧是一种突破。它使人们认识到在提示中添加关键词可以有多大的效果。于是,有越来越多复杂的提示被使用,用来尽可能地提取最高质量的输出。「山顶附近暴风雪中的小木屋,黄昏时分打开一盏灯 | artstation | 虚幻引擎」——VQ-GAN+CLIP「山顶上的房子在午夜时分的哑光画,小萤火虫在周围飞来飞去,是吉卜力工作室的风格 | artstation | 虚幻引擎」——VQ-GAN+CLIP这些看起来与之前VQ-GAN+CLIP生成的图像完全不同。它们看起来更像是经过编辑的照片或视频游戏的场景。根据这些关键词,模型将会输出风格各异的艺术作品,同时,随着生成模型的发展,也将会有更多更出色的作品产生。
参考资料:
https://ml.berkeley.edu/blog/posts/clip-art/?continueFlag=ae8c92b06679c71e74349cb040d81f29
猜您喜欢:
等你着陆!【GAN生成对抗网络】知识星球!
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
CVPR 2021 | 图像转换 今如何?几篇GAN论文
【CVPR 2021】通过GAN提升人脸识别的遗留难题
CVPR 2021生成对抗网络GAN部分论文汇总
经典GAN不得不读:StyleGAN
最新最全20篇!基于 StyleGAN 改进或应用相关论文
超100篇!CVPR 2020最全GAN论文梳理汇总!
附下载 | 《Python进阶》中文版
附下载 | 经典《Think Python》中文版
附下载 | 《Pytorch模型训练实用教程》
附下载 | 最新2020李沐《动手学深度学习》
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!
附下载 |《计算机视觉中的数学方法》分享