
实战 | 巧用位姿解算实现单目相机测距
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
在项目过程中,总遇到需要单目视觉给出目标测距信息的情况,其实单目相机本不适合测距,即使能给出,精度也有限,只能在有限制的条件下或者对精度要求很不高的情况下进行应用。该文结合SLAM方法,通过3D-2D解算相机位姿的方式给出一种另类的单目测距方法,行之有效。
1
相机模型
相机内参:是与相机自身特性相关的参数,比如相机的焦距、像素大小等; 相机外参:是在世界坐标系中的参数,比如相机的位置、旋转方向等。
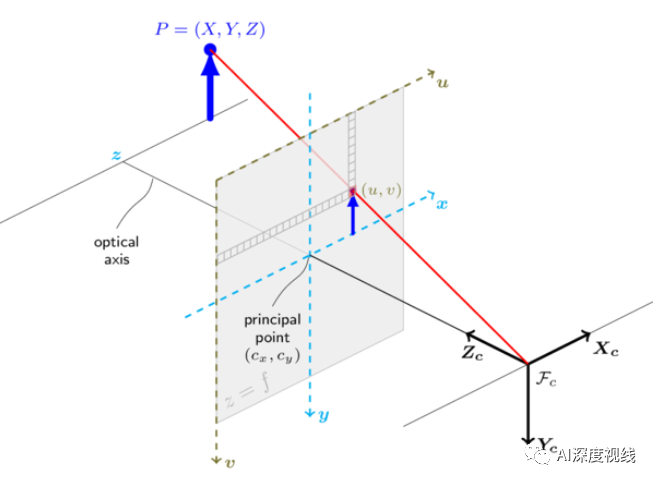

『world』——>『camera』
从世界坐标系到相机坐标系的,为刚体变换,反应了物体与相机的相对运动关系。
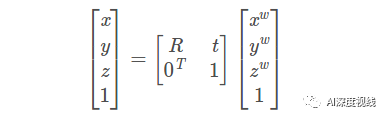
R为正交旋转矩阵,T为平移矩阵。共有6个自由度,三个轴的旋转角度(R)以及平移矩阵(T),这6个参数称为相机的外参(Extrinsic)
『camera』——>『image』
若将成像平面移动到,相机光心与物体之间
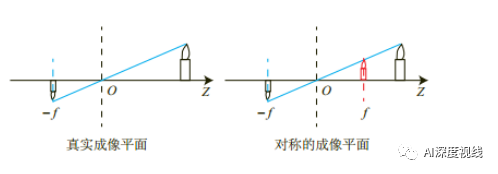
则从相机坐标系到图像坐标系的对应关系如下式所示:

从相机坐标系到图像坐标系的投影只和相机的焦距f有关,只有一个自由度f。
『image』——>『pixel』
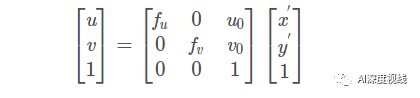
令dx、dy分别表示感光sensor 上每个点在象平面x和y方向上的物理尺寸,其中:

从图像平面到像素平面的变换有 4个自由度。
『world』——>『pixel』

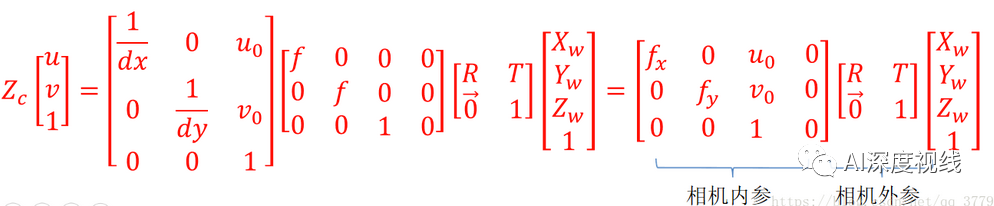
2
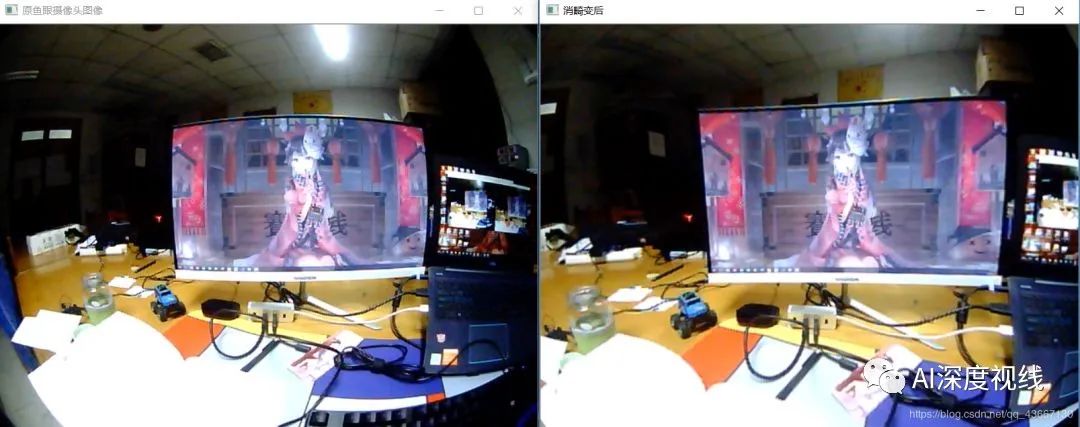
相机畸变
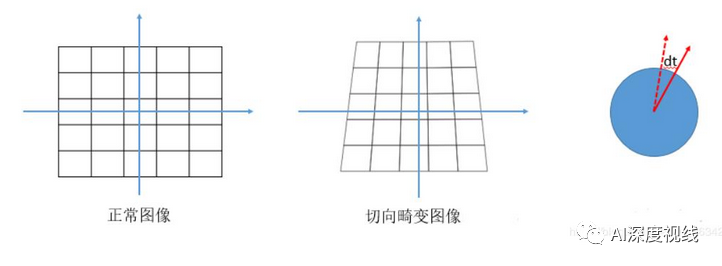
图像的畸变主要有两种:径向畸变和切向畸变。
径向畸变
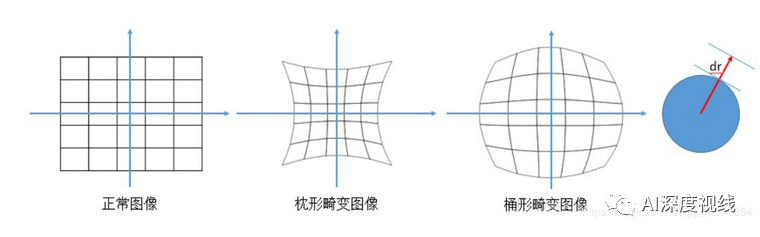
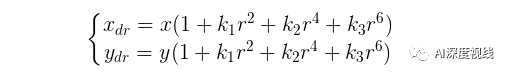
切向畸变
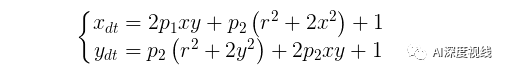
3
相机标定

2.角点检测
1、角点检测函数bool findChessboardCorners(InputArray image,Size patternSize,OutputArray corners,int flags=CALIB_CB_ADAPTIVE_THRESH+CALIB_CB_NORMALIZE_IMAGE);// image:传入拍摄的棋盘图Mat图像,必须是8位的灰度或者彩色图像// patternSize:每个棋盘图上内角点的行列数,一般情况下,行列数不要相同,便于后续标定程序识别标定板的方向;// corners:用于存储检测到的内角点图像坐标位置,一般用元素是Point2f的向量来表示:vector<Point2f> image_points_buf;// flage:用于定义棋盘图上内角点查找的不同处理方式,有默认值。
2、提取亚像素角点信息专门用来获取棋盘图上内角点的精确位置,降低相机标定偏差,还可以使用cornerSubPix函数bool find4QuadCornerSubpix(InputArray img,InputOutputArray corners,Size region_size);// img:输入的Mat矩阵,最好是8位灰度图像,检测效率更高// corners:初始的角点坐标向量,同时作为亚像素坐标位置的输出vector<Point2f> iamgePointsBuf;// region_size:角点搜索窗口的尺寸
3.参数标定
3、相机标定double calibrateCamera( InputArrayOfArrays objectPoints,InputArrayOfArrays imagePoints,Size imageSize,CV_OUT InputOutputArray cameraMatrix,CV_OUT InputOutputArray distCoeffs,OutputArrayOfArrays rvecs,OutputArrayOfArrays tvecs,int flags=0,TermCriteria criteria = TermCriteria(TermCriteria::COUNT+TermCriteria::EPS, 30, DBL_EPSILON));// objectPoints:世界坐标系中的三维点,三维坐标点的向量的向量vector<vector<Point3f>> object_points// imagePoints:每一个内角点对应的图像坐标点,vector<vector<Point2f>> image_points_seq形式// imageSize:图像的像素尺寸大小(列数=cols,行数=rows)(宽度=width,高度=height)// cameraMatrix:相机的3*3内参矩阵,Mat cameraMatrix=Mat(3,3,CV_32FC1,Scalar::all(0));// distCoeffs:1*5畸变矩阵,Mat distCoeffs=Mat(1,5,CV_32FC1,Scalar::all(0))// rvecs:旋转向量,输入一个Mat类型的vector,即vector<Mat>rvecs;// tvecs:位移向量,和rvecs一样,应该为vector<Mat> tvecs;// flags:标定时所采用的算法// criteria:最优迭代终止条件设定
4
单目测距
核心思想:通过SLAM中3D-2D相机位姿估计(PnP)来实现单目测距
PnP(Perspective-n-Point)描述了当知道n个3D空间点及其投影位置时,如何估计相机的位姿。对应到SLAM问题上,在初始化完成后,前一帧图像的特征点都已经被三角化,即已经知道了这些点的3D位置。那么新的帧到来后,通过图像匹配就可以得到与那些3D点相对应的2D点,再根据这些3D-2D的对应关系,利用PnP算法解出当前帧的相机位姿。
PnP问题有多种求解方法,包括P3P、直接线性变换(DLT)、EPnP(Efficient PnP)、UPnP等等,而且它们在OpenCV中都有提供。
问题是:我们在实际应用中,无法知道相机拍到的物体的3D空间点坐标?!
void solvePnP(InputArray objectPoints, InputArray imagePoints, InputArray cameraMatrix, InputArray distCoeffs, OutputArray rvec, OutputArray tvec, bool useExtrinsicGuess=false, int flags = CV_ITERATIVE)Parameters:objectPoints - 世界坐标系下的控制点的坐标,vector<Point3f>的数据类型在这里可以使用imagePoints - 在图像坐标系下对应的控制点的坐标。vector<Point2f>在这里可以使用cameraMatrix - 相机的内参矩阵distCoeffs - 相机的畸变系数以上两个参数通过相机标定可以得到。相机的内参数的标定参见:http://www.cnblogs.com/star91/p/6012425.htmlrvec - 输出的旋转向量。使坐标点从世界坐标系旋转到相机坐标系tvec - 输出的平移向量。使坐标点从世界坐标系平移到相机坐标系flags - 默认使用CV_ITERATIV迭代法
下面给出一个求解单目测距的可调用类PnPDistance()的简单测试代码样例,如下所示:
# -*-coding:utf-8-*-import cv2import numpy as npclass PnPDistance():def __init__(self, args):self.category = args.classes_namesself.cam = np.array([1.5880436204354560e+03, 0., 960., 0., 1.5880436204354560e+03,600., 0., 0., 1.], dtype=np.float64).reshape((3, 3))self.distortion = np.array([-1.8580303062080919e-01, 5.7927645928450899e-01,5.5271164249844681e-03, -1.2684978794253729e-04,-5.6884229185639223e-01], dtype=np.float64).reshape((1, 5))self.obj_true_size = [[180, 180], [250, 250], [170, 45], [100, 150], [250, 180],[100, 150], [2000, 1000], [170, 45], [200, 100],[110, 48], [110, 48], [110, 48], [110, 48],[110, 48], [40, 105], [40, 105], [40, 105], [80, 30],[80, 30], [80, 30], [80, 30], [80, 30], [80, 30], [80, 30], [80, 30], [80, 30], [70, 35], [45, 45]]def get_distance(self, obj_dict):""":param bbox: x,y,w,h:param category: category:return:"""# boxes = []# categories = []out_dist = []out_dist_size = []for keys, items in obj_dict.items():left, top, right, bottom = items['bbox']bbox = [left, top, right-left, bottom-top]category = self.category.index(items['label'].split(' ')[0])# boxes.append(bbox)# categories.append(category)obj_pw, obj_ph = self.obj_true_size[category]if obj_pw < obj_ph:obj_pw = obj_phelse:obj_ph = obj_pwobj_p = np.array([(0, 0, 0),(obj_pw, 0, 0),(obj_pw, obj_ph, 0),(0, obj_ph, 0)],dtype=np.float64).reshape((1, 4, 3))img_rect_w, img_rect_h = bbox[2], bbox[3]if img_rect_w < img_rect_h:img_rect_w = img_rect_helse:img_rect_h = img_rect_wimg_points = np.array([(bbox[0], bbox[1]),(bbox[0] + img_rect_w, bbox[1]),(bbox[0] + img_rect_w, bbox[1] + img_rect_h),(bbox[0] + img_rect_w, bbox[1])],dtype=np.float64).reshape((1, 4, 2))ret_val, r_vec, t_vec = cv2.solvePnP(obj_p, img_points, self.cam, self.distortion,useExtrinsicGuess=False,flags=cv2.SOLVEPNP_AP3P)out_dist.append([round(t_vec[0][0] / 100.0, 1), round(t_vec[2][0] / 100.0, 1)])out_dist_size.append(self.obj_true_size[category])return out_dist, out_dist_size

参考链接:
https://www.pianshen.com/article/5864313789/
https://blog.csdn.net/u011144848/article/details/90605108
如有侵权,联系删除
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~