
超越SOLO V2| ISTR:基于Transformer的端到端实例分割(文末获取论文与源码)
点击上方【AI人工智能初学者】,选择【星标】公众号
期待您我的相遇与进步

ISTR:实例分割Transformer,首次验证了Transformer在端到端实例分割中的潜力,表现SOTA!性能优于Sparse R-CNN、SOLOv2等网络,代码已经开源!
作者单位:厦门大学(纪荣嵘团队), Pinterest, 腾讯优图, IIAI
1 简介
在本文中提出了一种称为ISTR的实例分割Transformer,它是首个基于Transformer的端到端框架。ISTR通过预测低维Mask嵌入,并将其与Ground-Truth Mask嵌入进行匹配以得到Set Loss。此外,ISTR同时使用循环细化策略进行检测和分割,与现有的自上而下和自下而上的框架相比,它提供了一种实现实例分割的新方法。
得益于所提出的端到端机制,即使使用基于近似的次优嵌入,ISTR仍能展示出最先进的性能。具体而言,ISTR在MS COCO数据集上使用ResNet50-FPN获得46.8/38.6box/maskAP,并使用ResNet101-FPN获得48.1/39.9 box/mask AP。
2 所提方法
2.1 Mask Embeddings
为了提供一个有效提取Mask Embeddings的公式,作者对原始和重构Mask之间的互信息进行了约束:
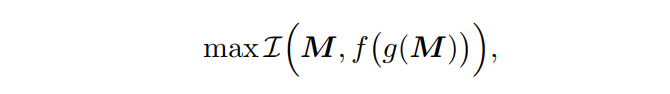
其中,
为2个随机变量之间的互信息,M为Mask集合,
为用于提取嵌入的Mask编码器,
为用于重建Mask的解码器,上式保证了编码和解码阶段的信息损失最小,这隐含用嵌入表征Mask。推导后可以得到Mask Embeddings的广义目标函数:
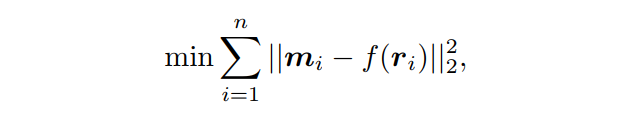
式中,
为Mask Embeddings,
为L2-norm,通过使用矩阵(
)对编码器和解码器进行简单的线性变换,最终目标函数可以表达为:
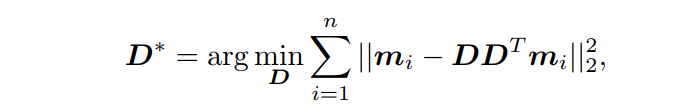
式中,l为Mask Embeddings的维数,
为
单位矩阵。上式与PCA的目标函数有相同的公式,它提供了一个closed-form solution来学习transformation。
2.2 Matching Cost and Prediction Loss
在得到Mask Embeddings的编码器和解码器后,本文还定义了端到端实例分割的bipartite matching cost和prediction loss。将Ground truth bounding boxes, classes和masks表示为
。predicted bounding boxes, classes和mask embeddings表示为,其中
2.2.1 Bipartite Matching Cost
对于Bipartite Matching,以最小代价寻找n个非重复整数
的排列,如:
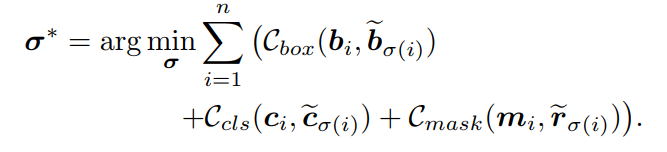
将bounding boxes的matching cost定义为:
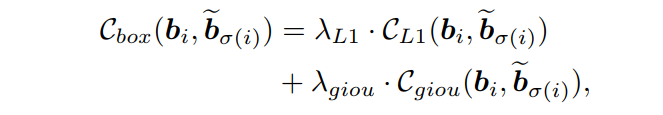
class的matching cost为:
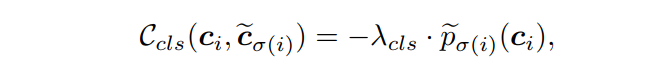
其中
表示平衡cost的超参数,
表示L1成本,
表示generalized IoU cost,
是类
的概率。
这里不再直接匹配高维mask,而是使用mask embeddings之间的相似性度量来匹配它们,定义为:
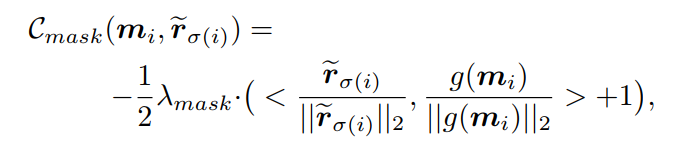
其中mask embeddings L2归一化,2个归一化向量之间的点积用于计算余弦相似度。结果加上1,然后除以2保证取值范围在[0,1]之间。
2.2.2 Set Prediction Loss
对于set prediction loss使用匹配预测回归mask ground truth。set prediction loss定义为:
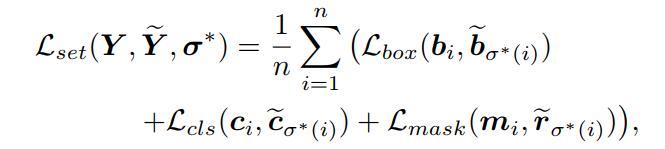
定义与
相同,
为用于分类的Focal loss。对于masks,加入dice loss来改进学习到的嵌入以重构mask。mask loss定义为:
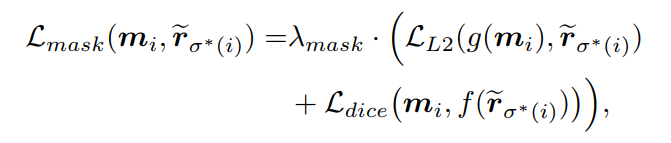
为L2 loss,
表示dice loss。
2.3 Instance Segmentation Transformer
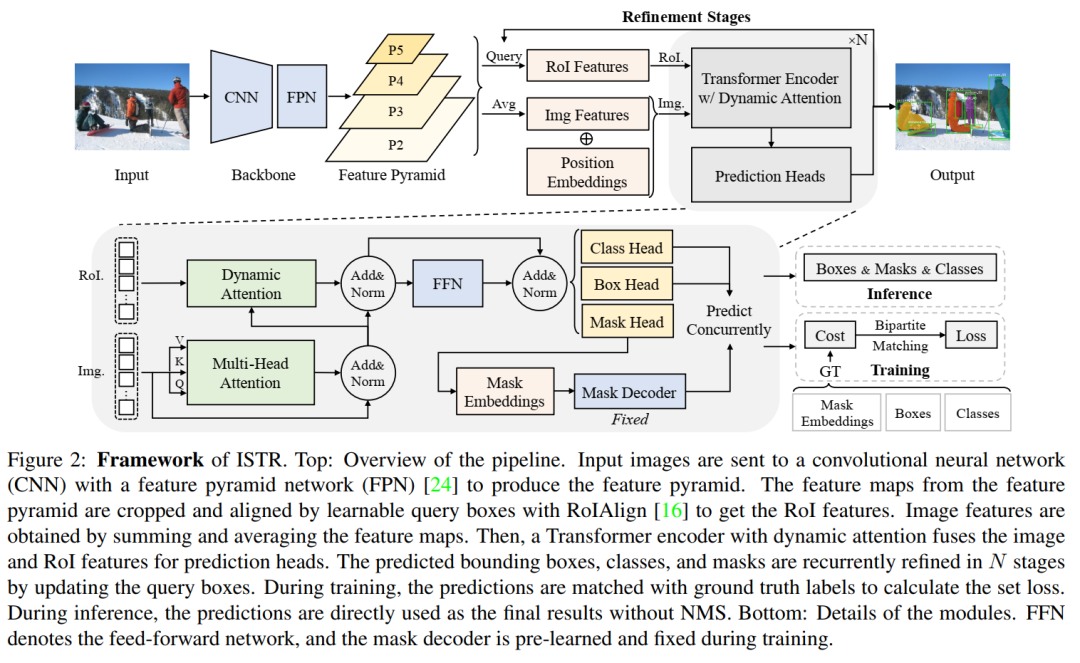
图2 Framework of ISTR
ISTR的结构如图2所示。它包含4个主要组件:
CNN backbone with FPN 用于提取每个实例的特征;
a Transformer encoder with dynamic attention,用于学习物体之间的关系;
a set of prediction heads,用于同时进行检测和分割;
N-step recurrent update用于细化预测集。
2.3.1 Backbone
对于ROI特征: 首先,这里使用一个带有FPN的CNN Backbone来提取特征金字塔的P2到P5级的特征。
然后,利用初始化k个可学习query boxes
覆盖整个图像的,通过RoIAlign提取k个RoI特征
。
对于Image特征:对P2到P5的特征进行平均求和,提取图像特征
,
2.3.2 Transformer Encoder and Dynamic Attention
首先对图像特征和位置嵌入的和进行3个可学习权矩阵的变换,得到输入
;
;
,self-attention模块定义为:
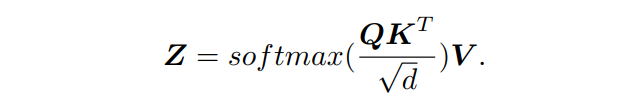
multi-head attention包括多个self-attention块,例如最初的Transformer中的8个用来封装不同特性之间的多个复杂关系。为了更好地融合RoI和图像特征增加了dynamic attention模块,定义为第
步中对RoI特征
的关注:
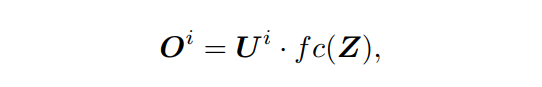
其中
为全连接层,用来生成dynamic parameters。然后在预测头中使用获得的特征
来产生输出。
2.3.3 Prediction Heads
预测由Prediction Heads计算得到,包括class head, box head, mask head以及fixed mask decoder。
box head:预测归一化中心坐标、高度和宽度的残差值,用于在第i步中更新query boxes
,
class head:使用softmax函数预测类。
mask head:输出掩模嵌入,然后使用预先学习的mask decoder重建以预测mask。
2.3.4 Recurrent Refinement Strategy
query boxes
被预测框周期性地更新,这改进了预测并使同时处理检测和分割成为可能。整个过程如下:

3 Experiments
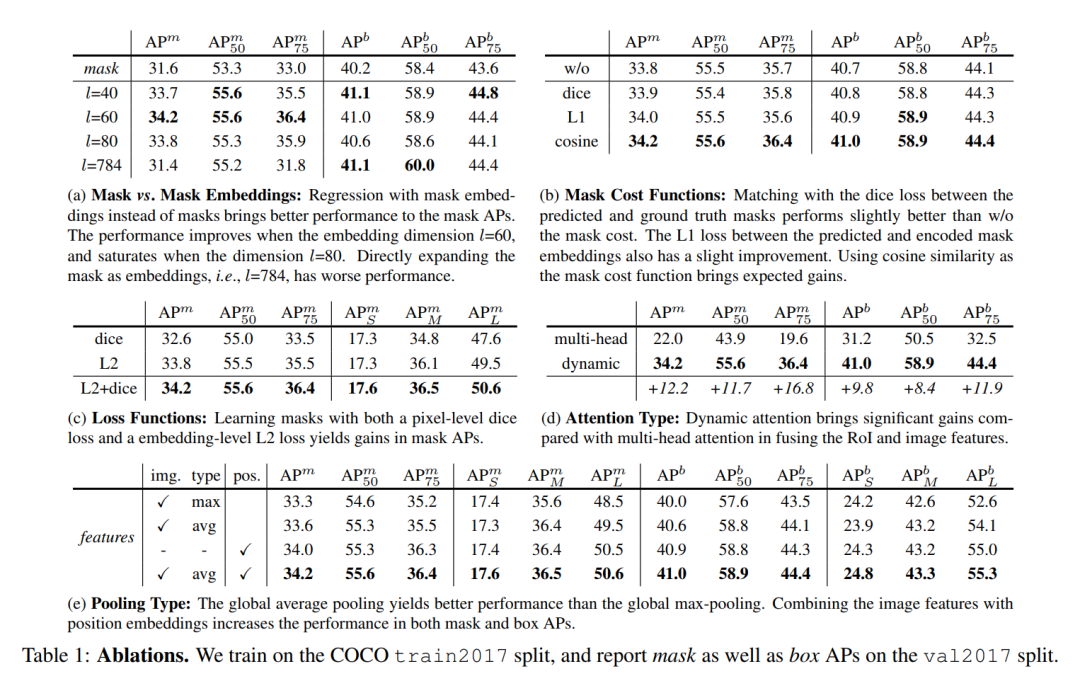
上表作者分别对于所设计的Mask embedding、Mask Cost Function、LossFunction以及Attention type进行了消融实验,各位老铁可以看出本文设计的有效性。
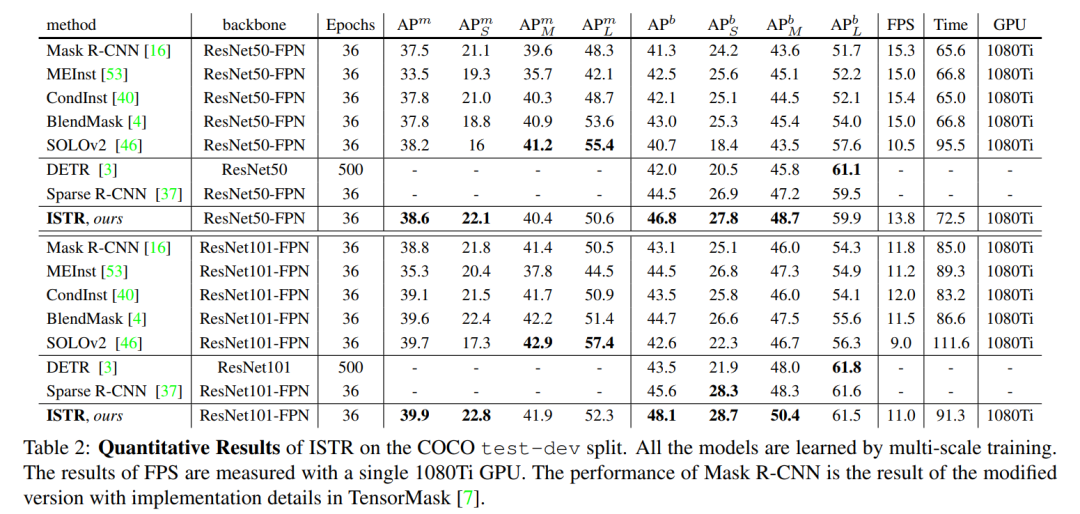
通过SOTA对比可以看出,在使用相同的Backbone的基础上,ISTR比Mask R-CNN、BlendMask、SOLO V2以及Sparse R-CNN都要好,同时推理时间并没有增加多少,确实是一个不错的工作。

4 参考
[1].ISTR: End-to-End Instance Segmentation with Transformers
[2].https://github.com/hujiecpp/ISTR
5 推荐阅读

CVPR2021 | 重新思考BiSeNet让语义分割模型速度起飞(文末获取论文)
YOLO在升级 | PP-YOLO v2开源致敬YOLOV4携带Tricks又准又快地归来(附论文与源码)
简单有效 | Transformer通过剪枝降低FLOPs以走向部署(文末获取论文)
又改ResNet | 重新思考ResNet:采用高阶方案的改进堆叠策略(附论文下载)
本文论文原文获取方式,扫描下方二维码
回复【ISTR】即可获取论文与源码
长按扫描下方二维码加入交流群
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【AI人工智能初学者】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!!!
点“在看”给我一朵小黄花呗![]()