
超快速的端到端实例分割模型,手把手教你用opencv部署Yolact

极市导读
作为ncnn推理框架里唯一一款做实例分割的模型,yolact也展现出了它的魅力,实现端到端一阶段完成实例分割且运行速度快。本文为作者上手编写的一套使用opencv部署YOLACT做实例分割的程序,程序包含C++和Python两种版本,附相关代码地址。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
YOLACT,全称为:You Only Look At CoefficienTs,从标题可以看出这个模型的名称有些致敬YOLO的意思。YOLACT是2019年ICCV会议论文,它是在现有的一阶段(one-stage)目标检测模型里添加掩模分支。而经典的mask-rcnn是两阶段实例分割模型是在faster-rcnn(两阶段目标检测模型)添加掩模分支,但是在YOLACT里没有feature roi pooling这个步骤。因而,YOLACT是一个单阶段实例分割模型。
起初,我是在知乎上看到YOLACT这个模型,文章里说它是端到端一阶段完成实例分割,而且运行速度快,并且YOLACT是ncnn(腾讯研发的手机端高性能神经网络前向计算框架)推理框架里唯一一款做实例分割的模型。于是我就想着编写一套程序,使用opencv 部署YOLACT来做实例分割,我把这套程序发布在github上,程序里包含C ++和Python两种版本的。
地址是:https://github.com/hpc203/yolact-opencv-dnn-cpp-python
关于 YOLACT,目前中文互联网上的资料多数是对原始论文的翻译总结。简单讲一下YOLACT的网络结构,如下图所示
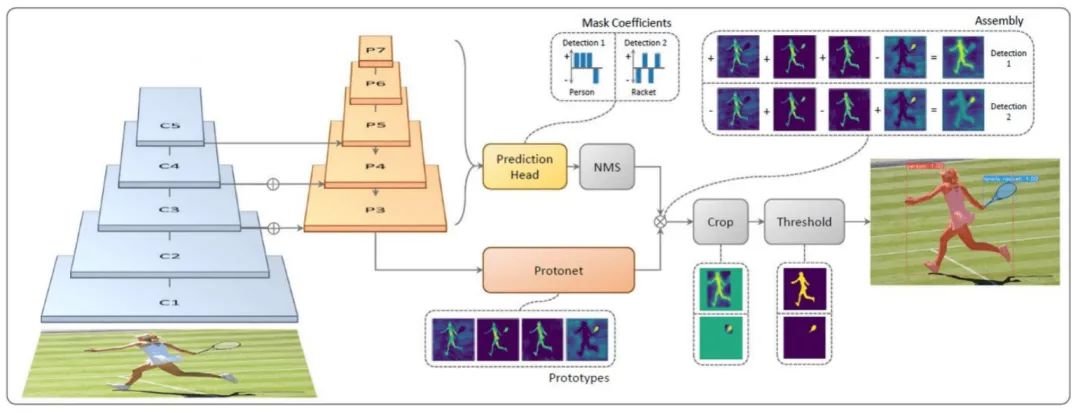
(1). P3~P7送入到Prediction Head分支生成各候选框的类别confidence、 location 和 prototype mask 的 coefficient;
(2). P3送入到Protonet 生成 k 个 prototype mask。在代码中 k = 32。Prototype mask 和 coefficients 的数量相等。
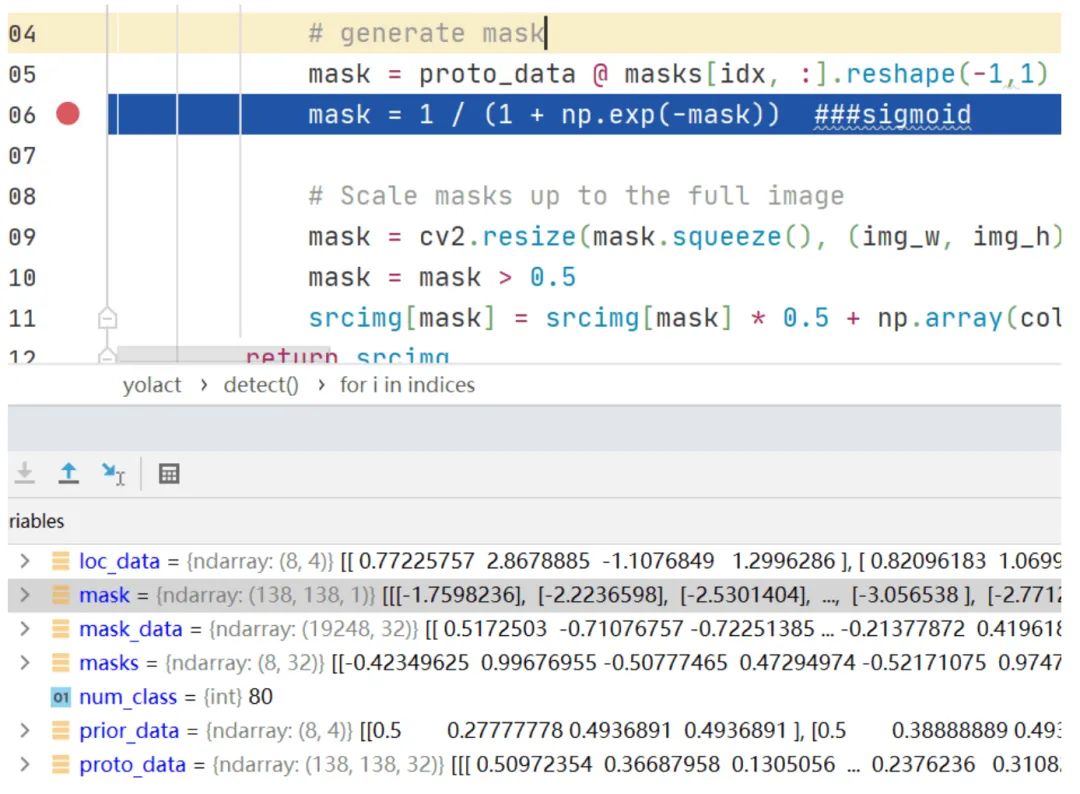
然后是后处理操作,得到最右边的带有检测框和mask染色的图片。下面我将结合编写的程序代码,对这个模型的后处理模块进行讲解。运行python程序,设断点查看网络输出,如下图所示

一共有5种尺度特征图,在特征图上的每个像素点会生成3种候选框。因此,最后会生成69693+35353+18183+993+553=19248(你可以在计算器里输入验证一下)个候选框。到这时你可以发现,虽然从名称上看YOLACT是致敬YOLO的,但是使用的是SSD的网络结构做目标检测的。
搞清楚了conf_preds的维度的意义后,就可以知道:
conf_preds的维度是(19428,81),表示它包含19428个候选框在80个类别的所有置信度。
loc_data的维度是(19428,4),表示它包含19428个候选框的坐标位置(中心点坐标(x,y),宽和高,加起来一共4个值)。
mask_data的维度是(19428,32),表示它包含19428个候选框的掩膜系数(Mask Coefficients)。
proto_data的维度是(138,138,32),它是原型掩膜,它对全部候选框是共享使用的,它与掩膜系数进行矩阵运算就可以得到最终实例掩膜。
在弄明白了这4个输出的意义后,接下来的事情就顺理成章的展开。首先求conf_preds里的每个候选框在80类里最大类别置信度,得到所属的类别和置信度,然后根据过滤掉低于置信度阈值的候选框,使用NMS过滤掉重叠的候选框,经过这两次过滤后剩下的候选框就是最终的目标检测框。这时候可以使用opencv函数在原图上画出目标检测框和所属类别以及置信度,接着就是计算这些目标检测框的实例掩膜。代码截图如下
代码里令人疑惑的是@符号,在百度搜索Python @,知乎里的回答是在python 3.5以后,@是一个操作符,表示矩阵-向量乘法。但是在代码里,@的左边proto_data是形状为(138,138,32)的三维矩阵,右边是形状为(32,1)的矩阵(或者说是列向量)。这时的矩阵计算原理是这样的,我在草稿纸上画图演示,如下图所示。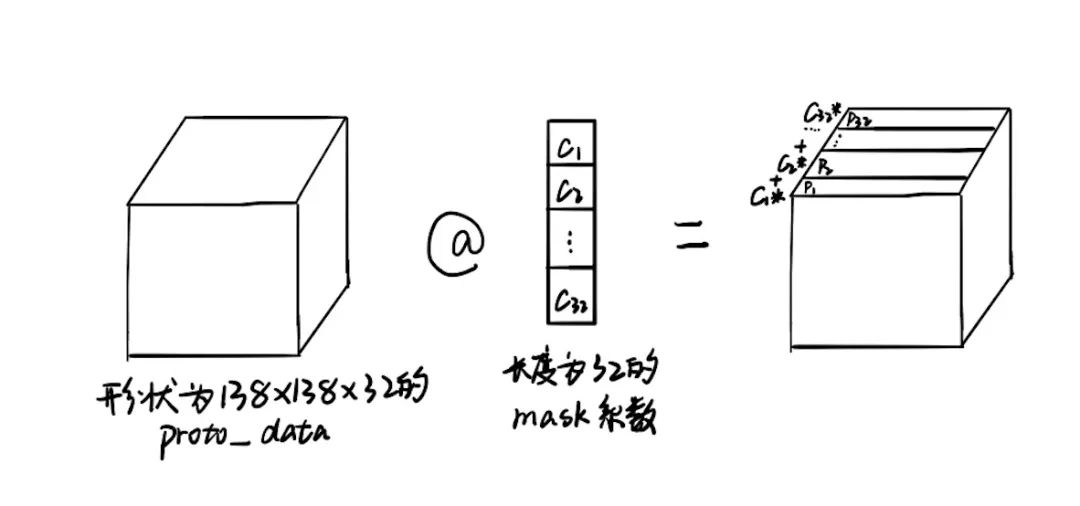 输入Proto_data里一个像素点沿着通道方向的数值,可以组成一个长度是32的向量,它与长度为32 的mask系数组成的向量,逐个元素相乘,最后求和得到的数值(这个过程可以说是向量内积)做为输出图上的相同位置的像素点的数值。
输入Proto_data里一个像素点沿着通道方向的数值,可以组成一个长度是32的向量,它与长度为32 的mask系数组成的向量,逐个元素相乘,最后求和得到的数值(这个过程可以说是向量内积)做为输出图上的相同位置的像素点的数值。
还可以这么理解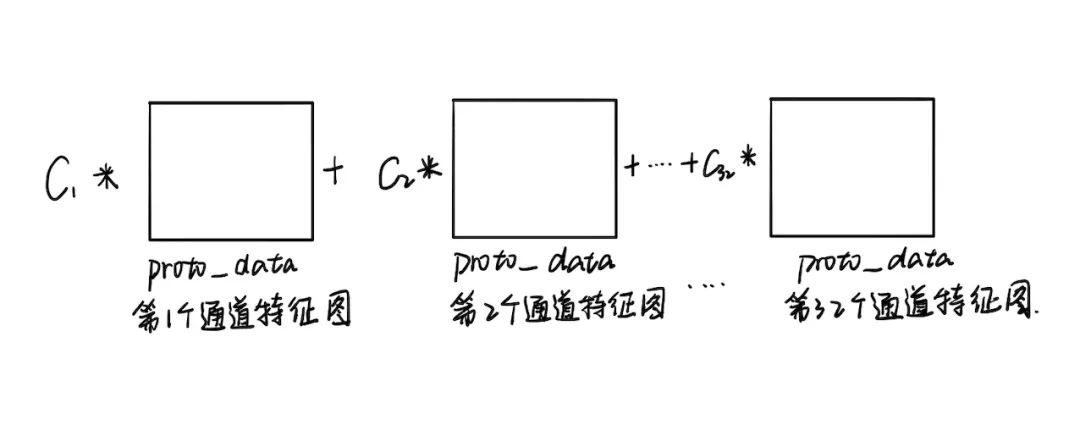 这时候得到138x138的矩阵特征图mask,接下来对它做sigmoid变换。然后把它resize到跟原图一样高宽大小,这时候的mask就是实例掩膜。接下来遍历mask里的每个像素点(x,y),如果mask里的像素点(x,y)的值大于0.5,那么就对原图上该像素点(x,y)的值做调整。调整方式是该像素点(x,y)的原始RGB值和目标类别的RGB值各取一半求和作为新的像素值。最后显示原图,就可以看到目标检测矩形框和类别置信度,还有目标实例染色。从COCO数据集里随机选取若干张图片测试效果。
这时候得到138x138的矩阵特征图mask,接下来对它做sigmoid变换。然后把它resize到跟原图一样高宽大小,这时候的mask就是实例掩膜。接下来遍历mask里的每个像素点(x,y),如果mask里的像素点(x,y)的值大于0.5,那么就对原图上该像素点(x,y)的值做调整。调整方式是该像素点(x,y)的原始RGB值和目标类别的RGB值各取一半求和作为新的像素值。最后显示原图,就可以看到目标检测矩形框和类别置信度,还有目标实例染色。从COCO数据集里随机选取若干张图片测试效果。
如下图所示,左边的图是使用opencv做yolact实例分割的可视化结果。右边的图是yolact官方代码(https://github.com/dbolya/yolact)的可视化结果。


2020-07-09

2020-07-30

2020-12-22


# 极市原创作者激励计划 #
