
腾讯优图提出ISTR:基于transformer的端到端实例分割!性能SOTA,代码已开源!
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
近日,厦门大学和腾讯优图联合发布了一种基于transformer的端到端的实例分割方法ISTR:

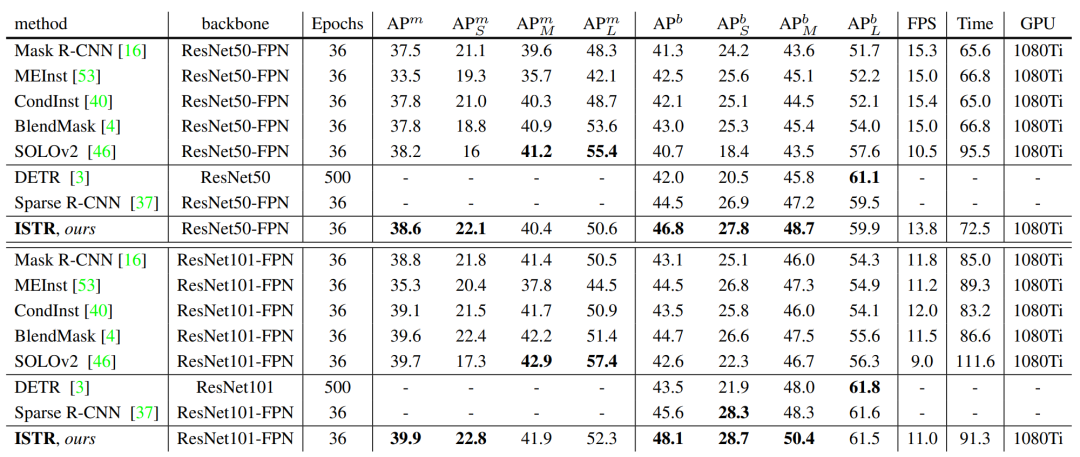
ISTR使用ResNet50-FPN在MS COCO数据集上可达到46.8/38.6 box/mask AP,使用ResNet101-FPN可达到48.1/39.9 box/mask AP。代码已经开源在:https://github.
com/hujiecpp/ISTR。在类似FPS下,ISTR模型效果超过Mask R-CNN和SOLOv2:
ISTR模型的主体网络结构如下所示,其主体思路借鉴了DETR和Sparse R-CNN,其中采用基于CNN的FPN网络作为backbone来作为特征提取器,然后定义一系列learnable query boxes,通过boxes的RoI Features和Img Features做attention,然后接三个heads来分别预测Class,Box和Mask。其训练的loss和DETR类似,采用Bipartite Matching Cost,只不过增加了mask loss部分。
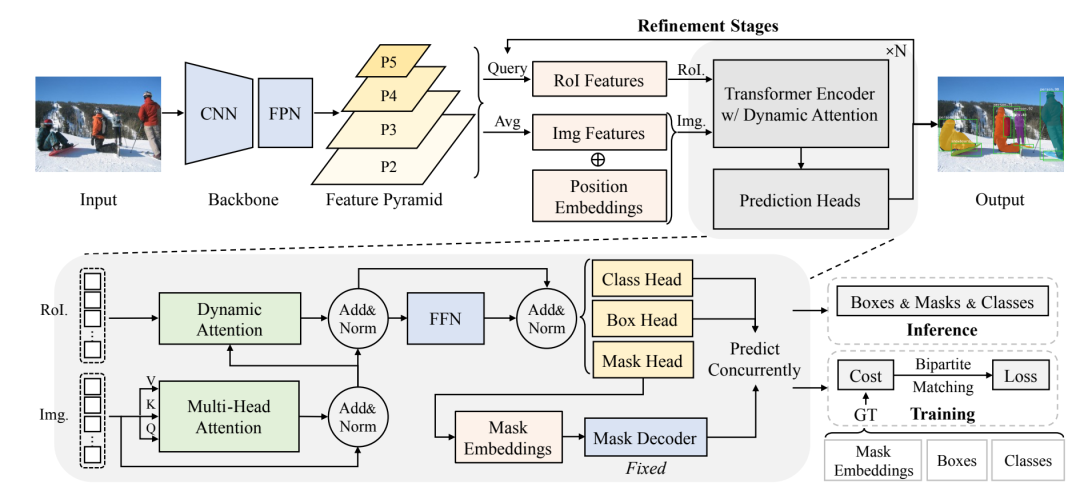
ISTR的训练和推理基本和Sparse R-CNN一样,因为ISTR也是采用了可学习的query boxes,训练也采用了Recurrent Refinement Strategy,区别主要在于增加了mask部分,主要流程如下:

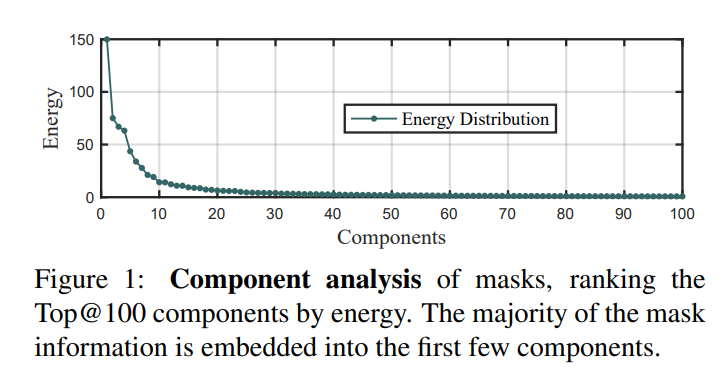
ISTR的核心点是mask head不是直接预测一个2-D的mask,而是预测的是一个mask embedding,具体做法是基于PCA对sxs大小的mask进行降维,得到维度为l的embedding vector,虽然看起来PCA可能会损失高维信息,实际上论文中发现mask的信息主要集中在前面的主成分中:
对于Bipartite Matching Cost,ISTR相比DETR就包括了三部分
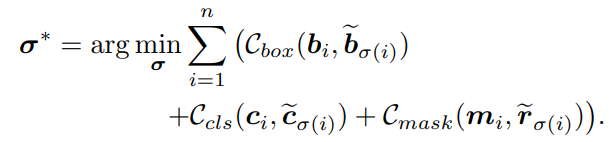
(1)matching cost for bounding boxes
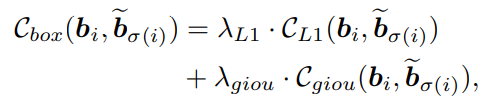
(2)matching cost for classes:
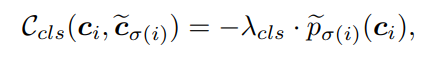
(3)matching cost for mask embedding:采用cos相似度来计算
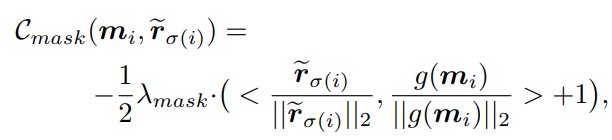
ISTR的训练loss也包括三个部分:
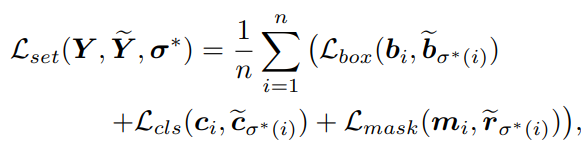
其中mask loss包括基于mask embeddings的L2 loss和基于2-D mask的dice loss:
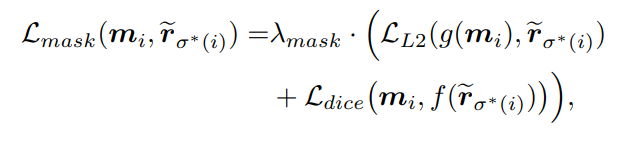
虽然ISTR的mask head是直接预测mask embeddings,但是从可视化的结果来看,生成的mask还是很精细的:

更多内容可以直接阅读论文:https://arxiv.org/pdf/2105.00637.pdf
推荐阅读
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
